许多用户在将重要资料(如纯图片文件或扫描版 PDF 文档)上传至 LLM 应用开发平台 Dify 的知识库时,常常会遇到一个棘手的问题:Dify 无法直接读取并解析这些非文本格式的内容。这主要是因为 Dify 的知识库原生功能更侧重于处理和理解纯文本数据。为了克服这一限制,可以引入 MinerU-API 工具,它能赋予 Dify 知识库强大的光学字符识别(OCR)能力。接下来,将详细介绍如何构建一个工作流,使 Dify 知识库能够有效解析图片和扫描文档中的文字信息。本教程操作基于 Dify 1.3.1 版本。
preliminary
在开始搭建工作流之前,需要完成两项关键的准备工作:部署 MinerU-API 服务和创建 Dify 知识库。
部署 MinerU-API
MinerU-API 是一款支持多种格式文档解析(包括 OCR)的工具。关于其详细介绍和获取代码的步骤,可以参考《在Dify中使用MinerU提取PDF》和《MinerU-API | 支持多格式解析,进一步提升Dify文档能力》这两篇相关文章。此处假设用户已获得 MinerU-API 的代码,并简述其 Docker 部署命令。
docker run -d --gpus all --network docker_ssrf_proxy_network --name mineru-api -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3
这条命令会在后台启动一个名为 mineru-api (used form a nominal expression) Docker 容器,并分配 GPU 资源(如果可用),同时将其连接到指定的网络,并挂载一个数据卷用于持久化 PaddleOCR 的相关数据。
创建 Dify 知识库
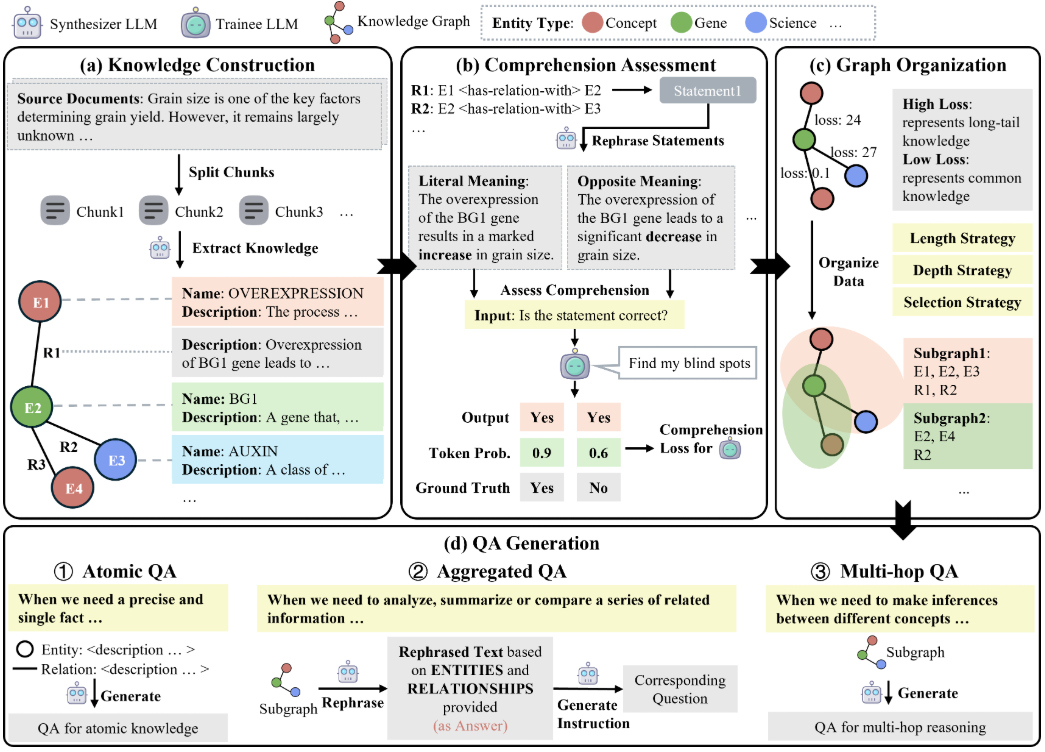
首先,在 Dify 平台中创建一个新的知识库。创建过程中,需要设定基础的 Embedding 模型和 Rerank 模型。Embedding 模型负责将文本数据转换为高维向量,以便机器进行语义理解和相似度计算;Rerank 模型则用于对初步检索结果进行重新排序,以提高最终答案的准确性和相关性。
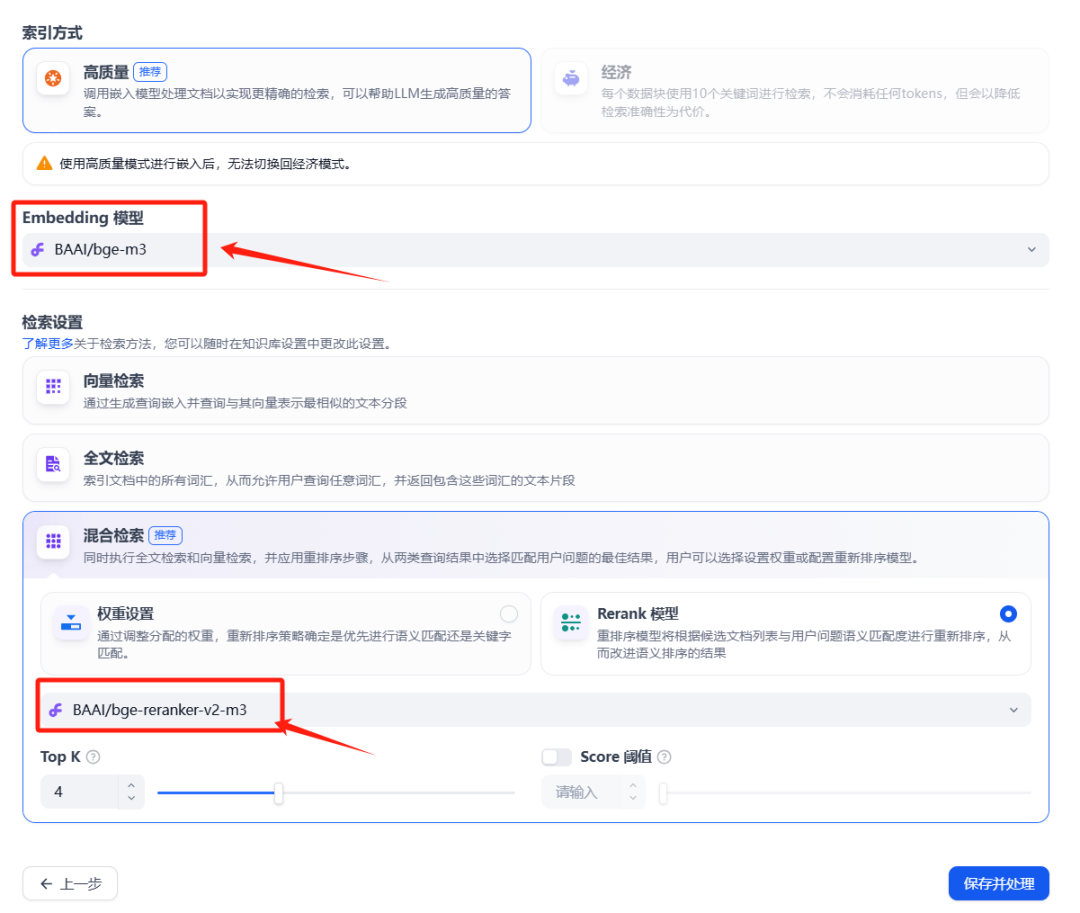
图1:创建Dify知识库界面
知识库创建完成后,打开该知识库,并在浏览器的地址栏中找到并记录下该知识库的 ID。这个 ID 是后续 API 调用的重要参数。
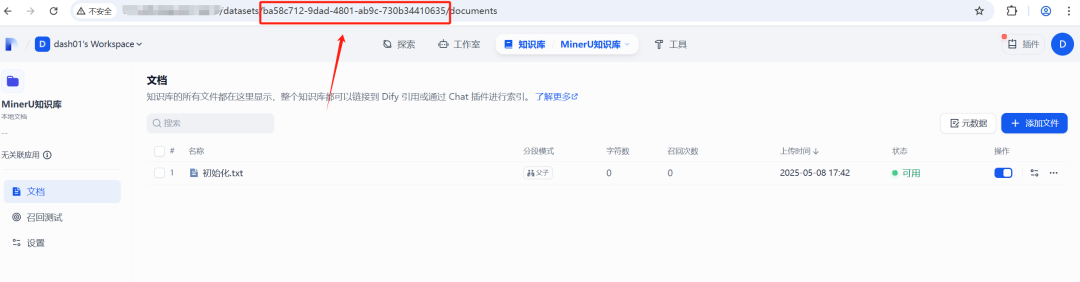
图2:从浏览器地址栏获取知识库ID
接着,导航至知识库 -> API 设置界面,生成一个新的 API 密钥。此密钥将用于授权工作流对知识库进行的各项操作。
图3:生成知识库API密钥界面
搭建 MinerU 知识库工作流
工作流概述
所构建的工作流主要包含三个关键的代码执行节点,它们协同工作以实现对图片或扫描文档的解析及入库。
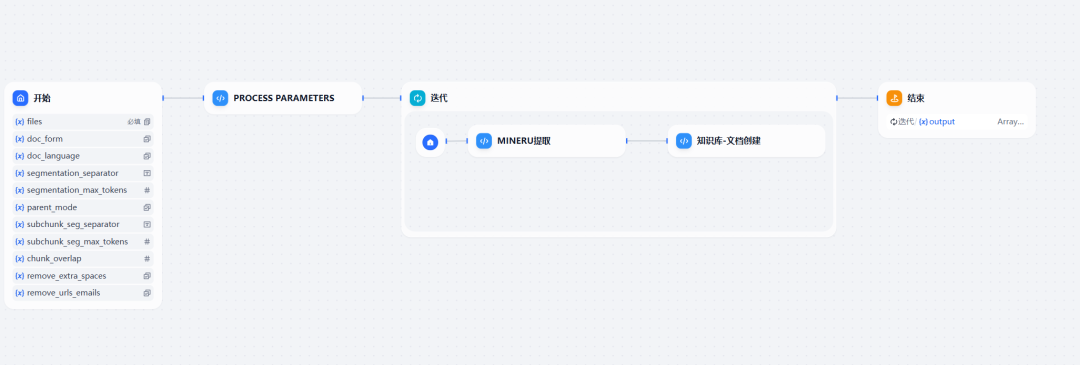
图4:MinerU知识库工作流概览
这三个代码块的功能分别如下:
- Process Parameters:此节点主要负责处理调用
Dify创建文档接口(/datasets/{dataset_id}/document/create-by-text)时所需的参数。 - MinerU提取:该节点的核心任务是调用
MinerU-API服务,将输入的 PDF 或图片文件通过 OCR 技术转换为 Markdown 格式的纯文本内容。 - 知识库-文档创建:此节点通过调用
Dify平台的/datasets/{dataset_id}/document/create-by-textAPI 接口,将在上一步中由MinerU提取出的文本内容创建为知识库中的一个新文档。以下是该节点的 Python 示例代码:
import requests
def main(api_key, file_name, content, api_params, dataset_id):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
# 更新API参数,加入文件名和提取的文本内容
api_params.update({
"name": file_name,
"text": content,
})
# 构建Dify API的请求URL
# 注意:实际部署时,'http://api:5001' 可能需要根据Dify服务的实际地址和端口进行调整
url = f'http://api:5001/v1/datasets/{dataset_id}/document/create-by-text'
response = requests.post(
url,
headers=headers,
json=api_params,
)
return {"result": response.text}
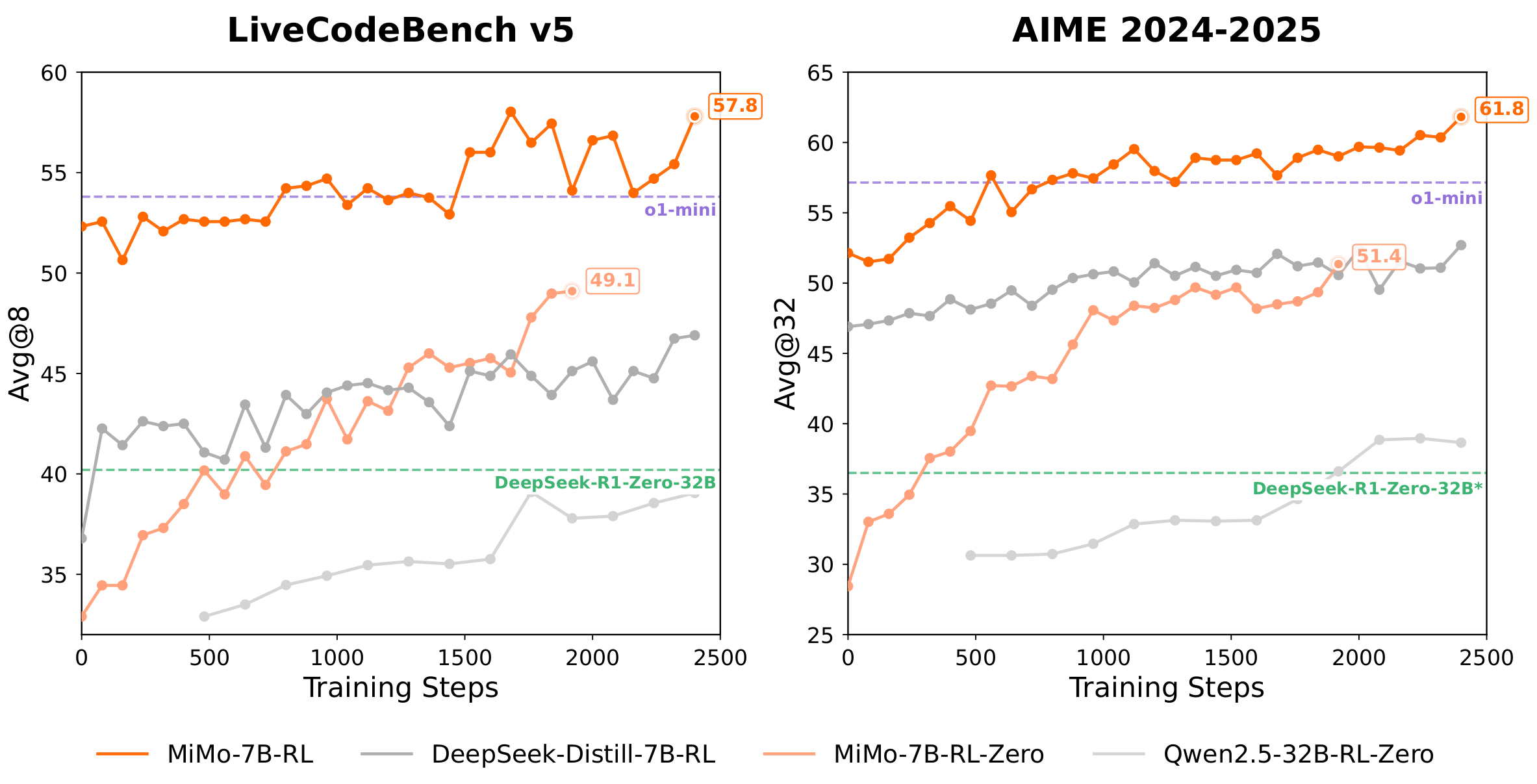
Effectiveness Test
为了验证工作流的有效性,以一份由网页直接打印生成的 PDF 文档为例,对比直接上传至 Dify 知识库与通过新建的 MinerU 工作流处理的效果。
直接上传知识库的效果:
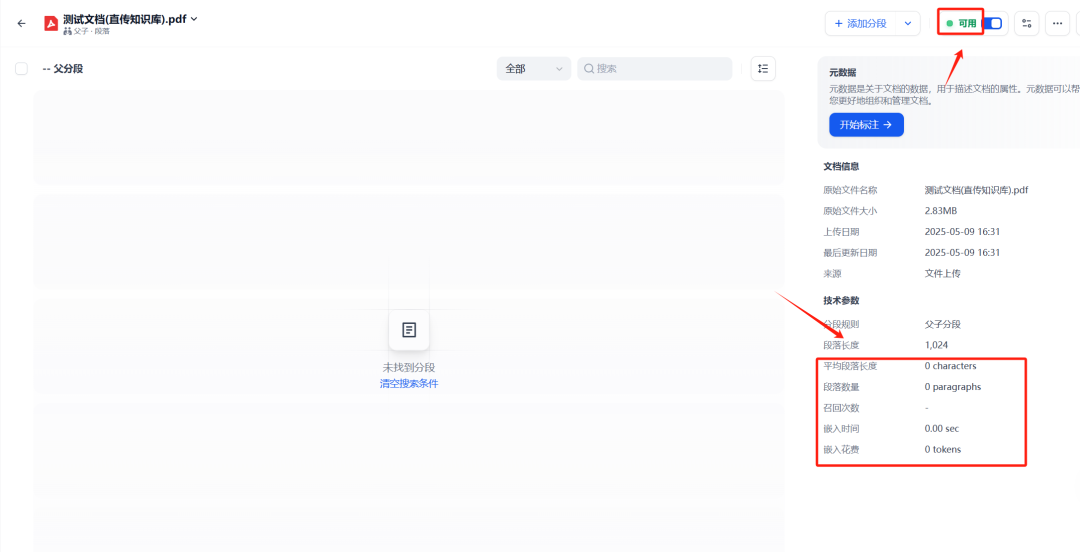
图5:直接上传PDF文档至Dify知识库后的状态
从上图可以看到,尽管文档成功上传,但 Dify 的原生知识库能力无法解析这份扫描版 PDF 中的任何文本内容,导致文档在知识库中几乎为空白。
通过 MinerU 工作流创建文档的效果:
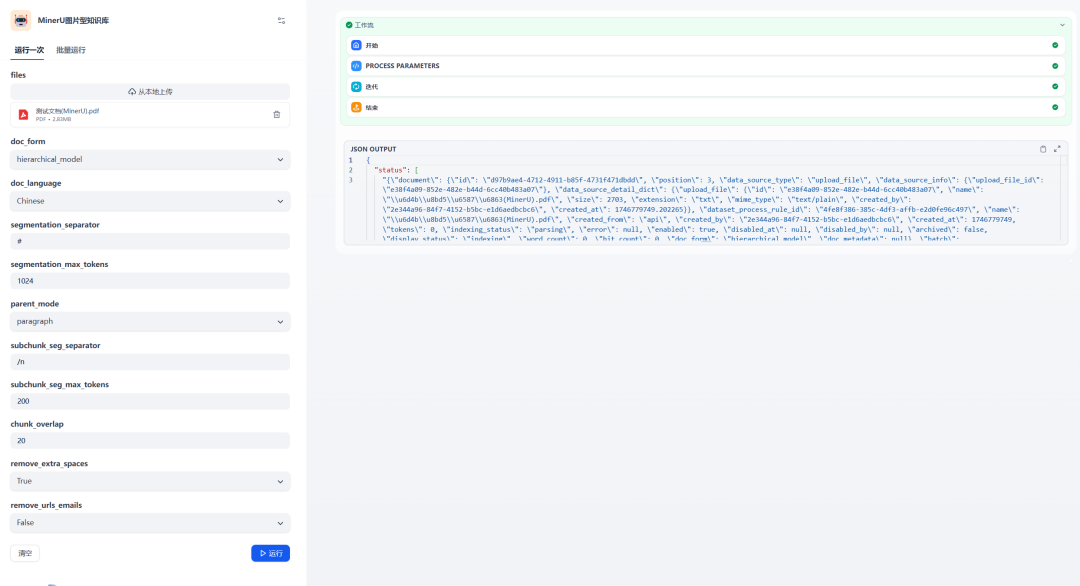
图6:通过MinerU工作流处理并创建文档的执行结果
上图显示,MinerU 工作流成功执行,并且接口调用返回了成功的结果。此时,可以前往知识库查看新创建的文档。
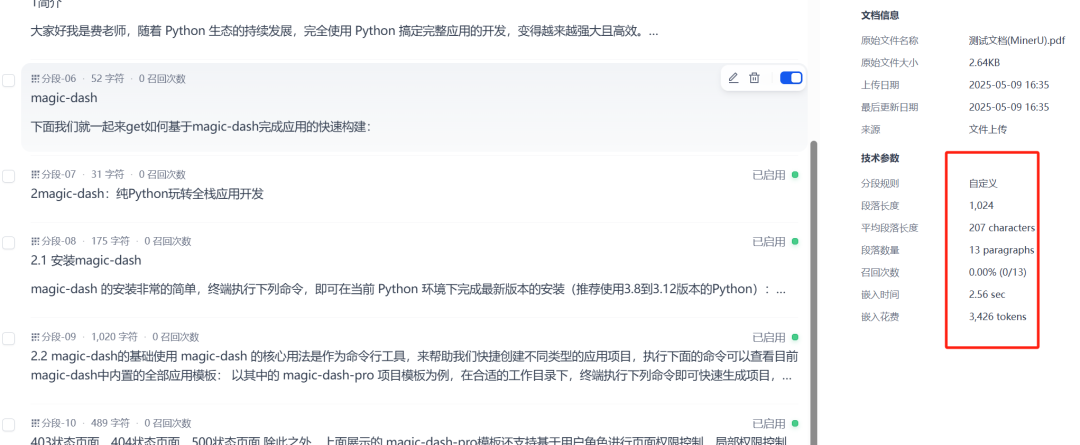
图7:在Dify知识库中查看到由MinerU工作流创建的文档
文档通过工作流创建并导入知识库后,Dify 会自动对其进行索引处理。等待索引完成后,便可以进行召回测试,检验知识库是否能够基于图片中的文本内容进行有效的问答或信息检索。
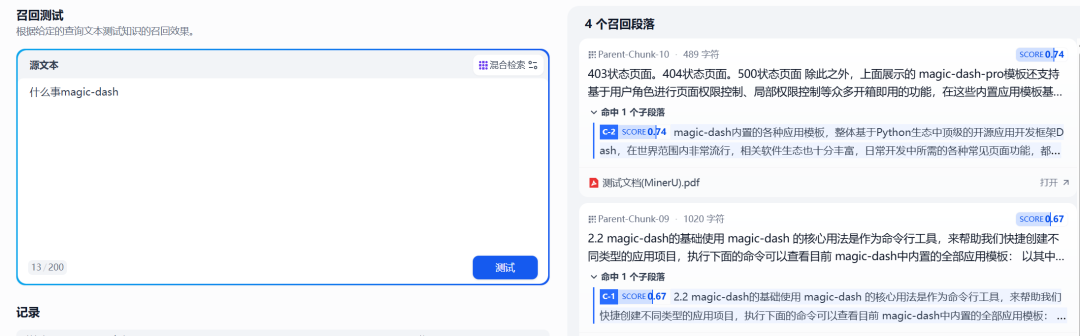
图8:对经过MinerU处理并入库的文档进行召回测试
测试结果表明,通过 MinerU 工作流处理后的文档,其包含的文本内容已被成功提取并索引,使得 Dify 知识库能够理解并回应基于这些原先为图片格式信息提出的问题。这显著增强了 Dify 知识库处理多样化文档类型的能力。