



Web Crawler is an open source web crawler tool that runs as a command line interface (CLI) and provides users with a concise, real-time channel for searching information on the Internet. The tool is specifically designed to search the web based on the query keywords entered by the user and output the results in JSON format (containing the title, URL, and release date) directly in the terminal in order of release time from near to far. This project is part of the "financial-datasets" organization, which is dedicated to providing easy-to-use financial data APIs and tools for Large Language Models (LLMs) and Artificial Intelligence agents (AI agents). This web crawler, as a member of their tool suite, is designed to quickly and efficiently crawl the latest information from the Internet to provide raw data input for subsequent data analysis and AI applications.
Function List
- Real-time web search: Receives any query term entered by the user through the command line interface and performs the search immediately.
- JSON format output: Search results are returned in a structured JSON format, each containing the
title(Title),url(web site) andpublished_date(release date) three fields. - Sort by timeliness: The returned search results are strictly sorted by the date of publication to ensure that users see the most up-to-date information first.
- Interactive queries: The tool supports continuous search. After completing a search, users can immediately enter new keywords for the next search without restarting the program.
- cross-platform compatibility: Based on Python development, it can run in any environment that supports Python 3.12+.
- Simple exit mechanisms: The user can enter a name by typing
q、quit、exitor use the shortcut keyCtrl+Cto easily exit the program.
Using Help
The tool is a lightweight command line program that requires no complex installation or configuration to get started quickly. Below is a detailed installation and usage procedure.
environmental preparation
Before you begin, make sure you have the following two essential programs installed on your computer:
- Python: The version requirements are
3.12Or higher. - uv: A fast Python package installation and management tool.
Installation steps
- Clone Code Repository
Open your terminal (command line tool) and use thegitcommand clones the project's source code from GitHub to your local computer.git clone https://github.com/financial-datasets/web-crawler.git - Go to the project directory
After cloning is complete, use thecdcommand into the project folder you just created.cd web-crawler
running program
When you are in the project root directory (web-crawlerfolder), you can directly run the following command to start this web crawler tool:
uv run web-crawler
uv run The command automatically handles the installation of the required dependencies for the project and the configuration of the virtual environment, followed by the launch of the main program.
workflow
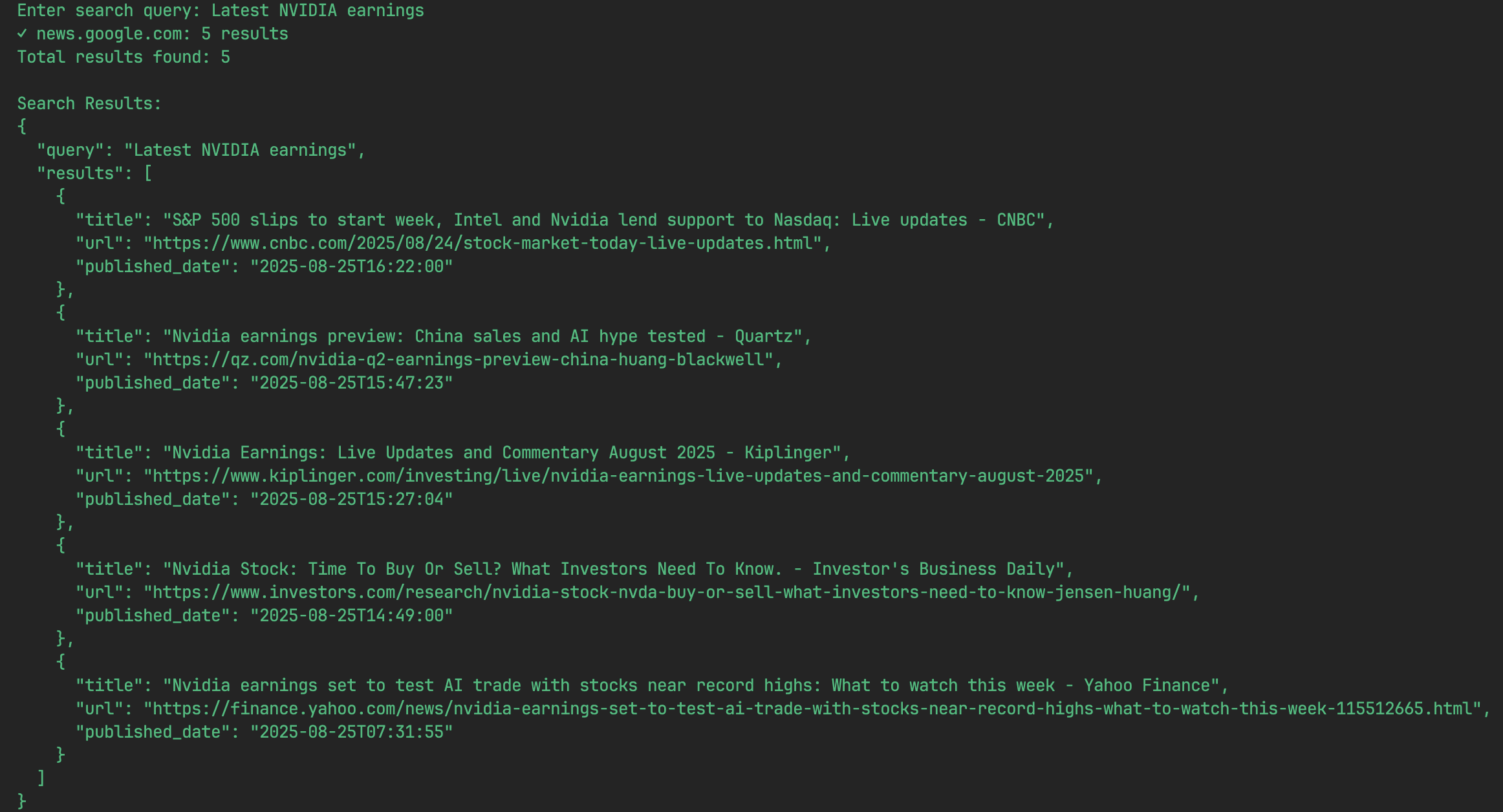
- Enter a query
Once the program starts, the terminal prompts you to enter what you want to search for. You can enter any keyword of interest, for example, to look up the minutes of Apple's latest earnings meeting:Enter your search (e.g., "AAPL latest earnings transcript"):Type your query here and hit enter.
- View Results
The program starts searching immediately and prints the results on the screen as a list of JSON objects within a few seconds. Each JSON object represents a search result, containing the title, URL and date of publication.For example, the results of a search might look like the following:
[ { "title": "Apple Inc. (AAPL) Q3 2025 Earnings Call Transcript", "url": "https://example.com/aapl-q3-2025-transcript", "published_date": "2025-07-30" }, { "title": "Analysis of Apple's Latest Financial Report", "url": "https://example-news.com/aapl-q3-analysis", "published_date": "2025-07-29" } ] - Continue or withdraw
- Continue searching: At the end of a query, the program will display the input prompt again, and you can directly enter new keywords for the next search.
- opt-out program: If you want to end the use, you can type after the input prompt
q、quit或exitand press enter. Also, you can always use the keyboard shortcutCtrl+Cto force an interrupt and exit the program.
application scenario
- Financial Analysts and Researchers
Analysts can use this tool to quickly retrieve the latest earnings reports, press releases, market analyses and executive interviews for specific companies. For example, enter a company code and "earnings transcript" to quickly get a link to the text of the latest earnings meeting, providing timely data to support financial modeling and investment decisions. - Data Input for AI Agents and Large Language Models
This tool can be used as part of an automated workflow to provide real-time data feeds to AI agents. For example, an AI agent used to write market summaries could call this crawler to get links to the latest news about a specific industry or company, and then access those links to summarize and generate a report. - Software Developers & Data Scientists
Developers can integrate this crawler into their applications for monitoring web information on specific topics. For example, build a public opinion monitoring system to collect the latest user feedback and media reports by regularly querying keywords related to a product. - Journalists and journalists
Reporters can use the tool to track the latest developments of breaking news events. By entering event keywords, links to reports from different news sources can be quickly accessed and organized by timeline to efficiently keep abreast of events.
QA
- Does this tool search the entire web?
The tool currently utilizes DuckDuckGo's search API for information retrieval, which could theoretically cover a wide range of Internet content. However, the future development roadmap plans to include more data sources, such as Bing and Reddit, to further expand the breadth and diversity of the search. - Why are the search results in JSON format?
JSON is a lightweight, easy to read and write data exchange format that is also easy for machines to parse and generate. For developers, this format is very user-friendly and it is easy to use the output of this tool as input to other programs, facilitating automated processing processes. - Can this project be used to crawl websites that require a login or have complex JavaScript loading?
The current version is limited in its ability to handle sites that require a lot of JavaScript to load content dynamically (such as some of the major financial news sites). This is one of the known to-dos, and future releases are planned to improve content parsing for such "JavaScript-heavy" pages. - I am a developer, can I contribute to this project?
Absolutely. This is an open source project and community help and contributions are very welcome. The official roadmap mentions a number of directions where help is needed, including but not limited to: improving JavaScript page parsing, integrating large language models for content summarization, adding new data sources, and improving speed by parallelizing queries.































