

in the wake of wan2.1 With the emergence of video models such as the localized video generation, the technical ecology of localized video generation is gradually maturing. In the past, high-performance hardware was the main obstacle to building video workflows, but with the popularity of cloud computing resources and the development of model optimization technology, even users without top-notch graphics cards are now able to rent cloud 4090 Graphics cards and other ways to learn and explore in depth wan2.1 Video Workflow.
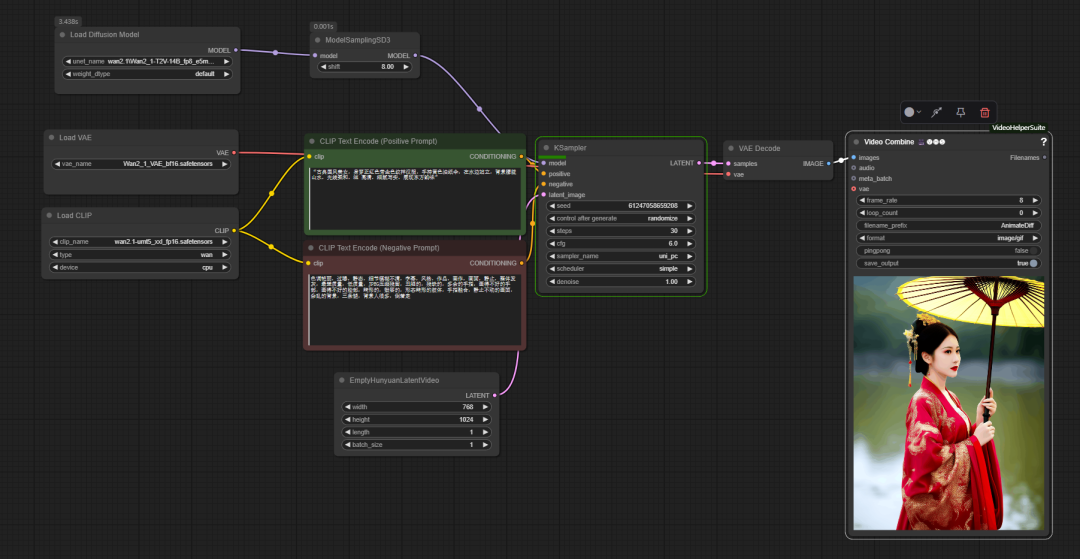
在 ComfyUI in the official base workflow of thewan2.1 is used similarly to the traditional Vincennes diagram process, but with the addition of a key node model sampling sd3. This node is used to adjust the UNet This parameter affects the model's ability to understand and control the cue words, thus optimizing the detail of the generated image.
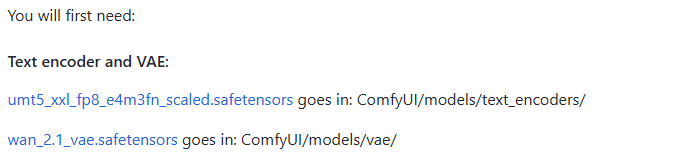
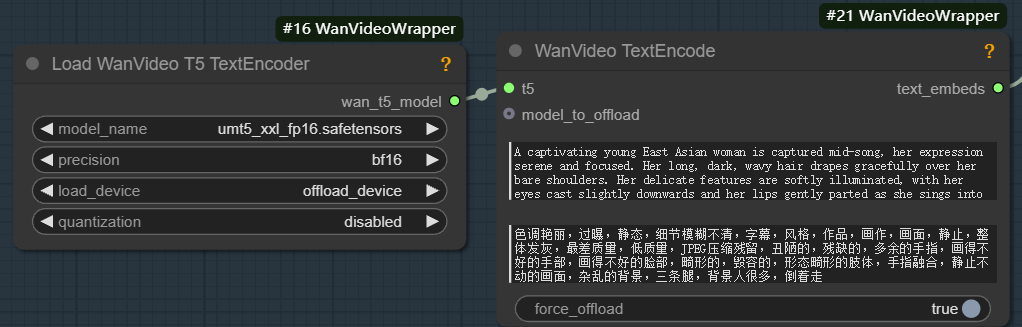
To run wan2.1 model, which must be equipped with the corresponding unmt5 Text Encoder and wan2.1 VAE (Variable Auto-Encoder).VAE consists of two parts, Encoder and Decoder. The encoder is responsible for compressing the input image into a low-dimensional potential space, while the decoder samples from the potential space and reduces it to an image.
The role of the Text Encoder is to transform the input text cues into feature vectors that can be understood by the model. This process consists of two main steps:
- Extract semantic information features of the text, e.g. "1 girl".
- The semantic information is transformed into a high-dimensional embedding vector.
Based on these embedding vectors, a generative model (e.g., UNet) generates image features in the latent space that conform to the textual descriptions, thus determining the type, position, color, and pose of the objects in the frame.
Unlike the static text-generated graph workflow, the final step in the video generation process is the Video Combine (video compositing) node.
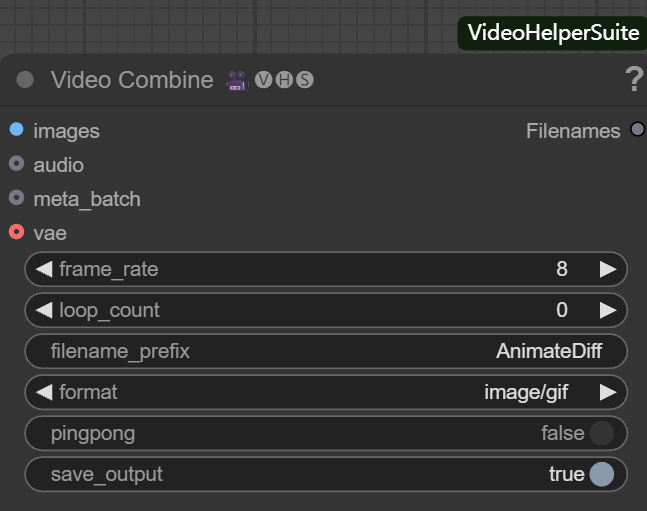
This node is responsible for rectifying image sequences into video or motion picture files. Its main parameters include:
- frame_rate. Determines the smoothness of video playback, e.g. set to
8This means that 8 frames are played per second. - loop_count.
0Represents an infinite loop, applicable to GIFs;1Then it means play once and then stop. - filename_prefix (filename prefix). Set a prefix for the output file, such as
AnimateDiffIt is easy to manage. - format. selectable
image/gifoutputs a moving picture, orvideo/mp4and other video formats. - pingpong (round-trip loop).
falsefor regular sequential playback.trueThen it realizes round-trip playback from the beginning to the end and back to the beginning again. - save_output. set to
trueWhen the node is executed, the file is automatically saved after the execution of the node.
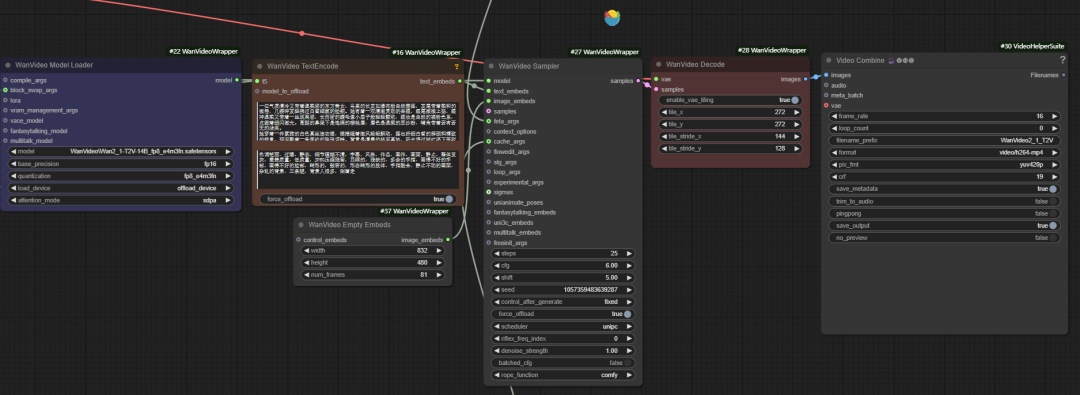
The official workflow only implements basic features, and has limitations in video memory optimization, video enhancement, and so on. For this reason, the developer "K-God" created the wanvideo wrapper toolkit that provides a series of optimized nodes.
The heart of optimization: wanvideo wrapper
wanvideo model loader
wanvideo model loader is a powerful model loading node that not only loads the wanvideo model and also provides a rich set of optimization options.
- Base Precision. The user can select different modeling accuracies such as
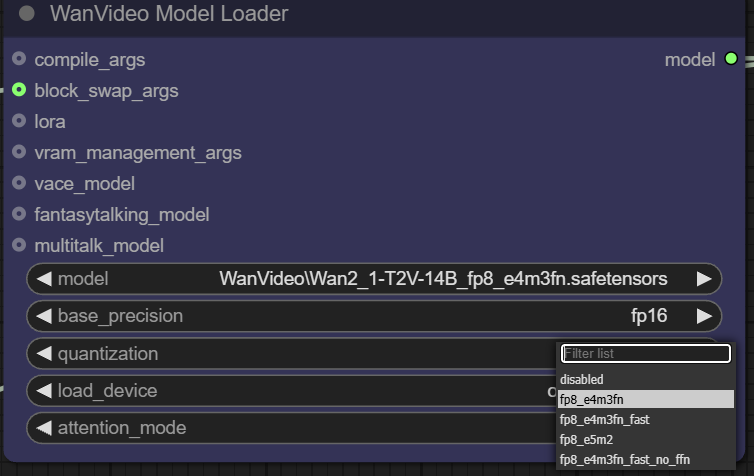
fp32、bf16、fp16。fp32(32-bit floating point) Highest accuracy, but largest memory footprint and computational overhead;fp16(16-bit floating point) can significantly reduce memory usage and increase speed, but may sacrifice some precision. - Quantization. pass (a bill or inspection etc)
quantizationoption, the model can be quantized for further compression. For example, thefp8_e4m3fnThe format uses an 8-bit floating-point representation, which greatly reduces video memory requirements and is particularly suitable for devices with limited video memory, but usually requires the model to have pre-supported quantization.
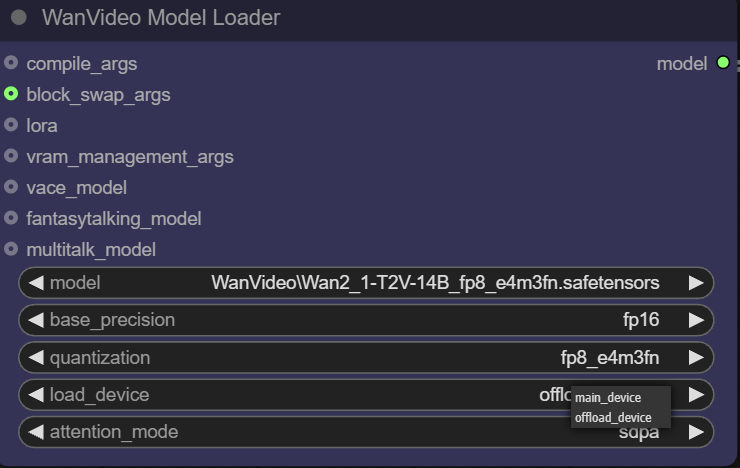
- Load Device.
main deviceusually refers to the GPU, whileoffload deviceThis feature allows offloading some components of the model to the CPU to conserve valuable video memory resources.
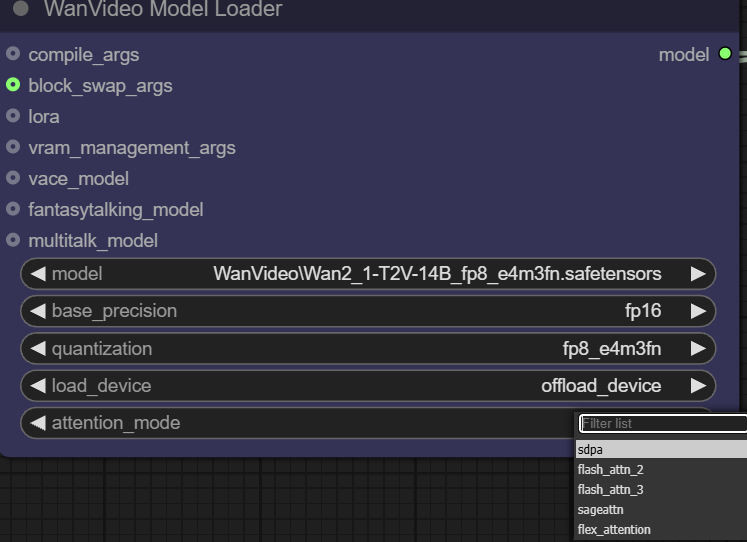
- Attention Mode. This option allows the user to choose a different implementation of the attention mechanism to balance performance and memory. The attention mechanism is at the heart of the Transformer model and determines how the model "focuses" on the relevant parts of the input information when generating content.
The loader also provides several input interfaces for advanced optimization:
- compile args. This interface can be used to configure
torch.compile或xformersand other compilation optimizations.xformersis an optimization tool specifically designed to Transformer library for computation, and thetorch.compileis the on-the-fly compiler introduced in PyTorch 2.0. If the environment has theTritoncompiler, a speedup of about 30% can be obtained.
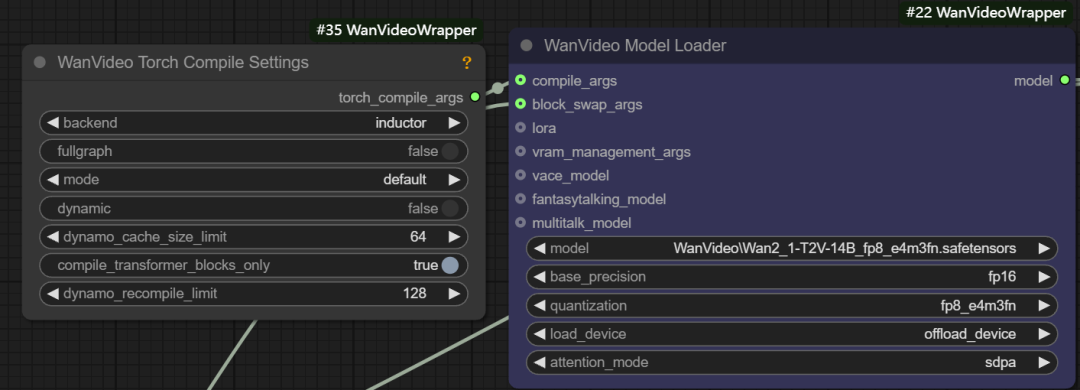
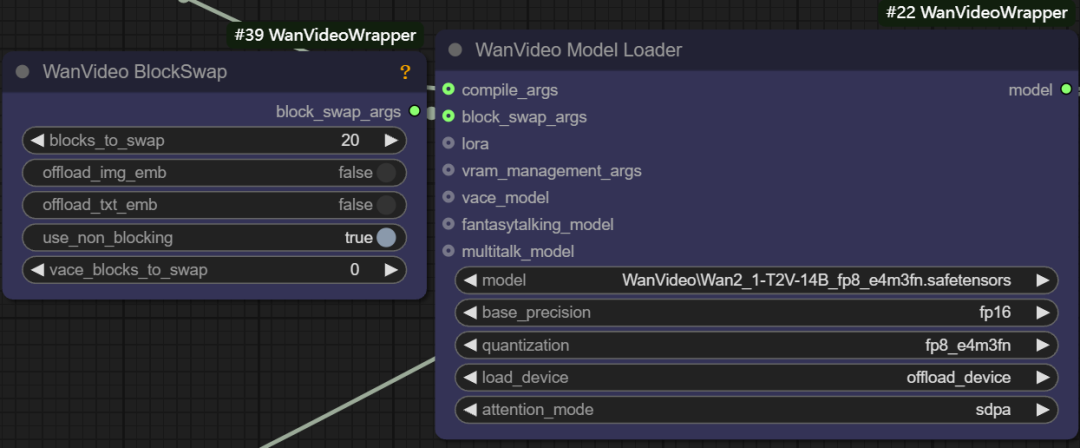
- Block swap args. This function allows to temporarily store some "blocks" of the model to the CPU when there is not enough memory to hold the whole model, for example, by setting the
blocks to swapis 20, meaning that 20 blocks of the model are moved out of the GPU and passed back in via non-blocking when needed. The more blocks that are moved, the more significant the memory savings are, but a certain amount of generation speed is sacrificed by transferring data back and forth.
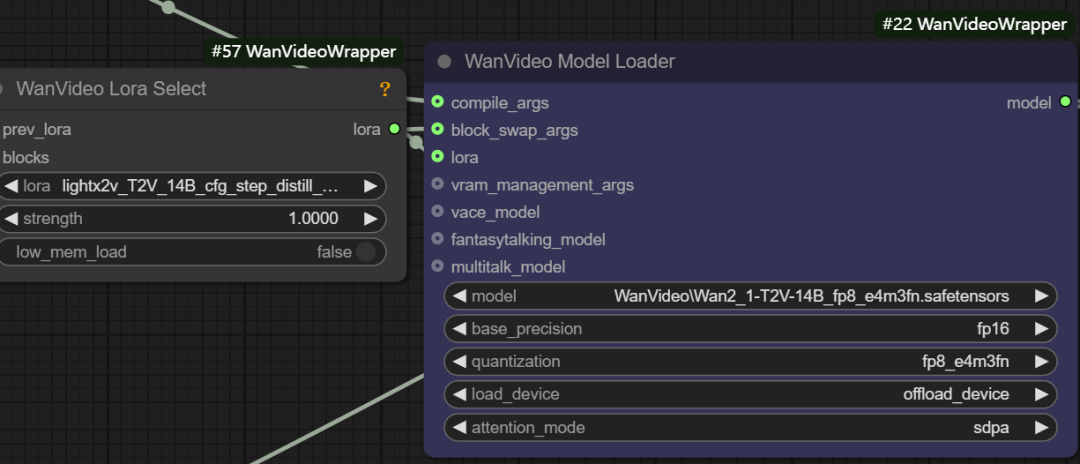
- LoRA Loading. This interface can be connected to
wanvideo lora selectnodes for loading various types of LoRA models, e.g., for accelerating Vincennes videolight x2v t2vLoRA.
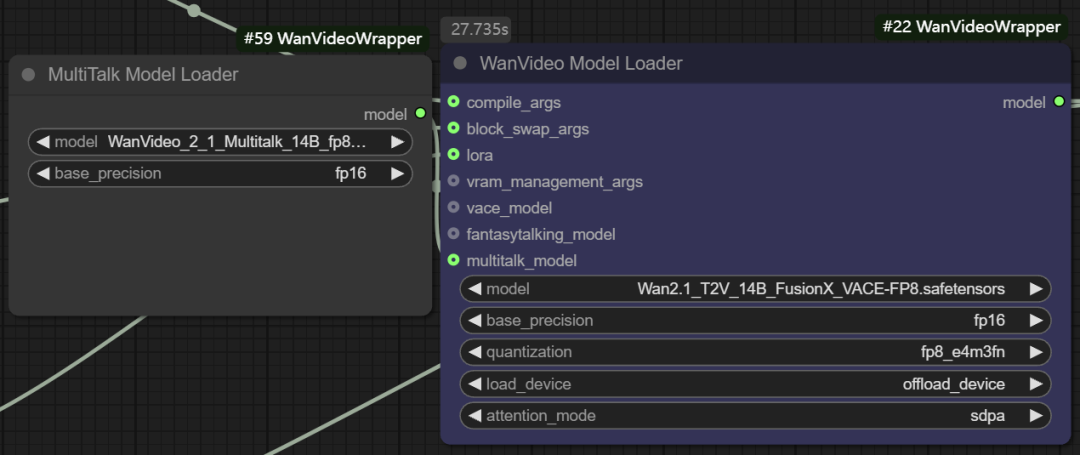
- Multitalk Functional Model. The node also supports loading
Multitalk、Fantasytalkingand other digital human models, which are integrated by the developer into thewanvideo wrapperof emerging open source projects.
wanvideo sampler
wanvideo sampler is based on wan2.1 Model customized video sampling nodes that are central to generating video sequence frames.
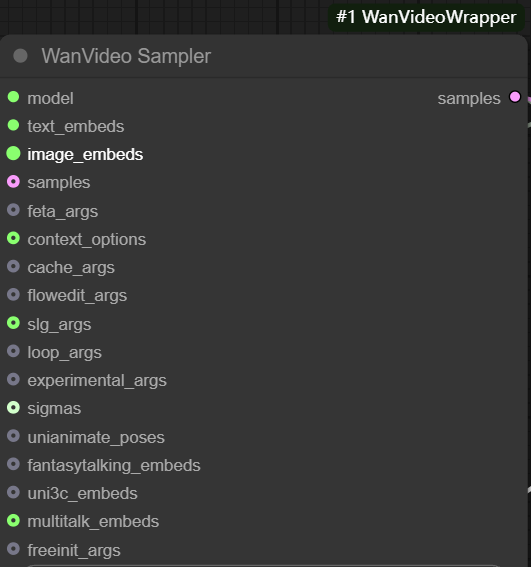
Its main inputs include:
- model: connect from
wanvideo model loaderof the model. - text embeds. grout
wanvideo text encodeThe output of theunmt5The encoded text vector is passed in.
- image embeds. Used to enable image-to-video generation. This workflow usually starts with the
wanvideo clipvision encodeExtract the reference map of theCLIPfeatures, and then through thewanvideo image to video encodeNodes utilize VAE to encode image features into a vector representation usable by the model.
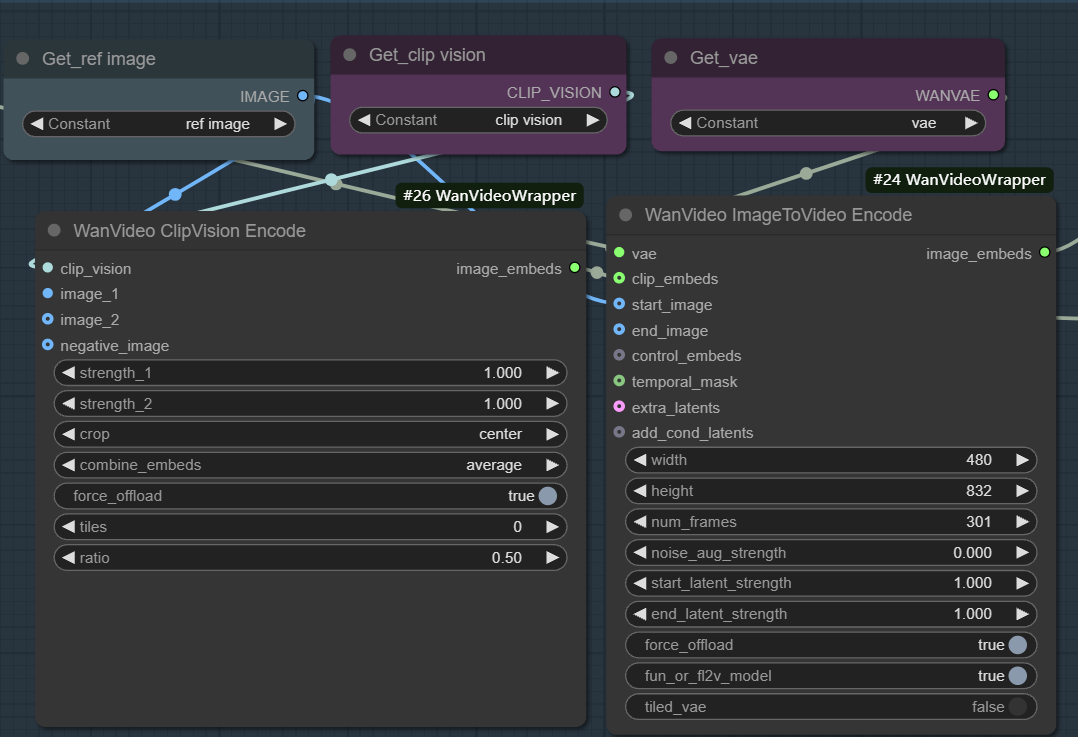
The essence of this process is that the visual and semantic information of a still image is first transformed into feature vectors, and then the sampler uses these features as a bootstrap condition for iterative denoising starting from the noise, and ultimately generating consecutive video frames with content and style consistent with the reference map. By adjusting parameters such as weights, noise and number of frames, the influence of the reference map as well as the diversity of the video can be precisely controlled.
- samples: This input could theoretically receive the sampling results of the previous stage as a starting point for the diffusion iteration, but its
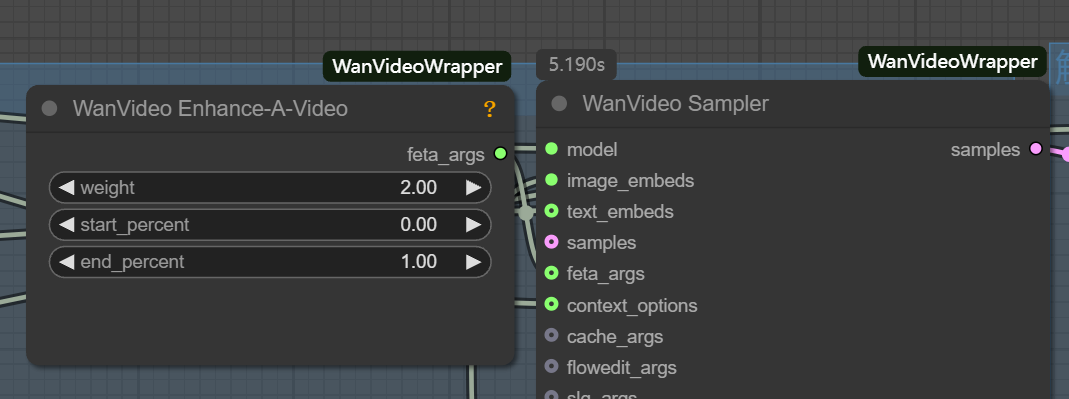
latentFormatting with standard Vincennes chartslatentIncompatibility. - feta args: Used to connect video enhancement nodes to improve video detail, frame alignment and timing stability.
- wanvideo context options: This is the key controller for ensuring coherence between video frames. It solves the problem of disconnected frames and unnatural motion caused by independent frame generation by controlling the way the model refers to contextual information when generating the current frame.
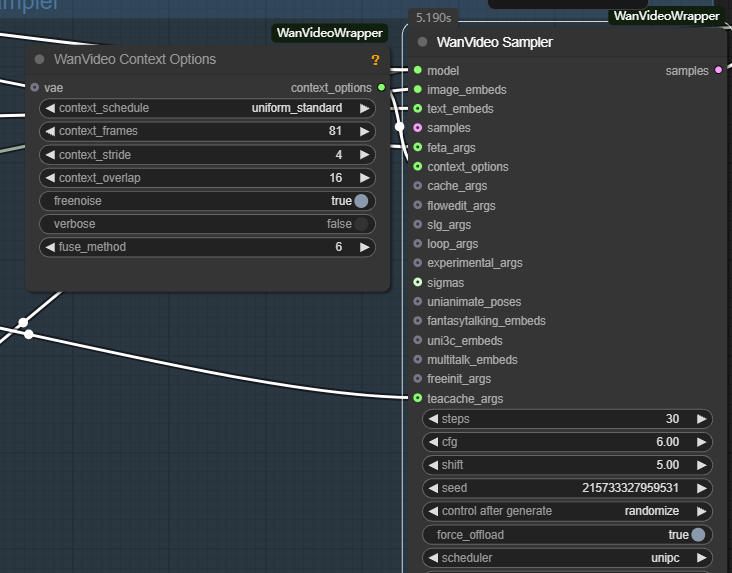
The main parameters are as follows:
- context_frames. Defines the number of neighboring frames that the model references at once. The larger the value, the better the coherence of motion and scene changes, but the amount of computation increases accordingly.
- context_stride (context step). Controls the interval between sampled reference frames. The smaller the step size, the denser the reference and the smoother the detail transition; the larger the step size, the more efficient the computation.
- context_overlap. Defines the number of overlapping frames between neighboring reference windows. Higher overlap ensures smoother transitions between frames and avoids abrupt changes when switching windows.
The Potential of Video Modeling in the Field of Venn diagrams
It is worth mentioning that it will wan2.1 Setting the workflow's output frame rate to 1 makes it a powerful text-generation tool that is even better than the Flux and other specialized image models. Video models may be superior in their understanding of the internal structure and details of an image due to the additional processing of the temporal dimension. This signals that video models may become an important force in the field of still image generation in the future.





























