



ShareGPT-4o-Image is a large multimodal image generation dataset open-sourced by the FreedomIntelligence team on GitHub, containing 91K high-quality samples built on the image generation capabilities of GPT-4o. The dataset is divided into 45K text-to-image samples and 46K text-plus-image-to-image samples, and is designed to help the open-source multimodal model align with GPT-4o's image generation capabilities. The team also developed the Janus-4o model based on this dataset, which supports text-to-image and image editing capabilities and outperforms its predecessor, Janus-Pro. The project is dedicated to advancing the multimodal AI community through open-source data and models, and providing high-quality resources for research and development.
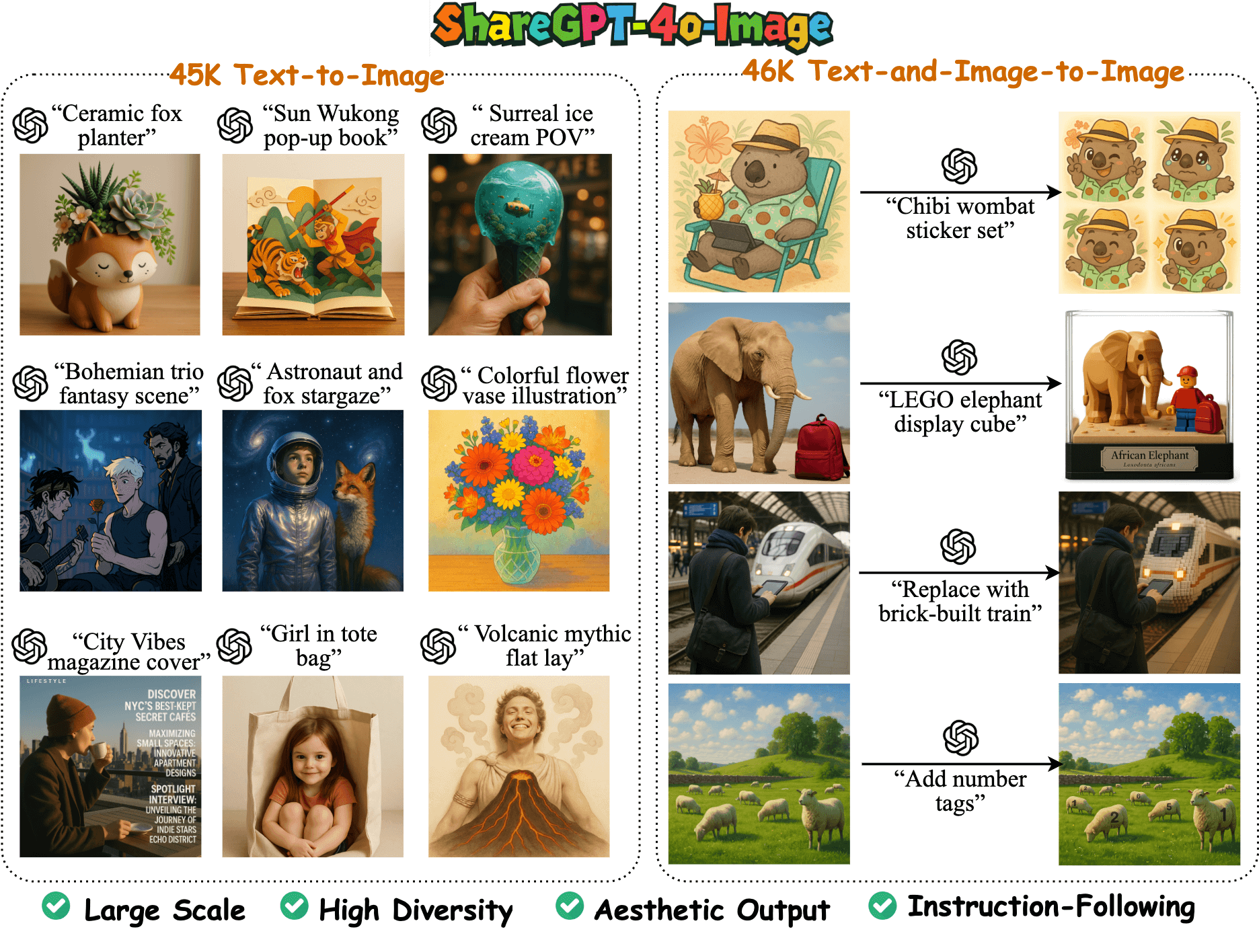
Function List
- Provides 91K high-quality image generation samples, including 45K text-to-image and 46K text plus image-to-image samples.
- Supports training and optimization of open source multimodal models to enhance image generation and editing.
- Includes Janus-4o model with support for text-to-image generation and text-plus-image-to-image editing.
- The dataset is available for download on Hugging Face in the format of a Parquet file, which is approximately 20.7 MB in size and contains 92,256 rows of data.
- Provides detailed documentation and code examples to support developers in getting up to speed quickly with datasets and models.
- The open source code and models are hosted on GitHub and Hugging Face for easy community contributions and extensions.
Using Help
Dataset Acquisition and Installation
The ShareGPT-4o-Image dataset is freely available on Hugging Face or GitHub. Here are the exact steps:
- Access to data sets:
- Open the Hugging Face page: https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image.
- Or visit the GitHub repository at https://github.com/FreedomIntelligence/ShareGPT-4o-Image.
- The dataset is stored in Parquet format and is approximately 20.7 MB in size, containing 92,256 rows of data.
- Download Dataset:
- On the Hugging Face page, click the "Download" button to download the Parquet file directly.
- Or use the Git command to clone your GitHub repository:
git clone https://github.com/FreedomIntelligence/ShareGPT-4o-Image.git - Once downloaded, unzip the file (if necessary) and make sure the Parquet file is readable by the Python environment.
- environmental preparation:
- Install Python 3.7 or later.
- Install the necessary dependency libraries, e.g.
pandas和datasetsto load and process Parquet files:pip install pandas datasets - If using the Janus-4o model, you need to install the
torch和transformers:pip install torch transformers
- Load Data Set:
- Using Python's
datasetsThe library loads the dataset:from datasets import load_dataset dataset = load_dataset("FreedomIntelligence/ShareGPT-4o-Image") print(dataset) - The dataset contains correspondences between textual cues and generated images that can be used directly for model training or analysis.
- Using Python's
Using the Janus-4o model
Janus-4o is a fine-tuned multimodal model based on the ShareGPT-4o-Image dataset that supports text-to-image generation and image editing. The following are the specific steps:
- Loading Models:
- Download the Janus-4o-7B model from Hugging Face:
from transformers import AutoModelForCausalLM, VLChatProcessor model_path = "FreedomIntelligence/Janus-4o-7B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained( model_path, trust_remote_code=True, torch_dtype=torch.bfloat16 ).cuda().eval() - Make sure your device supports GPUs and has CUDA installed, otherwise use a CPU (slower performance). [](https://huggingface.co/FreedomIntelligence/Janus-4o-7B)
- Download the Janus-4o-7B model from Hugging Face:
- Text-to-Image Generation:
- Use the provided
text_to_image_generatefunction generates the image:def text_to_image_generate(input_prompt, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5): torch.cuda.empty_cache() conversation = [{"role": "<|User|>", "content": input_prompt}, {"role": "<|Assistant|>", "content": ""}] sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts( conversations=conversation, sft_format=vl_chat_processor.sft_format, system_prompt="" ) prompt = sft_format + vl_chat_processor.image_start_tag # 后续生成步骤参考 GitHub 文档 - Enter sample prompts such as "A picture of a beach at sunset with coconut trees on the sand and a sailboat in the distance".
- The generated image will be saved to the specified
output_path。
- Use the provided
- Text plus image to image editing:
- Janus-4o supports image editing based on input images and text prompts. For example, enter a landscape image and the prompt "Replace sky with stars".
- The process is similar to text-to-image, but you need to provide an additional path to the image, refer to the GitHub repository for examples.
- View Document:
- Visit the README file in the GitHub repository for detailed model parameters and instructions for generating the setup.
- The Hugging Face page also provides the dataset structure and sample previews for easy understanding of the data format.
caveat
- The datasets and models require a stable network environment to download.
- Accelerated model inference using the GPU, at least 16GB of video memory is recommended.
- If you encounter problems loading or generating models, you can refer to the GitHub Issues page or submit feedback on the problem.
- The dataset and model are open source, and the community encourages contributions of code or improvements to the dataset.
application scenario
- Multimodal Model Development
Developers can use the ShareGPT-4o-Image dataset to train or fine-tune their own multimodal models to enhance text-to-image generation or image editing for scenarios such as generating artwork, design sketches, and more. - academic research
Researchers can use the dataset to analyze the image generation patterns of GPT-4o and explore the semantic alignment and generation quality of multimodal models, which is suitable for academic research in the fields of artificial intelligence and computer vision. - Creative Content Generation
Designers or content creators can use Janus-4o models to quickly generate high-quality images based on textual descriptions or stylized edits to existing images for applications in advertising, games, or film production. - Education and teaching
Teachers and students can use the datasets and models to experiment with AI lessons, learn how multimodal models work, and practice text-to-image generation and image editing tasks.
QA
- Is the ShareGPT-4o-Image dataset free?
Yes, the dataset is completely open source, freely available for download and use at Hugging Face and GitHub under the Apache-2.0 license. - How does the Janus-4o model compare to GPT-4o?
Janus-4o is an open-source model fine-tuned based on the ShareGPT-4o-Image dataset, which supports text-to-image and image editing, but is still slightly inferior to GPT-4o in terms of overall performance. - What hardware is needed to run Janus-4o?
CUDA-enabled GPUs (at least 16GB of RAM) are recommended for optimal performance; CPUs can run it as well, but at a slower speed. - How do I contribute to the project?
Pull Requests can be submitted to the GitHub repository to contribute code, optimize models, or supplement datasets, as described in the repository's contribution guidelines.































