

Many users are uploading important data (such as plain image files or scanned PDF documents) to the LLM application development platform. Dify A tricky problem is often encountered when the knowledge base of theDify It is not possible to read and parse these non-text formats directly. This is mainly due to the Dify s knowledge base native functionality is more focused on processing and understanding plain text data. To overcome this limitation, it is possible to introduce MinerU-API tool that empowers Dify Knowledge Base's powerful Optical Character Recognition (OCR) capabilities. Next, details will be given on how to build a workflow that enables the Dify The Knowledge Base is capable of effectively parsing text information in images and scanned documents. This tutorial is based on the Dify Version 1.3.1.
preliminary
There are two key preparations that need to be completed before you can start building your workflow: deploying the MinerU-API Service and Creation Dify Knowledge Base.
Deploying MinerU-API
MinerU-API is a tool that supports multiple format document parsing (including OCR). For its detailed introduction and steps to get the code, you can refer to the two related articles "Extracting PDF with MinerU in Dify" and "MinerU-API | Supporting Multi-Format Parsing to Further Enhance Dify's Document Capabilities". This assumes that the user has obtained MinerU-API code and briefly describe its Docker Deployment Command.
docker run -d --gpus all --network docker_ssrf_proxy_network --name mineru-api -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3
This command will start a command in the background called mineru-api 的 Docker container and allocates GPU resources (if available) while connecting it to the specified network and mounting a data volume for persistent PaddleOCR of relevant data.
Creating a Dify Knowledge Base
First, in the Dify A new knowledge base is created in the platform. The creation process involves setting up the underlying Embedding model, which is responsible for converting text data into high-dimensional vectors for semantic understanding and similarity calculation by the machine, and the Rerank model, which is used to reorder the initial retrieval results to improve the accuracy and relevance of the final answers.

Figure 1: Create Dify knowledge base interface
Once the knowledge base has been created, open the knowledge base with the browser'saddress barThis ID is an important parameter for subsequent API calls.

Figure 2: Getting the knowledge base ID from the browser address bar
Next, navigate to theKnowledge Base -> API Settings screen to generate a new API key. This key will be used to authorize the various operations performed by the workflow on the knowledge base.
Figure 3: Generate Knowledge Base API Key Interface
Building MinerU Knowledge Base Workflows
Workflow Overview
The constructed workflow consists of three key code execution nodes that work together to parse and library an image or scanned document.
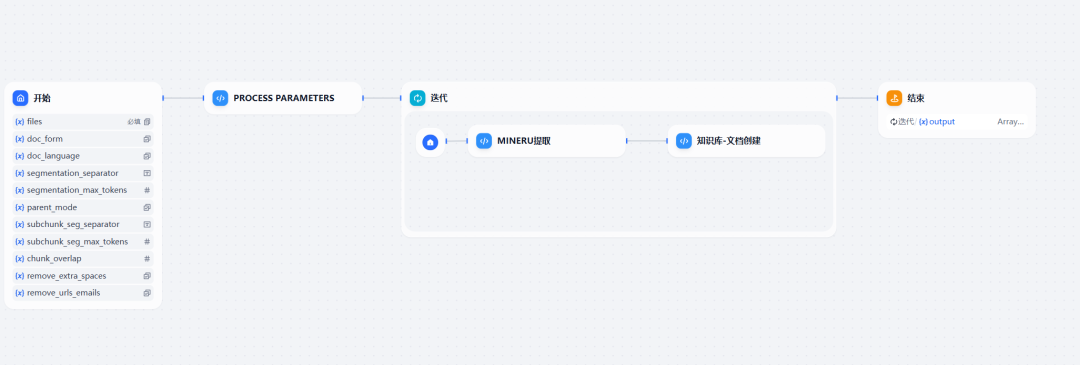
Figure 4: Overview of MinerU knowledge base workflow
The functions of each of the three code blocks are as follows:
- Process Parameters: This node is mainly responsible for handling calls to
DifyCreate a document interface (/datasets/{dataset_id}/document/create-by-text) when the required parameters. - MinerU extraction: The core task of this node is to call
MinerU-APIA service that converts incoming PDF or image files into plain text content in Markdown format using OCR technology. - Knowledge Base - Document Creation: This node is created by calling the
Difyflat-roofed/datasets/{dataset_id}/document/create-by-textAPI interface, which will be defined in the previous step by theMinerUThe extracted text content is created as a new document in the knowledge base. The following is sample Python code for this node:
import requests
def main(api_key, file_name, content, api_params, dataset_id):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
# 更新API参数,加入文件名和提取的文本内容
api_params.update({
"name": file_name,
"text": content,
})
# 构建Dify API的请求URL
# 注意:实际部署时,'http://api:5001' 可能需要根据Dify服务的实际地址和端口进行调整
url = f'http://api:5001/v1/datasets/{dataset_id}/document/create-by-text'
response = requests.post(
url,
headers=headers,
json=api_params,
)
return {"result": response.text}
Effectiveness Test
In order to verify the effectiveness of the workflow, take a PDF document directly printed from a web page as an example, and compare it with a PDF document directly uploaded to the Dify The knowledge base is the same as the knowledge base created through the newly created MinerU The effect of workflow processing.
The effect of directly uploading a knowledge base:
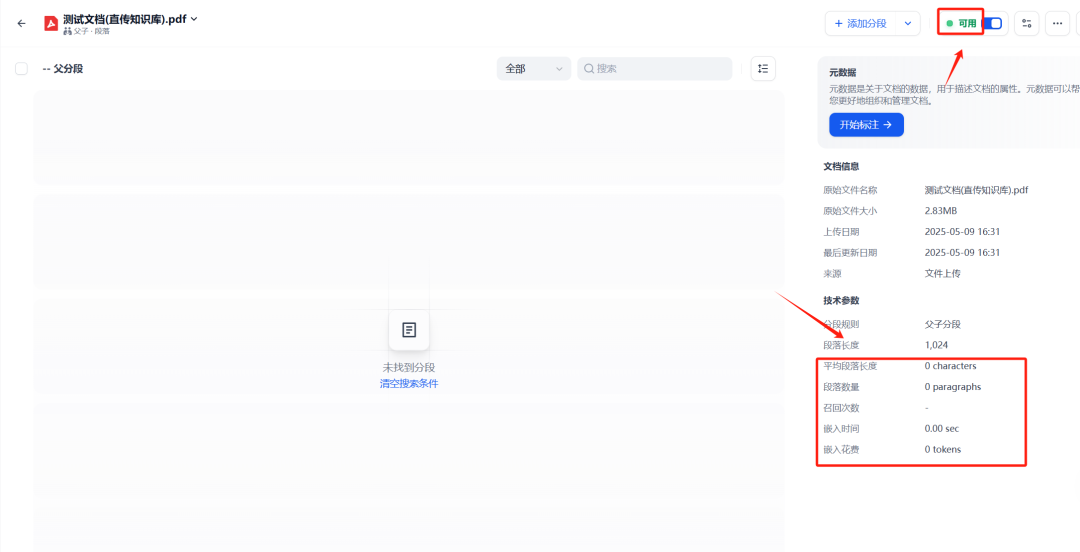
Figure 5: directly upload PDF documents to the Dify knowledge base after the state of the
As you can see from the image above, even though the document was successfully uploaded, the Dify The native Knowledge Base capabilities were unable to parse any of the text in the scanned PDF, leaving the document virtually blank in the Knowledge Base.
The effect of creating a document through a MinerU workflow:
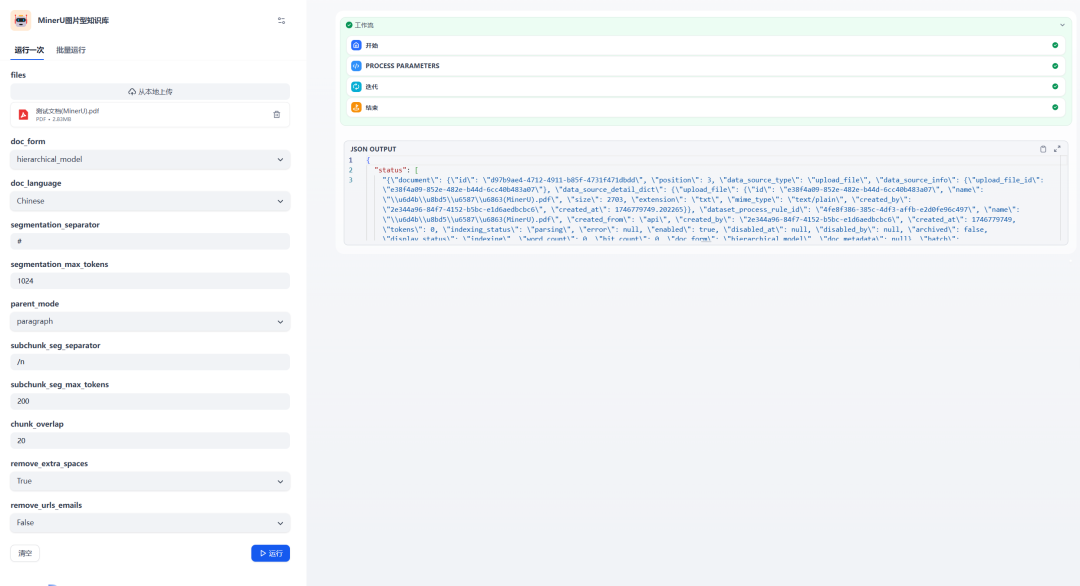
Figure 6: Execution results of processing and creating documents through MinerU workflow
The chart above shows thatMinerU The workflow executed successfully and the interface call returned a successful result. At this point, you can go to the Knowledge Base to view the newly created document.
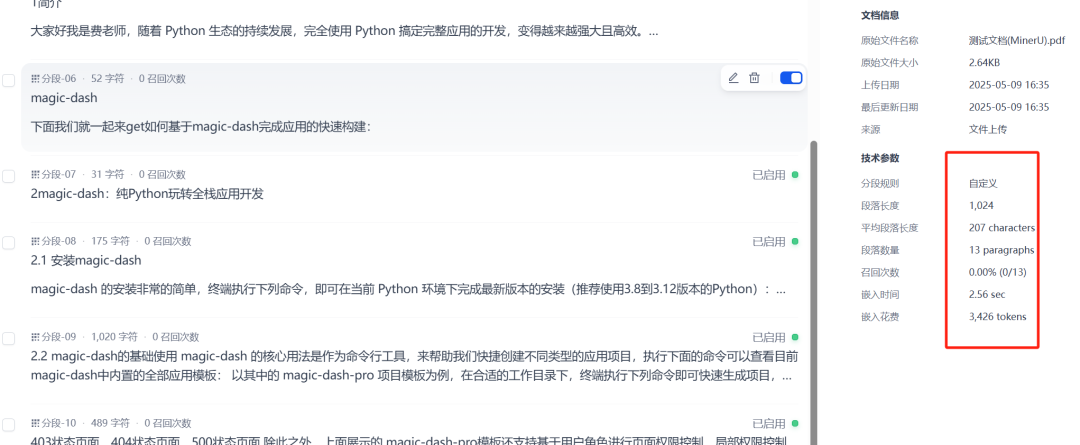
Figure 7: Viewing a document created by a MinerU workflow in the Dify Knowledge Base
After a document is created through a workflow and imported into the knowledge base, theDify It will be automatically processed for indexing. After waiting for the indexing to complete, a recall test can be performed to check whether the knowledge base is able to perform effective Q&A or information retrieval based on the text content in the images.
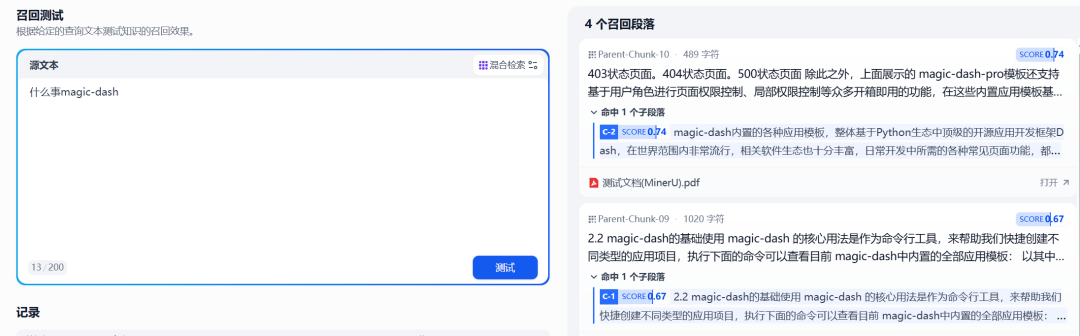
Figure 8: Recall testing of documents processed and warehoused by MinerU
The test results show that by MinerU Workflow processed documents that contain textual content that has been successfully extracted and indexed, making the Dify The knowledge base is able to understand and respond to questions based on these originally posed for image format information. This significantly enhances the Dify The ability of the knowledge base to handle diverse document types.

































