

As the paradigm of big language modeling and engineering practices evolve, a range of applications for intelligentsia designed to mimic the human research process have emerged. These intelligences are not just simple question-and-answer tools, but complex systems capable of planning, executing, reflecting and synthesizing information autonomously. In this paper, we will deconstruct the architectural design and functional implementation of different research-intelligent body frameworks, from the OpenAI Official release DeepResearch The guide is a source of ideas that analyzes the inherent differences and design philosophies of several mainstream open source frameworks, providing a systematic and strategic reference for developers and users when choosing tools.
Open Source Deep Research Intelligence Body Framework
Comparison of core concepts
There are numerous general-purpose smartbody frameworks currently on the market (e.g. Auto-GPT、AutoGen etc.) are capable of performing research tasks, but this paper focuses on six open source projects that have been optimized with specific architectures for deep research scenarios.
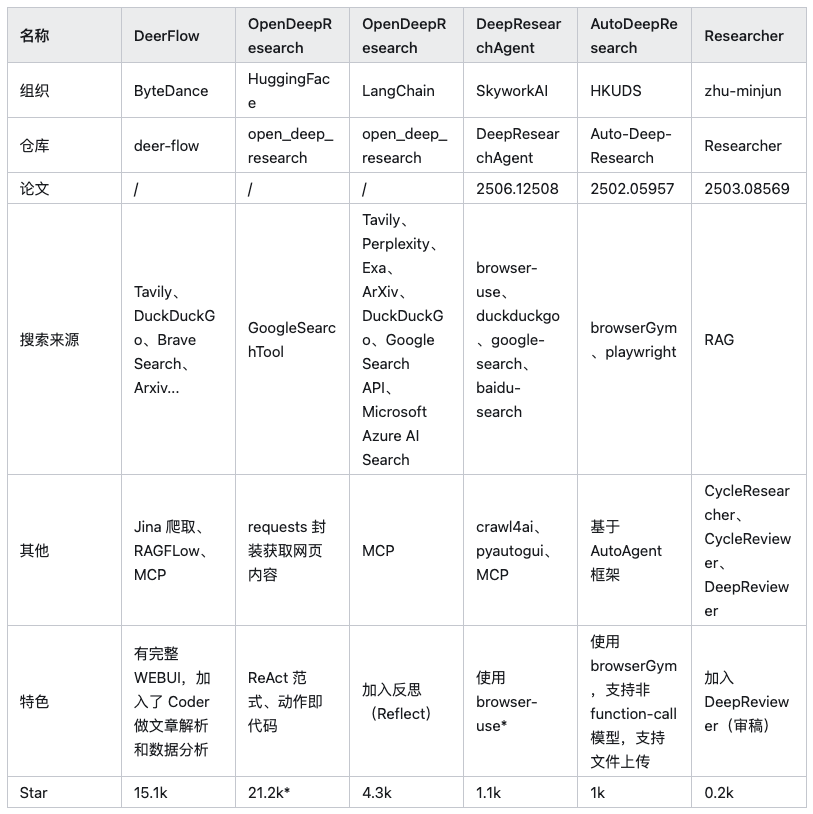
Note: In the above table HuggingFace/OpenDeepResearch The number of Stars comes from its core dependency on SmolAgents Project.
Before analyzing each framework in depth, one thing needs to be clear: the essence of in-depth research is information acquisition and integration. Therefore, a framework like browser-use Such AI-driven browser automation tools are an important adjunct to all such frameworks. They are responsible for performing tasks such as loading dynamic web pages, interacting with page elements, extracting data, etc., solving the problem of traditional web crawlers having difficulty in handling JavaScript The pain point of rendering content, but not the core of this article's discussion - the framework itself.
OpenAI Guide: Laying the Three-Step Paradigm
OpenAI The official documentation for the Deep Research guide, it proposes an architecture that is the source of ideas for almost all subsequent research-based intelligences. Its core idea is to abandon the illusion of solving problems in one step with a single, bulky Prompt, which is extremely fragile and difficult to debug. The guide advocates breaking down complex research tasks into three separate modular processes:Plan -> Execute -> SynthesizeThis is a typical "divide and conquer" strategy to overcome the inherent challenges of long-range reasoning and context length constraints in large language models. This is a typical "divide-and-conquer" strategy aimed at overcoming the inherent challenges of large language models in terms of long-range reasoning, factual consistency, and context length constraints.

- Plan: Use a higher-order model with a high degree of abstraction and logical reasoning (e.g., the
GPT-4o), breaks down the user's main problem into a series of specific, independently studyable, and exhaustive sub-problems. The quality of this step determines the breadth and depth of the research. - Execute: Process each subproblem in parallel. For each sub-problem, an external search API is called to obtain information and allow the model to perform initial summarization and fact extraction from a single source of information. This is a highly parallelized information gathering phase.
- Synthesize: Summarize the answers to all the sub-questions, and submit them again to the higher-order model for final integration, analysis and embellishment into a logically coherent and clearly structured final report.
Implementation Strategies and Best Practices
Based on this core structure, here are a few key strategies to practice:
1. Choosing the right model for the right task
This is the core of cost and performance optimization. Different phases require different types of "intelligence". The "Planning" and "Synthesis" phases require robustGlobal reasoning, logical organization and creative generative skillsThe following is an example of a program that must be used GPT-4o 或 GPT-4 Turbo These are the top models, as their performance determines the upper limit of the quality of the final report. In the "execution" phase, the task of summarizing individual web pages is more focused onInformation extraction and factual enrichmentUse GPT-3.5-Turbo or other faster models can dramatically reduce cost and latency while maintaining quality. A single deep research request can trigger dozens of API calls, and without model hierarchies, costs can quickly escalate.
2. Parallel processing to maximize efficiency
The subproblems of the study are usually independent of each other, and serial processing is extremely time-consuming. In the "execution" phase, once the list of subproblems has been generated, it should be programmed asynchronously (e.g., by the Python 的 asyncio) to initiate research requests in parallel. This can reduce a several-minute process to less than a minute. However, developers must be mindful of the API provider's Rate Limits, particularly the TPM (number of tokens processed per minute). Parallel calls can generate a large number of requests instantly, exceeding the TPM Limitations will result in request failures, so well-designed request queues and retry mechanisms are needed.
3. Ensure structured output using function calls or JSON patterns
To ensure a stable and reliable workflow, models should always be allowed to return machine-readable structured data, rather than having code parse unstable natural language text.OpenAI Function Calling" or "JSON mode" functionality is the best way to accomplish this. It's the equivalent of a function call between the code and the LLM This establishes a solid API contract. In the Planning phase, you can force the model to output a JSON list of all the subproblem strings, and in the Execution phase, you can require the model to return the results in a fixed JSON format, for example {"summary": "...", "key_points": [...]}。
4. Integration of high-quality external search tools
Language models do not inherently have real-time networking capabilities and their knowledge suffers from a lag. Therefore, it is important to integrate one or more high-quality search APIs (such as the Google Search API、Brave Search API、Serper etc.) to access real-time, extensive information. Explicitly informing the model in the cue that it can use these tools and returning the outputs of the tools to the model, e.g., through function calls, is the basis for empowering it with research capabilities.
5. Elaboration of prompts for each stage (Prompt Engineering)
Cue words are key to determining the quality of each stage. The cue words for each stage should be carefully designed to guide the model to play the right role and produce the desired results. The following sample inputs provided in the official guide are highly informative.
Initial Question.
Research the economic impact of semaglutide on global healthcare systems.
Do:
- Include specific figures, trends, statistics, and measurable outcomes.
- Prioritize reliable, up-to-date sources: peer-reviewed research, health
organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical
earnings reports.
- Include inline citations and return all source metadata.
Be analytical, avoid generalities, and ensure that each section supports
data-backed reasoning that could inform healthcare policy or financial modeling.
研究索马鲁肽对全球医疗保健系统的经济影响。
应做的:
- 包含具体的数字、趋势、统计数据和可衡量的成果。
- 优先考虑可靠、最新的来源:同行评审的研究、卫生组织(例如世界卫生组织、美国疾病控制与预防中心)、监管机构或制药公司
的盈利报告。
- 包含内联引用并返回所有来源元数据。
进行分析,避免泛泛而谈,并确保每个部分都支持
数据支持的推理,这些推理可以为医疗保健政策或财务模型提供参考。
Question Clarification.
The purpose of this step is for the intelligent body to act like a true advisor, making sure that the user's intentions are fully understood before beginning expensive research.
You are talking to a user who is asking for a research task to be conducted. Your job is to gather more information from the user to successfully complete the task.
GUIDELINES:
- Be concise while gathering all necessary information
- Make sure to gather all the information needed to carry out the research task in a concise, well-structured manner.
- Use bullet points or numbered lists if appropriate for clarity.
- Don't ask for unnecessary information, or information that the user has already provided.
IMPORTANT: Do NOT conduct any research yourself, just gather information that will be given to a researcher to conduct the research task.
您正在与一位请求开展研究任务的用户交谈。您的工作是从用户那里收集更多信息,以成功完成任务。
指导原则:
- 收集所有必要信息时务必简洁
- 确保以简洁、结构良好的方式收集完成研究任务所需的所有信息。
- 为清晰起见,请根据需要使用项目符号或编号列表。
- 请勿询问不必要的信息或用户已提供的信息。
重要提示:请勿自行进行任何研究,只需收集将提供给研究人员进行研究任务的信息即可。
User Prompt Rewriting.
This step translates the user's spoken request into a detailed and unambiguous written instruction to the Researcher Intelligence.
You will be given a research task by a user. Your job is to produce a set of
instructions for a researcher that will complete the task. Do NOT complete the
task yourself, just provide instructions on how to complete it.
GUIDELINES:
1. **Maximize Specificity and Detail**
- Include all known user preferences and explicitly list key attributes or
dimensions to consider.
- It is of utmost importance that all details from the user are included in
the instructions.
2. **Fill in Unstated But Necessary Dimensions as Open-Ended**
- If certain attributes are essential for a meaningful output but the user
has not provided them, explicitly state that they are open-ended or default
to no specific constraint.
3. **Avoid Unwarranted Assumptions**
- If the user has not provided a particular detail, do not invent one.
- Instead, state the lack of specification and guide the researcher to treat
it as flexible or accept all possible options.
4. **Use the First Person**
- Phrase the request from the perspective of the user.
5. **Tables**
- If you determine that including a table will help illustrate, organize, or
enhance the information in the research output, you must explicitly request
that the researcher provide them.
6. **Headers and Formatting**
- You should include the expected output format in the prompt.
- If the user is asking for content that would be best returned in a
structured format (e.g. a report, plan, etc.), ask the researcher to format
as a report with the appropriate headers and formatting that ensures clarity
and structure.
7. **Language**
- If the user input is in a language other than English, tell the researcher
to respond in this language, unless the user query explicitly asks for the
response in a different language.
8. **Sources**
- If specific sources should be prioritized, specify them in the prompt.
- For product and travel research, prefer linking directly to official or
primary websites...
- For academic or scientific queries, prefer linking directly to the original
paper or official journal publication...
- If the query is in a specific language, prioritize sources published in that
language.
6. Introducing human-in-the-loop audits at key nodes
For serious or high-risk research tasks, fully automated processes are unreliable. Introducing a "human loop" is not just a feature, but a philosophy of human-machine collaboration. An effective practice is to include a human review process after the "planning" phase, where the user reviews, modifies and validates the list of sub-problems generated by the model to ensure that the direction of the research is correct, before initiating the costly "execution" phase. This avoids "garbage in, garbage out" and ensures accountability of the final results.
Open Source Architecture Analysis
Below we dissect the architectural features of each framework in turn.
ByteDance/DeerFlow: Graph-based hierarchical multi-intelligent body system
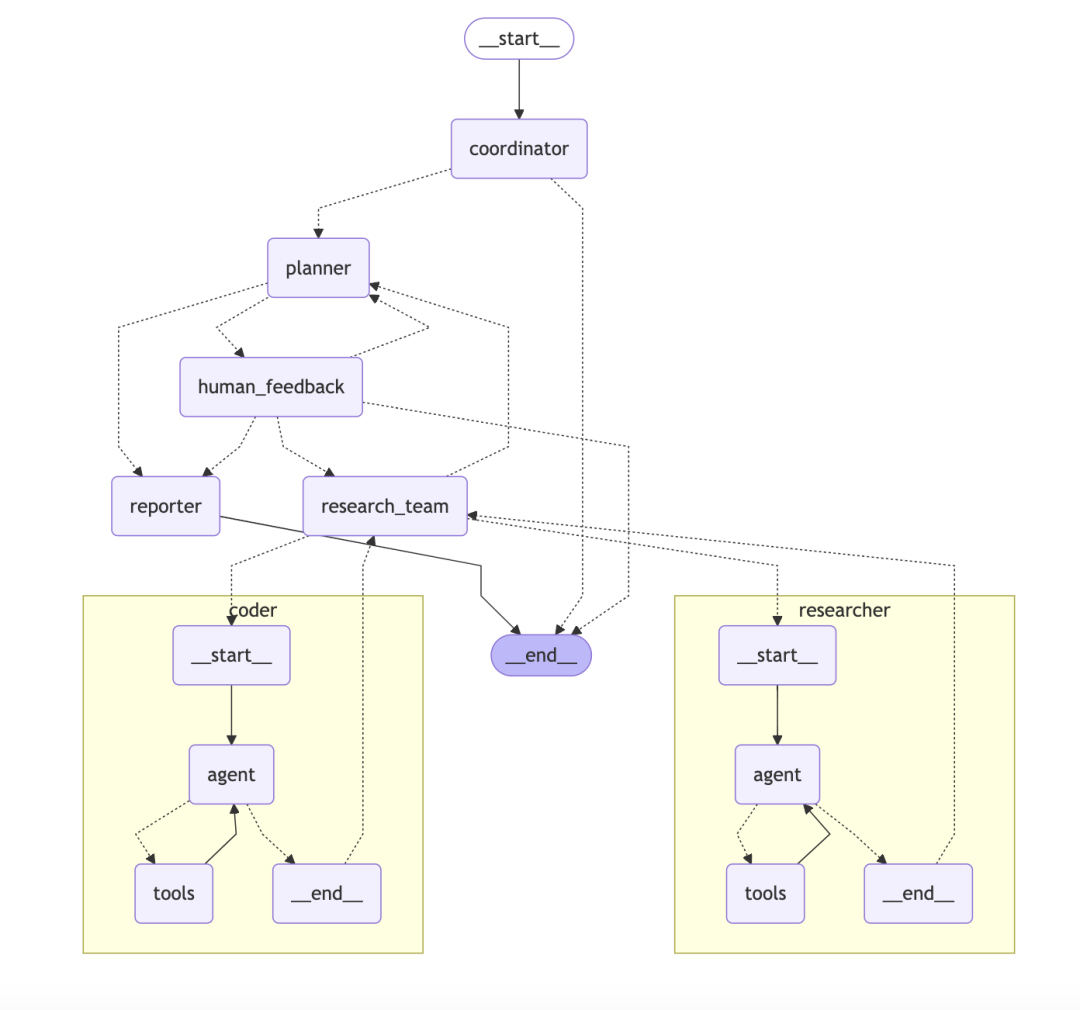
DeerFlow The architecture is a modular hierarchical multi-intelligent body system, like an automated research team with clear goals and a clear division of labor.
- core architecture:: The system consists of multiple roles working together:
- Coordinator:: Act as project manager, receive user requests, initiate and manage the process.
- Planner:: As a strategist, break down complex problems into structured steps.
- Research Team:: As the executor, there are "researchers" who search the web and "programmers" who execute the code.
- Reporter: As the final output, consolidate all the information into reports, podcasts and even PPTs.
- Technical characteristics:
DeerFlowThe technological highlight is that it is built onLangChain和LangGraphAbove.LangGraphis a key component that allows developers to build multi-intelligencer workflows into theStateful GraphsEach intelligence or tool can be thought of as a node in the graph. Each intelligence or tool can be considered as a node in the graph, and the direction of the workflow is defined by edges. This approach naturally supports complex processes that include loops, such as the Reflect-Correct loop, making the entire research process not only linear, but also traceable and debuggable.
Columnist's Commentary: DeerFlow The design is clear and well-defined for teams or enterprise applications that need to be stable, scalable and support complex workflows. It does this by introducing LangGraphThis elevates intelligent body collaboration from a simple chain call to a manageable, cyclic graphical network that is more like a "research process management platform" than a simple tool.
HuggingFace/OpenDeepResearch: The minimalist philosophy of code-as-action
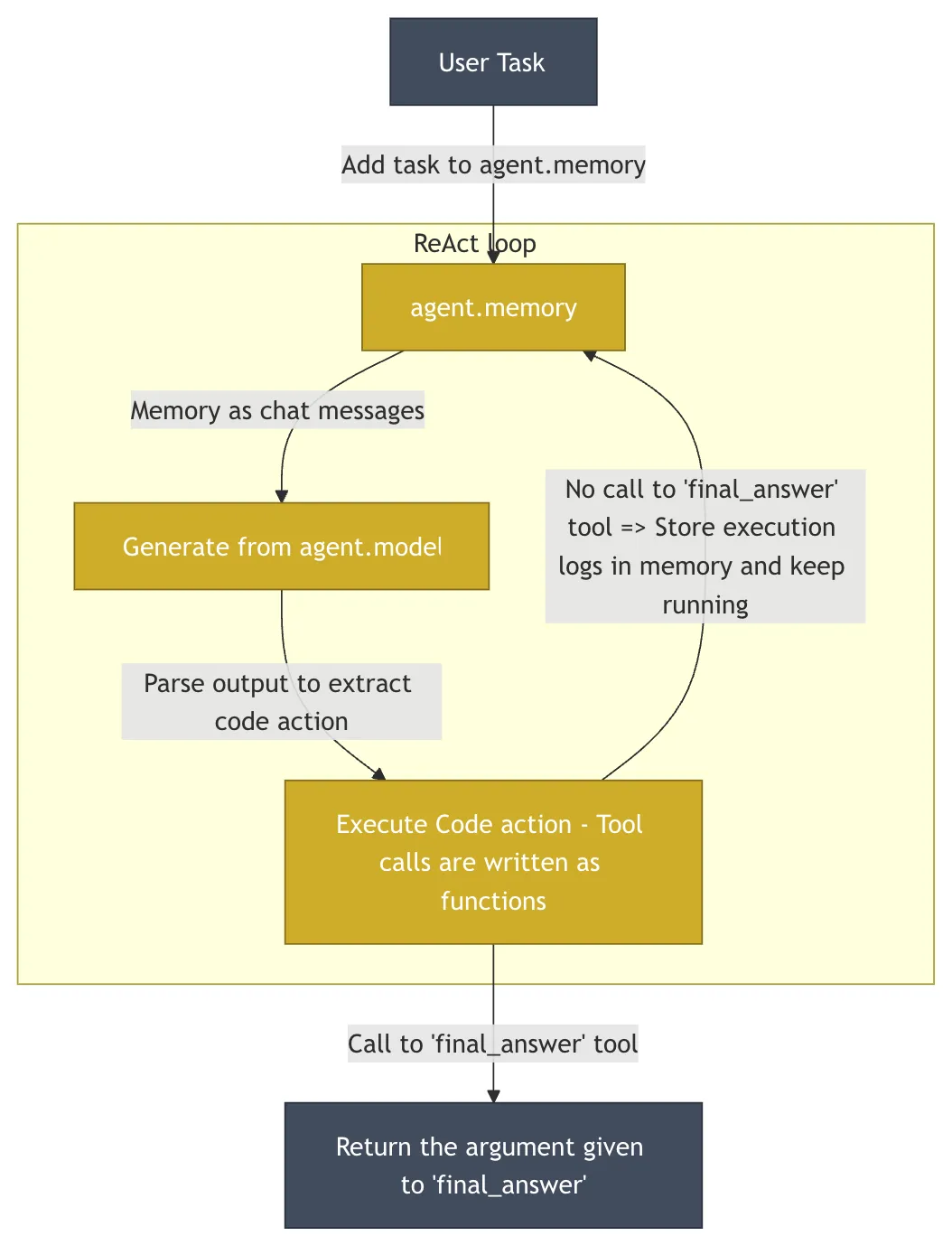
HuggingFace 的 OpenDeepResearch The project, the core of which consists of smolagents Driven, taken in conjunction with DeerFlow very different design philosophies. The project is in GAIA (General AI-Assisted Agent)-an authoritative benchmark designed to measure the capabilities of general AI intelligences through real-world tasks-was achieved on the validation set of the 55% pass@1 score. This score is lower than the ChatGPT 的 67%, but as an open source implementation, has demonstrated its power.
- core idea: Simplicity and minimal abstraction.
smolagents's codebase is deliberately kept very small (~1000 lines), avoiding the over-abstraction that is common in many frameworks, and providing developers with a very high degree of transparency and control. - core architectureAt the heart of it is the "Code Intelligence" (
CodeAgent). The actions of the intelligibles are directly expressed asPythoncode snippet instead of theJSONObject.LLMGenerate a small paragraphPythoncode to perform the next action. This approach is far more expressive thanJSONBecause code naturally supports complex logic such as loops, conditionals, and function definitions. However, executing arbitrary code generated by AI carries significant security risks. For this reason.smolagentsSupport in areas such asE2Bthis kind ofSandbox Run the code in theE2BProvide an isolated cloudLinuxenvironment in which the AI-generated code executes, with access to the file system and network but no ability to affect the host system, thus ensuring security while empowering the intelligence.
Columnist's Commentary: smolagents The "code is action" concept is an attractive way to return to the essence of programming and give intelligences more flexibility than ever before. It's a great choice for developers who want deep customization and complete control over the behavior of their intelligences. The philosophy is to give developers the most power and provide safety guardrails.
LangChainAI/OpenDeepResearch: Diagrammatic Workflows and Metacognitive Reflection
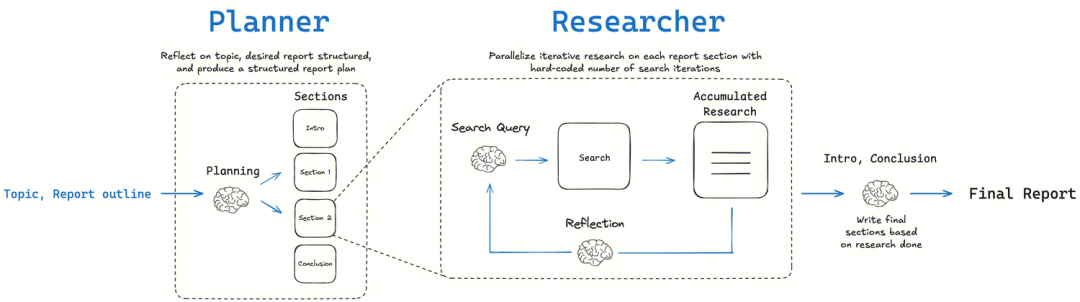
LangChain community-based open_deep_research At the core of the project is a multi-stage, iterative and self-reflective workflow designed to mimic the research process of a human expert.
- Core concepts: Plan-Search-Reflect-WriteThe key to this structure is the "reflection" component. The key to the structure is the "reflection" component. It's not just about checking for errors, it's aboutMetacognition The expression of this is "thinking about one's own thinking process". After gathering initial information, the intelligence evaluates the completeness of the current information, and whether there are any contradictions or gaps in knowledge. If it finds deficiencies, it generates a new, more precise search query and moves on to the next iteration.
- implementation method:
- Graph-based Workflow: as
DeerFlowIt is mainly usedLangGraphBuild. Each step of the study is modeled as a node in the graph, making the entire process highly visual, traceable and easy to debug. This approach is ideally suited for scenarios that require human intervention and high-precision control. - Multi-agent Iterative Loop: Through recursive research loops, the intelligence evaluates existing information, generates new questions, and searches further in each loop. This approach is categorized into two modes:
简单模式 (Simple)Direct access to a single iterative loop is fast and suitable for specific problems;深度模式 (Deep)Includes initial planning and deploys parallel researchers for each sub-topic, more in-depth and comprehensive for complex topics.
- Graph-based Workflow: as
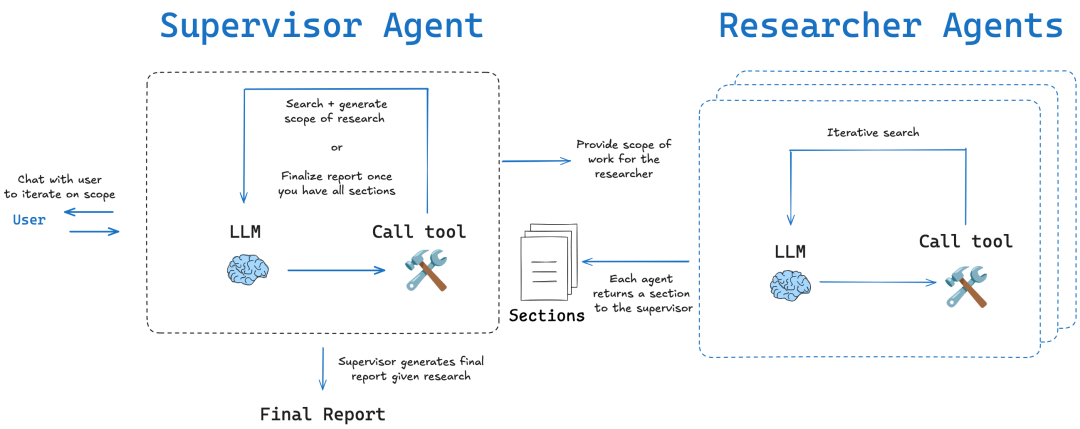
Columnist's Commentary: LangChain This version is a great example of modularity and flexibility. It successfully engineers the cognitive science concept of "self-reflection" through the use of LangGraph Provides powerful modeling capabilities for complex, non-linear research tasks and is ideal for teams that need to productize their research processes.
SkyworkAI/DeepResearchAgent: Classical Layering and Separation of Concerns
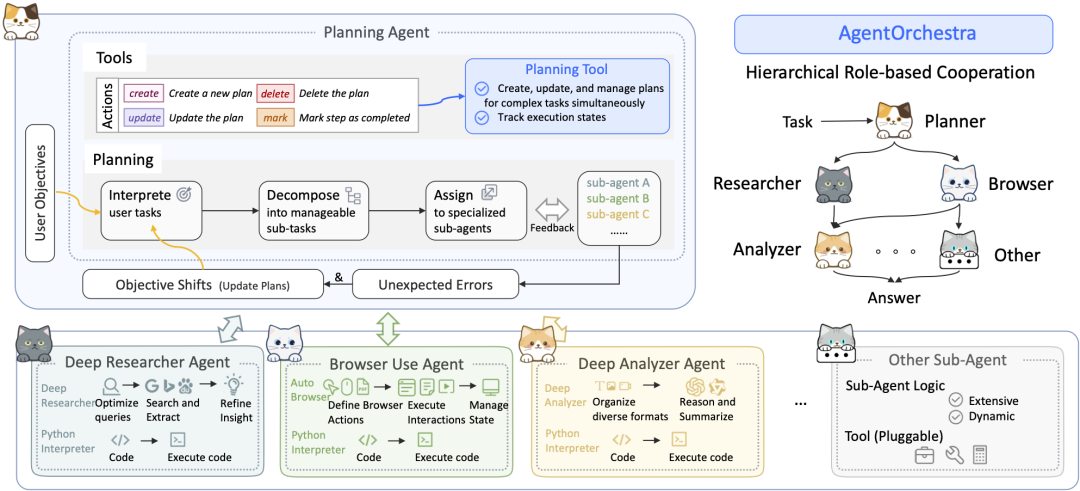
SkyworkAI 的 DeepResearchAgent An explicit two-layer (Two-Layer) architecture is used, which is a very classic design pattern in software engineering, and is centered on theSeparation of Concerns。
- core architecture:
- Layer 1: Top-Level Planning Agent:: Acts as the "strategy layer" or "business logic layer". Instead of performing specific research tasks, it is responsible for understanding user intent, breaking down ambitious goals into a series of manageable subtasks, and developing workflow plans.
- Lower-Level Agents (Specialized Lower-Level Agents):: Plays the role of an "execution layer" or "service layer". It consists of multiple intelligences with different specialized skills, such as "deep analyzer" for information analysis, "deep researcher" for web search, and "browser user" for browser operation, which faithfully carry out the tasks assigned by the upper layer. "They faithfully carry out the tasks assigned by the upper layers.
- Architecture Inspiration:: The project has been implemented in its
READMEIt is explicitly mentioned in its architecture that it is subject tosmolagentsinspired by its modularity and asynchronous improvements. This reflects its attempt to combinesmolagentsThe simplicity of the concept with a more structured model of multi-intelligent body collaboration.
Columnist's Commentary: DeepResearchAgent The two-tier architecture realizes a beautiful decoupling between "planning" and "execution". The design is well-organized and scalable, and in the future it will be easy to add more specialized intelligence (e.g., data visualization, code execution, etc.) to the second tier without having to change the core planning logic at the top tier. This is a pragmatic and engineered implementation.
zhu-minjun/Researcher: confrontational self-criticism mechanisms
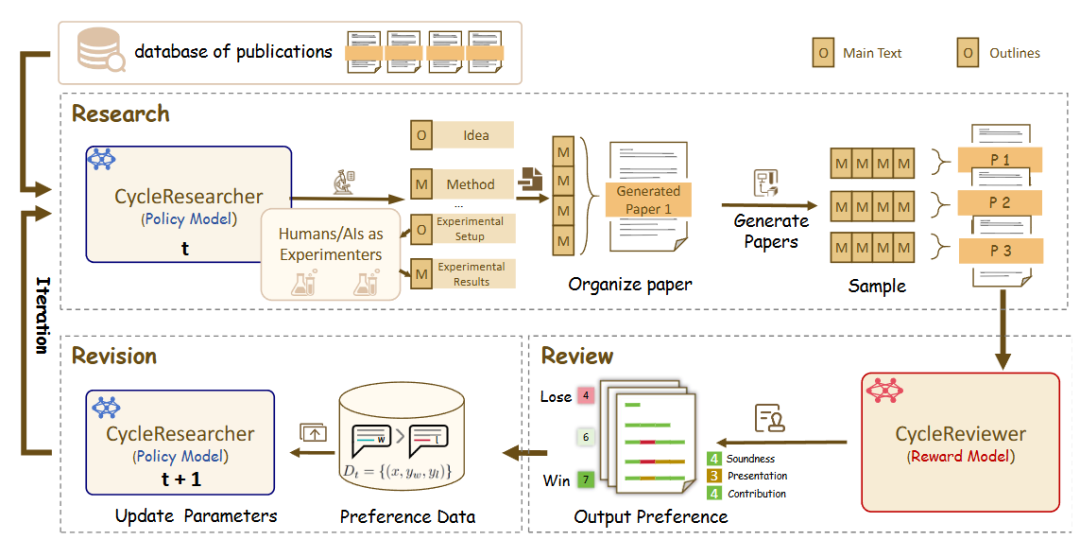
zhu-minjun/Researcher 's architecture is similarly staged multi-intelligence collaboration, but its most notable feature is the introduction of independent, what might even be calledConfrontational "self-criticism" sessions。
- core architecture:
- Planning Intelligence:: Development of a research plan and outline.
- Parallel Execution Intelligence:: Launch independent executive intelligences for each sub-theme to collect information in parallel.
- Integration and first draft generation:: Synthesize all results into a first draft.
- Critical and Revisionist Intelligence:: This is the highlight of the architecture. It visualizes "reflection" as an independent "critical intelligence". This intelligence acts as a rigorous and skeptical reviewer who challenges the quality of the first draft, suggesting specific and constructive changes based on predefined rules (e.g., factual accuracy, objectivity, completeness of the logic chain, and the presence of bias). The system then makes corrections based on this feedback, creating a closed loop of iterative optimization.
- DeepReviewer: In its
Bestmode, the project is passed through a file namedDeepReviewermodule to achieve this comprehensive auditing experience, which can even simulate themulti-auditor simulation, stress-testing the report, which is similar to the peer review (Peer Review) process in academia.
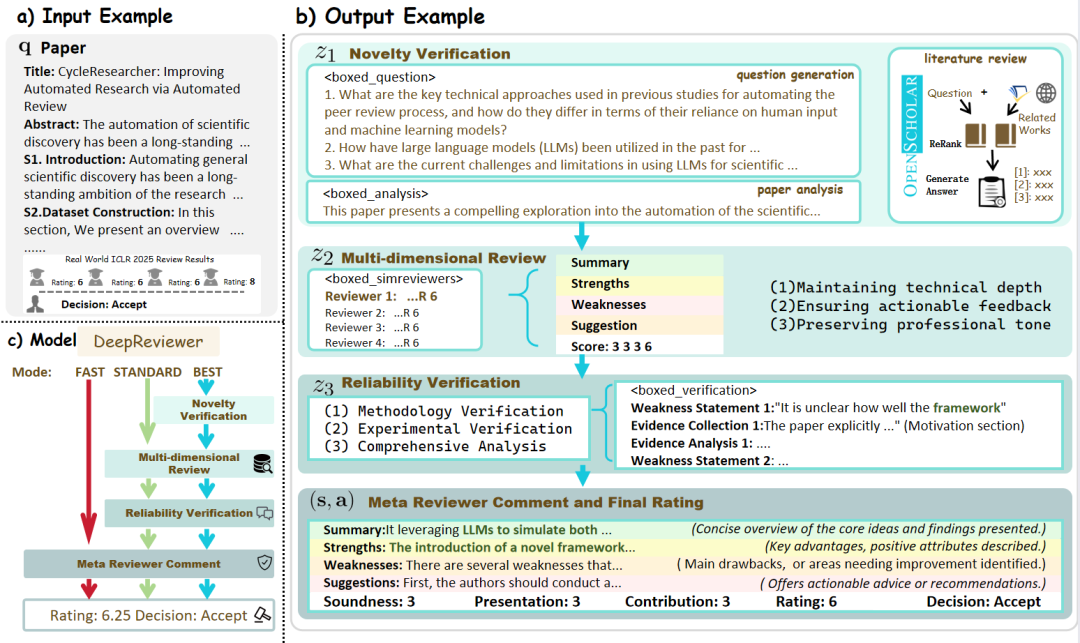
Columnist's Commentary:: The project upgrades "reflection" from an internal state to an external, structured process of confrontation. This "left-right" design makes it not only an information aggregator, but also a "researcher" who constantly challenges himself to improve the quality of his content and strive for objectivity and comprehensiveness.
Commercialization In-Depth Research Intelligent Body Watch
After analyzing open source frameworks for developers, commercialized applications for end-users provide a more seamless, product-oriented experience.
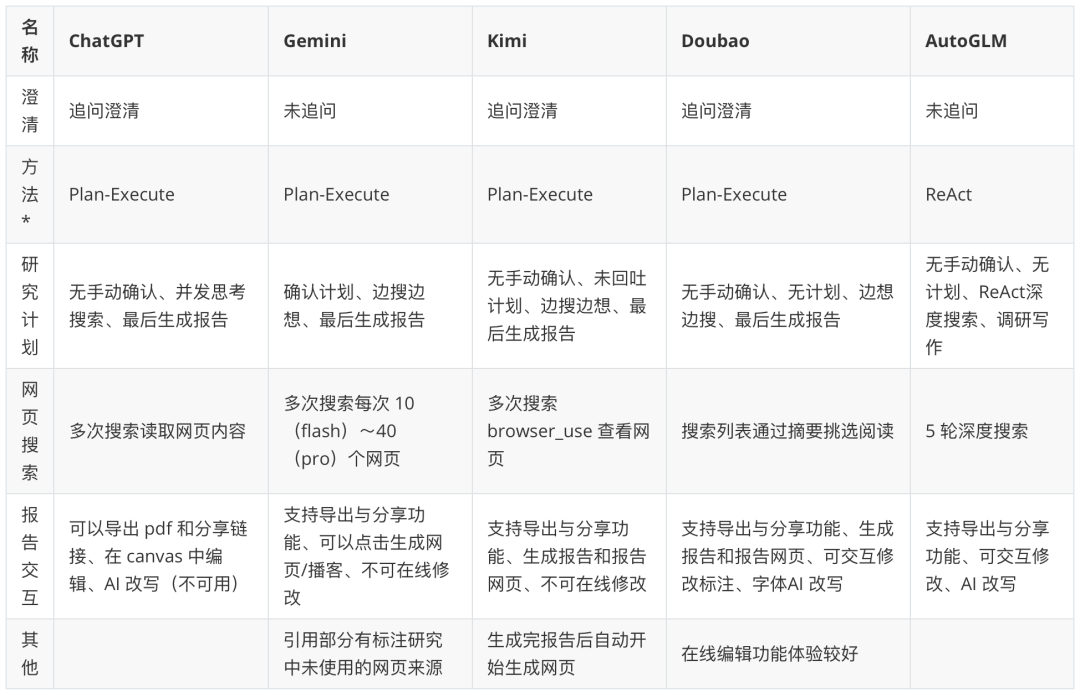
Note: The "Intelligent Body Paradigm" in the table is a speculation based on product behavior. Follow more great in-depth research on intelligences: https://www.kdjingpai.com/ai-learning/research-assistant/
While open source frameworks expose the "engine", commercial products elegantly hide the "engine" under a beautiful "cockpit". Take Kimi As an example, it handles deep research problems without the user needing to care about the planning, execution, and synthesis steps behind the scenes. The user asks a complex question, theKimi Automates the internal research process: planning search terms, accessing multiple web sources concurrently, digesting and integrating information in real time using its multi-million word contextual window, and finally presenting a comprehensive answer with cited sources in a smooth conversational format.
Other products such as ChatGPT、Gemini etc., are also passing CoT (Chain of Thought),Tree of Thoughts or internally integrated multi-intelligence processes that continually improve their ability to accomplish complex research tasks. Commercial products compete on the accuracy and real-time nature of search results, the depth and insight of information integration, and the interactivity of the final report (e.g., clickable citations, chart generation, follow-up suggestions, etc.). They take the complex architecture of the open source world and package it into powerful features that are within reach of the average user.




























