



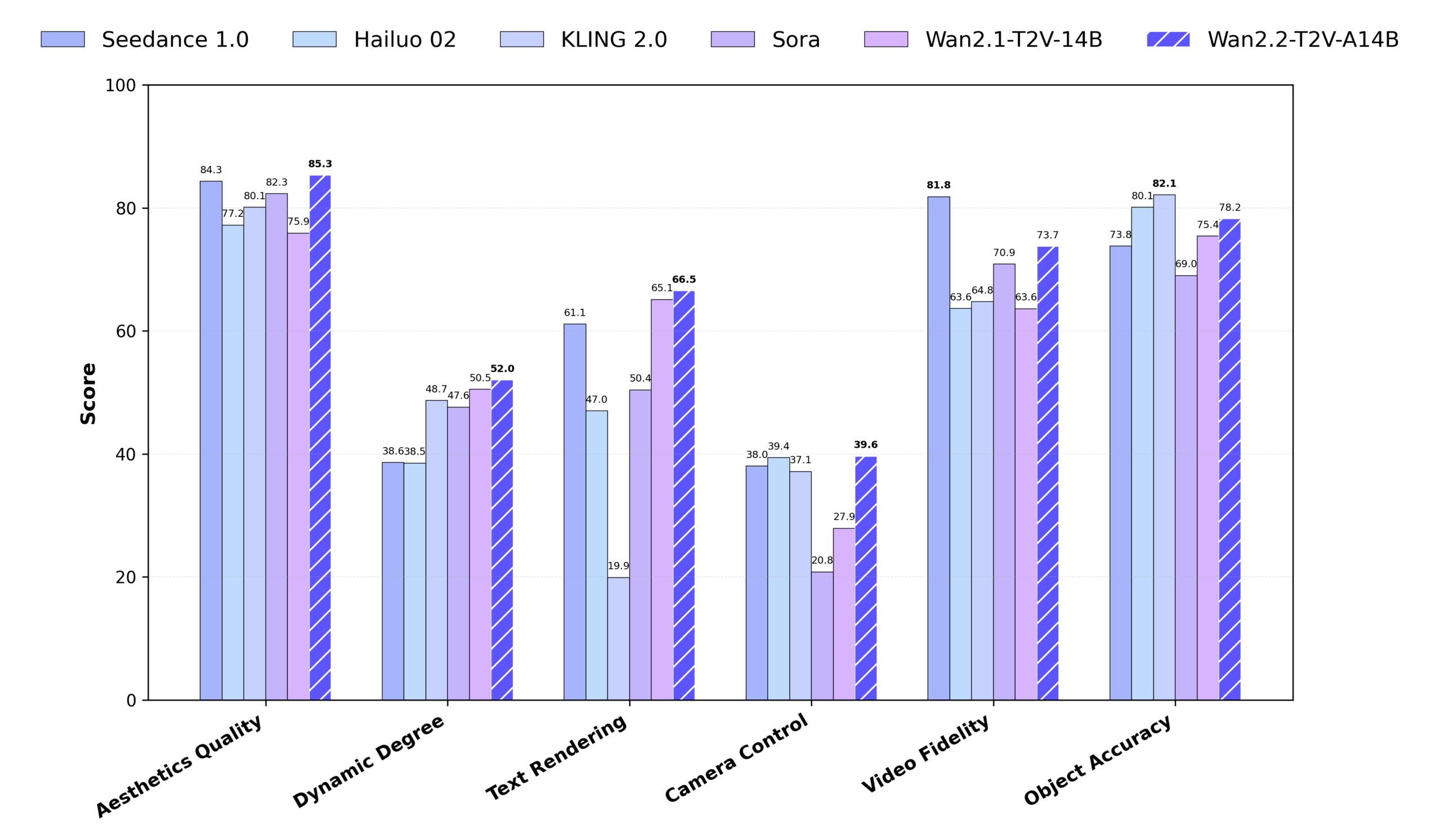
Wan2.2 is an open source video generation model developed by Alibaba Tongyi Labs, focusing on generating high quality videos from text or images. It adopts the Mixed Expert (MoE) architecture, which significantly improves the generation quality by separating the denoising process of high-noise and low-noise phases, while maintaining computational efficiency.Wan2.2 supports 720P@24fps HD video generation, and runs on consumer GPUs (e.g., RTX 4090), making it suitable for individual creators and developers. Compared to Wan2.1, Wan2.2 adds 65.6% of images and 83.2% of videos to the training data, significantly improving motion generation, semantic understanding, and aesthetics. It supports text-to-video (T2V), image-to-video (I2V), and text-image co-generation (TI2V), and integrates with Diffusers and ComfyUI to provide flexible usage.Wan2.2 outperforms some of the commercial models in Wan-Bench 2.0 benchmarks, demonstrating strong performance and wide application potential.
Function List
- Text to video (T2V) Generate 5 seconds of 480P or 720P video from text descriptions, supporting complex scenes and actions.
- Image to video (I2V) : Generate motion video from still images, maintaining picture consistency and style.
- Joint Text-Image Generation (TI2V) : Combines text and images to generate 720P@24fps video for low video memory devices.
- Efficient Video Variable Auto-Encoder (Wan-VAE) : Realizes 16×16×4 compression ratio and supports high-quality video reconstruction.
- Hybrid Expert Architecture (MoE) : Improve generation quality and maintain computational efficiency using high and low noise expert models.
- Cinematic aesthetics : Supports fine control of lighting, composition, and color tones to generate professional movie-style videos.
- Complex motion generation : Support dynamic movements such as dancing, fighting, parkour, etc. with smooth and natural movements.
- Tip Extension : Enrich text cues and enhance video detail with the Dashscope API or native Qwen models.
- Low memory optimization : Supports FP8 quantization and model offloading to reduce GPU memory requirements.
- Multi-Platform Integration : Supports Diffusers and ComfyUI, providing both command line and graphical interface operation.
Using Help
Installation process
To use Wan2.2, you need to configure your environment locally or on a server. The following detailed installation and usage steps are suitable for beginners and experienced developers.
1. Environmental preparation
Make sure your system meets the following requirements:
- software : The T2V-A14B and I2V-A14B models require a GPU with at least 80GB of video memory (e.g., A100); the TI2V-5B model supports consumer GPUs with 24GB of video memory (e.g., RTX 4090).
- operating system : Windows, Linux or macOS are supported.
- Python version : Python 3.10 or later.
- Dependent tools : Git, PyTorch (2.4.0 or later recommended), Hugging Face CLI, ModelScope CLI.
2. Cloning the code base
Clone the Wan2.2 code base by running the following command in a terminal or command prompt:
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
3. Installation of dependencies
Install the necessary Python libraries. Run the following command:
pip install -r requirements.txt
pip install "huggingface_hub[cli]" modelscope
If you are using multi-GPU acceleration, you need to install the xfuser>=0.4.1:
pip install "xfuser>=0.4.1"
take note of : If flash_attn Installation fails, it is recommended to install the other dependencies first and finally install them separately flash_attn。
4. Download model weights
Wan2.2 provides three models: T2V-A14B, I2V-A14B, and TI2V-5B. The following are the download commands:
Hugging Face downloads :
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
huggingface-cli download Wan-AI/Wan2.2-I2V-A14B --local-dir ./Wan2.2-I2V-A14B
huggingface-cli download Wan-AI/Wan2.2-TI2V-5B --local-dir ./Wan2.2-TI2V-5B
ModelScope Download :
modelscope download Wan-AI/Wan2.2-T2V-A14B --local_dir ./Wan2.2-T2V-A14B
modelscope download Wan-AI/Wan2.2-I2V-A14B --local_dir ./Wan2.2-I2V-A14B
modelscope download Wan-AI/Wan2.2-TI2V-5B --local_dir ./Wan2.2-TI2V-5B
5. Configuring environment variables (optional)
If you are using the Hint Extension, you need to configure the Dashscope API key:
export DASH_API_KEY=your_dashscope_api_key
For international users, additional settings are required:
export DASH_API_URL=https://dashscope-intl.aliyuncs.com/api/v1
You need to apply for an API key in Alibaba Cloud in advance.
6. Run the build script
Wan2.2 Provision generate.py Scripts are used to generate videos. Below is an example of how each task is run:
Text-to-video (T2V-A14B) :
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --offload_model True --convert_model_dtype --prompt "两只拟人猫穿着舒适的拳击装备,在聚光灯舞台上激烈对战"
- Single GPU : 80GB of video memory required, enable
--offload_model True和--convert_model_dtypeReduced video memory requirements. - Multi-GPU :
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "两只拟人猫穿着舒适的拳击装备,在聚光灯舞台上激烈对战"
Image to video (I2V-A14B) :
python generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --offload_model True --convert_model_dtype --image examples/i2v_input.JPG --prompt "夏日海滩度假风格,一只戴墨镜的白猫坐在冲浪板上,背景是模糊的海景和绿色山丘"
- The image resolution needs to match the target video resolution.
- Supports unprompted word generation, relying only on the input image:
DASH_API_KEY=your_key python generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --prompt '' --image examples/i2v_input.JPG --use_prompt_extend --prompt_extend_method 'dashscope'
Joint text-image generation (TI2V-5B) :
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "两只拟人猫穿着舒适的拳击装备,在聚光灯舞台上激烈对战"
- image input (I2V mode):
python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "夏日海滩度假风格,一只戴墨镜的白猫坐在冲浪板上"
- The TI2V-5B supports a GPU with 24GB of video memory and takes about 9 minutes to generate 720P@24fps video.
Tip Extension :
Use the Dashscope API:
DASH_API_KEY=your_key python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh' --prompt "两只拟人猫穿着舒适的拳击装备,在聚光灯舞台上激烈对战"
Using a native Qwen model (e.g. Qwen/Qwen2.5-7B-Instruct):
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_model 'Qwen/Qwen2.5-7B-Instruct' --prompt "两只拟人猫穿着舒适的拳击装备,在聚光灯舞台上激烈对战"
7. Using ComfyUI
Wan2.2 is integrated into ComfyUI for GUI users. Installation steps:
- Clone ComfyUI-WanVideoWrapper:
git clone https://github.com/kijai/ComfyUI-WanVideoWrapper.git
cd ComfyUI-WanVideoWrapper
pip install -r requirements.txt
- Place the model file into the ComfyUI Catalog:
- T2V/I2V model:
ComfyUI/models/diffusion_models/ - VAE model:
ComfyUI/models/vae/ - CLIP model:
ComfyUI/models/clip_vision/
- T2V/I2V model:
- Load the workflow in ComfyUI, import the Wan2.2 model, set the prompts and run it.
8. Use of Diffusers
Wan2.2 has been integrated into Diffusers to simplify model calling:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("Wan-AI/Wan2.2-TI2V-5B-Diffusers")
pipeline.to("cuda")
video = pipeline(prompt="两只拟人猫穿着舒适的拳击装备,在聚光灯舞台上激烈对战").videos
The T2V-A14B, I2V-A14B and TI2V-5B models are supported.
Operation of the main functions
Text to Video
Generate a 5-second video by entering a detailed text description, such as "A city skyline at night with neon lights flashing". Specific cues are recommended, such as "A girl in a red coat walking in the snow with a snow-covered forest in the background". Enable cue extensions (--use_prompt_extend) The description can be automatically enriched to generate a more detailed picture.
Image to Video
Upload a picture with a text description to generate an animated video. For example, upload a photo of a cat and type "Cat chasing butterfly on grass" to generate the corresponding animation. Make sure the image resolution is the same as the target video.
Joint text-image generation
The TI2V-5B model supports text or image input to generate 720P@24fps video. Suitable for low video memory devices, fast generation speed and stable results.
Cinematic aesthetics
Wan2.2 supports fine control over lighting, composition, and color tones. For example, type "Side lighting, high contrast, warm tones, a young man standing in a forest" to generate a movie-style video.
Complex motion generation
Support for generating dynamic movements, such as "street parkour athletes jumping over obstacles" or "hip-hop dancers performing on a neon stage", with smooth and natural movements.
application scenario
- content creation
- Creators can turn text or images into short videos for advertisements, short films or social media content. For example, generate an animated video of a "sci-fi spaceship traveling through the stars".
- Education & Presentation
- Teachers can turn static courseware into dynamic videos to enhance teaching and learning. For example, the description of historical events is turned into a video to show historical scenes.
- Game & Animation Development
- Developers can generate game background videos or animated prototypes. For example, generate a "daily life in a medieval village" as a reference for a game scene.
- Commercial publicity
- Enterprises can generate product promotional videos. For example, enter "the use of smart watches in outdoor sports scenes" to generate a short video that demonstrates the function.
- art
- Artists can turn static paintings into dynamic videos. For example, turn an abstract painting into a flowing animation effect.
QA
- What resolutions does Wan2.2 support?
- T2V-A14B and I2V-A14B support 480P and 720P; TI2V-5B supports 720P (1280).704 or 7041280)。
- How do low video memory devices work?
- Using the TI2V-5B model (24GB video memory), enable the
--offload_model True、--convert_model_dtype和--t5_cpuReduced video memory requirements.
- Using the TI2V-5B model (24GB video memory), enable the
- How can I improve my video quality?
- Use Detailed Cue Words, Enable Cue Expansion, Select FP16 Model (higher quality than FP8).
- Does it support commercial use?
- Yes, Wan2.2 is licensed under the Apache 2.0 license and can be used in commercial projects, subject to applicable laws.
- What are the improvements of Wan2.2 over Wan2.1?
- The introduction of the MoE architecture adds 65.6% of images and 83.2% of video to the training data, supporting more complex motion and cinematic aesthetic effects.


























