



Step3 is an open source multimodal macromodeling project developed by StepFun and hosted on GitHub, designed to provide efficient and cost-effective text, image, and speech content generation capabilities. The project is centered on a 32.1 billion-parameter (3.8 billion active parameters) Model of Mixed Experts (MoE), optimized for inference speed and performance for production environments.Step3 supports OpenAI and Anthropic Compatible API interface, model weights are stored in bf16 and block-fp8 format, which is convenient for developers to deploy on multiple inference engines. The project provides detailed deployment guides and sample code, and supports vLLM StepFun is committed to advancing AI through open source, and Step3's code and model weights are licensed under the Apache 2.0 license, allowing developers to use and customize them freely.
Experience Address:Step AI (Leap Ask): AI personal efficiency assistant launched by Step Star
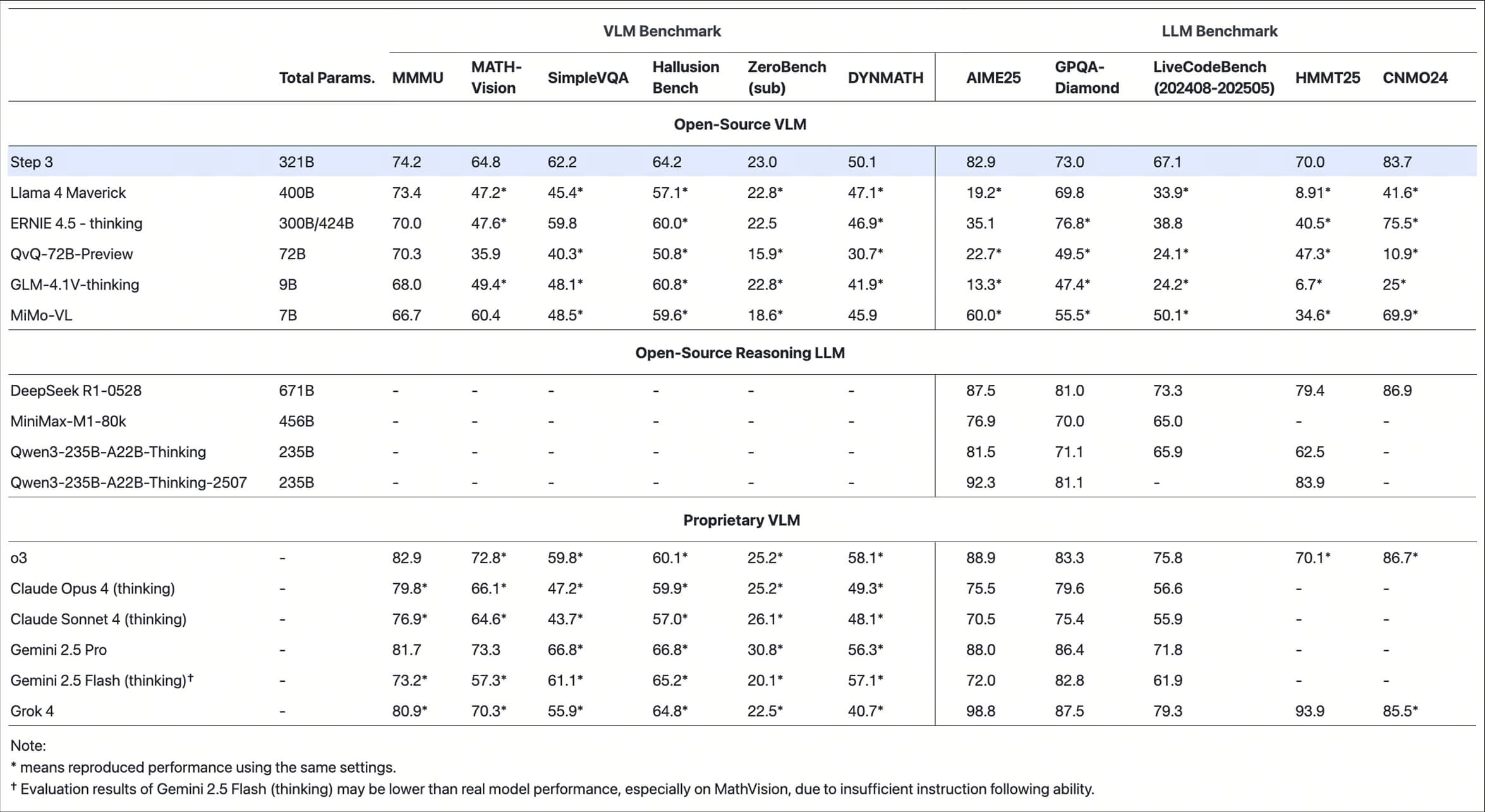
Function List
- Supports multimodal content generation: processes text, image, and speech input to generate high-quality output.
- Efficient Reasoning Optimization: Based on the Mixed Model of Expertise (MoE), it provides fast reasoning speed and is suitable for real-time applications.
- OpenAI/Anthropic Compatible API: via the
https://platform.stepfun.com/Provides standardized API interfaces. - Support for bf16 and block-fp8 formats: model weights optimize storage and reduce hardware requirements.
- Provides vLLM and SGLang deployment examples: simplifies the process of deploying models in production environments.
- Open source code and model weights: developers are free to download, modify and use them.
Using Help
Installation and Deployment
To use Step3, developers need to first clone the code from a GitHub repository and set up the development environment. Here are the detailed installation and usage steps:
- Clone Code Repository
Use the following command to get the Step3 project code from GitHub:git clone https://github.com/stepfun-ai/Step3.git cd Step3This will download the Step3 source code locally.
- Setting up the Python environment
Step3 Python 3.10 and above is recommended and requires PyTorch (recommended version ≥2.1.0) and the Transformers library (recommended version 4.54.0) to be installed. You can configure your environment by following these steps:conda create -n step3 python=3.10 conda activate step3 pip install torch>=2.1.0 pip install transformers==4.54.0Make sure to check that the environment is properly configured after the installation is complete.
- Download model weights
Step3's model weights are hosted on the Hugging Face platform in bf16 and block-fp8 formats. Developers can download it from the following address:- Hugging Face model address:
https://huggingface.co/stepfun-ai/step3 - Download example:
git clone https://huggingface.co/stepfun-ai/step3
Once downloaded, the model weights directory structure should contain the necessary model files such as
step3-fp8或step3。 - Hugging Face model address:
- Model Serving
Step3 supports vLLM and the SGLang inference engine, and a multi-GPU environment (e.g., 4 A800/H800 GPUs with 80GB of video memory each) is recommended for optimal performance. Below are the steps for deployment using vLLM as an example:- Start the vLLM service:
python -m vllm.entrypoints.api_server --model stepfun-ai/step3 --port 8000 - After running, the API service will be run locally in the
http://localhost:8000provided, developers can call the model through the API. - Sample API request:
import requests url = "http://localhost:8000/v1/completions" data = { "model": "stepfun-ai/step3", "prompt": "生成一张秋天森林的图片描述", "max_tokens": 512 } response = requests.post(url, json=data) print(response.json())
- Start the vLLM service:
- Reasoning with the Transformers Library
If you don't use vLLM, you can load the model for inference directly through the Transformers library. Below is the sample code:from transformers import AutoProcessor, AutoModelForCausalLM # 定义模型路径 model_path = "stepfun-ai/step3" processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype="auto", trust_remote_code=True) # 输入示例(图像 + 文本) messages = [ { "role": "user", "content": [ {"type": "image", "image": "https://example.com/image.jpg"}, {"type": "text", "text": "描述这张图片的内容"} ] } ] # 预处理输入 inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device) # 生成输出 generate_ids = model.generate(**inputs, max_new_tokens=32768, do_sample=False) decoded = processor.decode(generate_ids[0, inputs["input_ids"].shape[-1]:], skip_special_tokens=True) print(decoded)This code shows how to load a model, process multimodal inputs, and generate output.
- Featured Function Operation
- Multi-modal inputs: Step3 supports text, image and voice input. Developers can pass in multimodal data through the API or the Transformers library. For example, by uploading an image with a text prompt, the model can generate a description or answer a question related to the image.
- Efficient Reasoning: Step3's MoE architecture optimizes inference speed for real-time applications. Developers can optimize the speed of inference by adjusting the
max_new_tokensparameter controls the output length, with a recommended value of 512 to 32768. - Model Customization: Developers can fine-tune the model based on Step3's open source code, adapting it to specific tasks, such as generating a particular style of text or image.
- Debugging and Support
If you encounter problems with deployment or usage, you can submit an issue via GitHub or contact the official email address.contact@stepfun.comThe StepFun community also offers the Discord channel (https://discord.gg/92ye5tjg7K) for developers to communicate.
application scenario
- content creation
Step3 can be used to generate articles, image descriptions or short video scripts. Creators can enter text prompts or images to quickly generate high-quality content suitable for blogging, social media or advertisement production. - Intelligent Customer Service
Step3's multimodal capabilities support voice and text interactions and can be used to build intelligent customer service systems. Organizations can integrate Step3 via APIs to handle customer inquiries and generate natural language responses. - Educational aids
Teachers and students can use Step3 to generate instructional materials or answer questions. For example, by uploading a picture of a science experiment, the model can generate detailed step-by-step instructions for the experiment. - multimedia processing
Step3 is suitable for processing multimodal data, such as analyzing video frames and generating subtitles, or generating text summaries based on audio, for video editing and content analysis.
QA
- Step3 What inference engines are supported?
Step3 recommends using vLLM and SGLang for inference, which supports model weights in bf16 and block-fp8 formats and is suitable for multi-GPU environments. - How do I get model weights?
Model weights can be downloaded from the Hugging Face platform athttps://huggingface.co/stepfun-ai/step3. Clone the warehouse and it is ready to use. - What are the hardware requirements for Step3?
We recommend using 4 A800/H800 GPUs with 80GB of RAM. single GPU reasoning is possible, but slower. - Does it support fine-tuned models?
Yes, Step3's open source code and model weights allow developers to fine-tune and fit customized tasks.





























