


SongGeneration is a music generation model developed and open-sourced by Tencent AI Lab, focusing on generating high-quality songs, including lyrics, accompaniment and vocals. It is based on the LeVo framework, combines the language model LeLM and music codecs, and supports Chinese and English song generation. The model is trained on millions of song datasets and generates music with excellent sound quality and complete structure, which is suitable for music composition, video soundtrack and other scenarios. Users can control the style, emotion, and tempo of the music through textual descriptions or reference audio to generate personalized songs.SongGeneration's open source nature makes it accessible to developers, music lovers, and content creators, and its support for running on low-memory devices lowers the barrier to use.
Function List
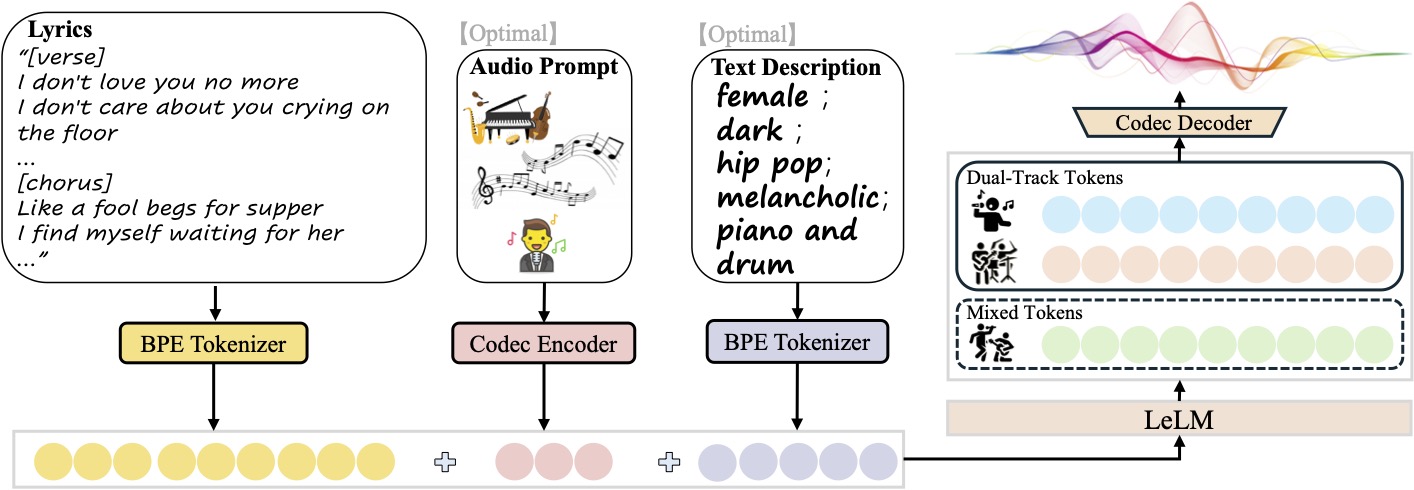
- Song Generation: Generate a full song with vocals and backing tracks based on the input lyrics and text description.
- Multi-track output: Supports separate generation of pure music, pure vocals, or separate vocal and backing tracks for easy post-editing.
- Style Control: Customize music styles with text descriptions (e.g. gender, timbre, genre, emotion, instrument, beat).
- Reference AudioThe model can upload a 10-second audio clip, and the model can mimic its style to generate a new song.
- Low memory optimization: Supports operation with as little as 10GB of GPU memory for a wide range of devices.
- Open Source Support: Model weights, inference scripts and configuration files are provided and can be freely modified and optimized by the developer.
Using Help
Installation process
To use SongGeneration, you need to complete the environment configuration and model installation. Here are the steps, based on the official GitHub repository for Linux (Windows users can refer to the following) ComfyUI (Version):
- Creating a Python Environment
With Python 3.8.12 or later, it is recommended that you create a virtual environment via conda:conda create -n songgeneration python=3.8.12 conda activate songgeneration - Installation of dependencies
Install the necessary dependencies, including PyTorch and FFmpeg:yum install ffmpeg pip install -r requirements.txt --no-deps --extra-index-url https://download.pytorch.org/whl/cu118 - Install Flash Attention (optional)
To accelerate inference, install Flash Attention (requires CUDA 11.8 or above):wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl -P /home/ pip install /home/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whlIf the GPU does not support Flash Attention, you can add an inference to the
--not_use_flash_attnParameters. - Download model weights
Download the model weights and configuration files from Hugging Face and make sure that theckpt和third_partyfolder is saved in its entirety to the project root directory:git clone https://github.com/tencent-ailab/SongGeneration cd SongGenerationVisit the Hugging Face repository (
https://huggingface.co/tencent/SongGeneration) Downloadsonggeneration_base_zhor other versions of the model weights. - Docker installation (optional)
To simplify configuration, you can use the official Docker image:docker pull juhayna/song-generation-levo:hf0613 docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
Usage
SongGeneration supports generating music via command line or script, the core operation is to prepare the input file and run the inference script. Below is the detailed operation flow:
- Preparing the input file
The input file should be JSON Lines (.jsonl) format, each line represents a generated request and contains the following fields:idx: The filename (unique identifier) of the generated audio.gt_lyric: lyrics in the format[结构] 歌词文本e.g.[Verse] 这是第一段歌词。. Supported structures include[intro-short]、[verse]、[chorus]etc., with specific reference toconf/vocab.yaml。descriptions(optional): describes the music attributes such asfemale, pop, sad, piano, the bpm is 125。prompt_audio_path(Optional): 10-second reference audio path for style imitation.
typical example
lyrics.jsonl:{"idx": "song1", "gt_lyric": "[intro-short]\n[verse] 这些逝去的回忆。我们无法抹去泪水。\n[chorus] 像傻瓜乞求晚餐。我在等待她的归来。", "descriptions": "female, pop, sad, piano, the bpm is 125"} - Running inference scripts
Use the default script to generate songs:sh generate.sh <ckpt_path> <lyrics.jsonl> <output_path><ckpt_path>: Model weight paths.<lyrics.jsonl>: Enter the file path.<output_path>: Output audio save path.
If GPU memory is insufficient (<30GB), use low memory mode:
sh generate_lowmem.sh <ckpt_path> <lyrics.jsonl> <output_path> - Custom Generation Options
- Generate pure music: add
--pure_musicLogo. - Generate pure vocals: add
--pure_vocalLogo. - Separate vocals and backing tracks: add
--separate_tracksflag to generate separate vocal and backing tracks. - Disable Flash Attention: Add
--not_use_flash_attn。
- Generate pure music: add
- Windows users (ComfyUI version)
Windows users can use the ComfyUI interface to simplify operations:- Clone the ComfyUI plugin repository:
cd ComfyUI/custom_nodes git clone https://github.com/smthemex/ComfyUI_SongGeneration.git - mounting
fairseqlibrary (precompiled wheel files are recommended for Windows):pip install liyaodev/fairseq - Place the model weights into the
ComfyUI/models/SongGeneration/Catalog. - Load the model through the ComfyUI interface, enter lyrics and description, and click the Generate button.
- Clone the ComfyUI plugin repository:
Handling Precautions
- input prompt: Avoid simultaneous provision of
prompt_audio_path和descriptionsOtherwise, the quality of generation may be degraded due to conflicts. - lyrics format: Lyrics need to be structurally segmented (e.g.
[verse]、[chorus]), non-lyrics segments (such as[intro-short]) should not contain lyrics. - Reference Audio: It is recommended to use the chorus of the song (10 seconds or less) for optimal musicality.
- hardware requirement: 10GB of GPU memory for the base model and 16GB with reference audio.
application scenario
- music composition
Musicians can enter lyrics and style descriptions to quickly generate song demos and save time. For example, enter "Male Vocal, Jazz, Piano, 110 BPM" to generate a jazz style song. - Video soundtrack
Video creators can upload 10 seconds of reference audio to generate a stylized soundtrack for short videos, commercials, or movie soundtracks. - game development
Game developers can generate multi-track music, adjusting vocals and backing tracks separately to fit different game scenarios such as battles or storylines. - Education and experimentation
Students and researchers can use the open source code to study music generation algorithms or test the effects of AI music creation in the classroom.
QA
- What languages does SongGeneration support?
Currently supports Chinese and English song generation, the model is trained on a million song dataset (including Chinese and English songs), and may support more languages in the future. - How do I ensure the sound quality of the generated music?
Use the official model weights and music codecs provided, and make sure the audio sample rate is 48 kHz. avoid using too short lyrics, the model will be auto-completing to ensure structural integrity. - How much memory is needed to run the model?
The base model requires 10GB of GPU memory and 16GB with reference audio. low memory mode (generate_lowmem.sh) can optimize memory usage. - Can commercially generated music be used?
Model license needs to be checked (CC BY-NC 4.0), generated content may be subject to copyright restrictions, it is recommended to consult a legal expert before commercial use.


























