



Whisper_Cloudflare is an open source project created by developer thun888 and hosted on GitHub. it is based on OpenAI's Whisper model, combined with the serverless architecture of Cloudflare Workers, provides efficient speech-to-text functionality. Users are able to do this by deploying a single worker.js The project supports multiple languages and audio formats, and is easy to use for developers to quickly build speech processing applications. The project supports multiple languages and audio formats, and is easy to use for developers to quickly build speech processing applications. The project is completely free, the code is publicly available, and there is no need to manage a server for deployment, so it is suitable for individuals or teams to deal with audio transcription and subtitle generation needs.
Function List
- Speech to text: convert audio files to text, support multi-language recognition.
- Subtitle Generation: Generate timestamped subtitle files in SRT format.
- Support multiple audio formats: compatible with MP3, WAV and other common audio formats.
- Serverless Deployment: Rapid deployment with Cloudflare Workers, requiring only
worker.jsDocumentation. - API Interface: Provides
/raw(raw transcription data) and/srt(subtitle file) two interfaces. - Voice Activity Detection (VAD): Support
vad_filterparameter to filter non-speech parts. - Context optimization: by
initial_prompt和prefixParameters to enhance transcription accuracy. - Translation Function: Support to translate audio content into specified language (e.g. English, Chinese, etc.).
Using Help
Deployment process
Deploying the Whisper_Cloudflare project requires only that the provided worker.js Code is copied to the Cloudflare Workers platform without cloning your entire GitHub repository. Here are the steps:
- Sign up for a Cloudflare account
Visit the Cloudflare website to sign up or log in to your account. Make sure the Workers feature is enabled (the free plan is fine). In the Cloudflare dashboard, go to the "Workers" page and click "Create Worker". - Create a worker and paste the code
- In the Workers editor, create a new worker (by default named
worker(or a customized name). - incoming
worker.jsThe code is copied and pasted into the editor, overriding the default code. - Save the code.
- In the Workers editor, create a new worker (by default named
- Install Wrangler (optional, for command line deployment)
If you wish to manage your workers from the command line, you will need to install Wrangler (the command line tool for Cloudflare Workers). Make sure Node.js is installed (recommended version 16.17.0 or higher) and run it:npm install -g wrangler - Configuring Wrangler and AI Bindings
- Run the following command to log in to Cloudflare:
wrangler login - Create or Edit
wrangler.tomlfile, add the following configuration:name = "whisper-cloudflare" compatibility_flags = ["nodejs_compat"] [ai] binding = "AI" - If you are not using Wrangler, you can manually bind the AI model in the Cloudflare dashboard's Worker settings (select the
@cf/openai/whisper-large-v3-turbo)。
- Run the following command to log in to Cloudflare:
- Deploying Workers
- In the Workers editor, click the "Deploy" button to publish the code directly.
- or run through Wrangler:
wrangler deploy - After a successful deployment, Cloudflare provides a Worker URL (e.g. https://whispercloudflare.tchepai.com/).
- Preparing Audio Files
Ensure that the audio is in MP3 or WAV format and that the file size does not exceed 25MB (subject to Cloudflare Workers limits). Audio files need to be uploaded in binary form or accessed via a public URL (e.g. uploaded to cloud storage).
Main function operation flow
speech-to-text
Whisper_Cloudflare uses the Whisper model to convert audio to text. The steps are as follows:
- Upload Audio: Sends audio binary data via POST request to the
/rawInterfaces. Example:curl -X POST "https://whisper.ohen5pbf93.workers.dev/raw" \ -H "Content-Type: application/octet-stream" \ --data-binary "@audio.mp3" - Getting results: Returns the transcription result in JSON format, containing text and a timestamp:
{ "response": { "text": "这是一个测试音频。", "segments": [ {"text": "这是一个", "start": 0.0, "end": 1.2}, {"text": "测试音频", "start": 1.3, "end": 2.5} ] } } - Handling large filesIf the audio exceeds 25MB, you need to manually split it into smaller chunks (1MB per chunk is recommended), upload the chunks one by one and merge the results.
Subtitle Generation
Generate SRT format subtitle files for videos or podcasts. Procedure:
- Request subtitles: Send audio to
/srtInterface:curl -X POST "https://whispercloudflare.tchepai.com/srt" \ -H "Content-Type: application/octet-stream" \ --data-binary "@audio.mp3" - Getting results: Returns files in SRT format, for example:
1 00:00:00,000 --> 00:00:01,200 这是一个 2 00:00:01,300 --> 00:00:02,500 测试音频
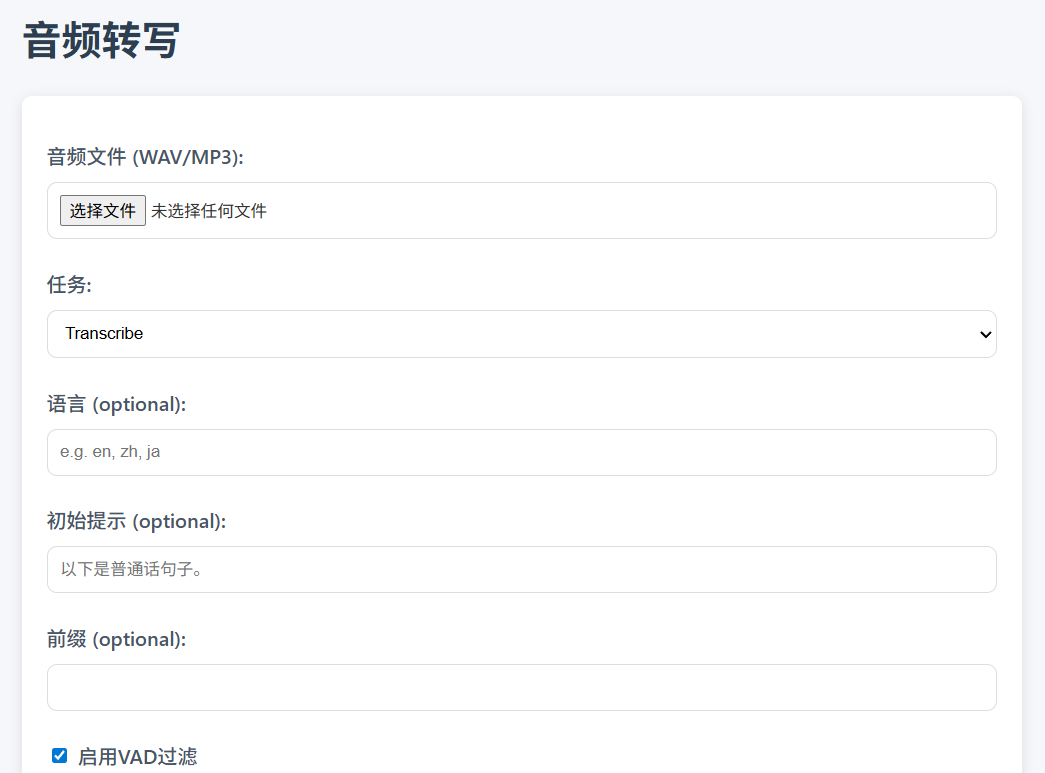
Web Interface Usage
worker.js Provides a built-in HTML interface (root path to the Worker URL) /), which can be operated by the user through the browser:
- access interface: Open the Worker URL (e.g. https://whispercloudflare.tchepai.com/).
- Upload Audio: Select an MP3 or WAV file, set parameters such as task type (transcription or translation), language, VAD filtering, etc.
- Getting results: After submission, the interface displays the SRT subtitle and supports downloading it as a
.srtDocumentation. - take note of: The interface supports a progress bar and takes about 1.9 minutes to process 41 minutes of audio.
API Usage
The project provides two API interfaces:
/raw: Returns raw transcription data in JSON format, suitable for further processing by developers./srt: Returns subtitle files in SRT format for direct use in video editing.
Example JavaScript call:
const response = await fetch('https://whispercloudflare.tchepai.com/srt', {
method: 'POST',
headers: { 'Content-Type': 'application/octet-stream' },
body: audioFile // 音频二进制数据
});
const srt = await response.text();
console.log(srt); // 输出 SRT 字幕
contextual optimization
utilization initial_prompt 或 prefix Parameters provide context to enhance transcription accuracy. Example:
curl -X POST "https://whispercloudflare.tchepai.com/raw?initial_prompt=技术会议" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
Voice Activity Detection (VAD)
Enable VAD filtering (vad_filter=true) may remove non-speech parts:
curl -X POST "https://whispercloudflare.tchepai.com/raw?vad_filter=true" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
translation function
set up task=translate 和 language parameter to translate the audio to the specified language. Example:
curl -X POST "https://whispercloudflare.tchepai.com/raw?task=translate&language=en" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
Performance and Limitations
- tempo: Tests show that it takes only 1.9 minutes to process 41 minutes and 39 seconds of audio.
- limitation: Resource limitations of Cloudflare Workers may cause occasional failures, retrying is recommended.
- file size: No more than 25MB of audio in a single request.
caveat
- API Security: Configure AI bindings in the Cloudflare dashboard and don't give away API tokens.
- error handling: If the request fails, wait a few seconds and retry.
- Browser compatibility: The web interface works well on modern browsers (e.g. Chrome, Firefox).
application scenario
- Transcription of meeting records
Upload meeting audio and generate text or SRT subtitles for multilingual meeting organization. - Podcast Subtitle Generation
Podcast producers generate SRT subtitles to improve content accessibility and search optimization. - Transcription of educational resources
Teachers or students upload class recordings to generate notes or subtitles for easy review. - Voice Application Development
Developers integrate APIs to build real-time captions or voice assistants for lightweight projects.
QA
- What audio formats are supported?
MP3, WAV and other formats are supported and high quality audio is recommended. - How do you handle large files?
Manually split into 1MB chunks, upload and merge results chunk by chunk. - Do I have to pay for deployment?
The Cloudflare Workers free plan supports deployments with 10,000 free neurons per day for AI models, with overages billed at $0.011 per 1000 neurons. - How to optimize transcription?
utilizationinitial_prompt、prefix或vad_filterParameters enhance accuracy. - What languages are supported?
Support for English, Chinese, Japanese and other languages, refer to the Whisper documentation for specific code.


























