



MedGemma is a set of open source AI models released by Google on the Hugging Face platform, focusing on text and image understanding in the medical field. It is based on Gemma 3 Model Development, designed to help developers build healthcare-related AI applications MedGemma offers several model variants, including a 4B-parameter multimodal model and a 27B-parameter text and multimodal model. These models are specifically trained on medical text, electronic health records (EHRs), and a variety of medical images such as X-rays, dermatology images, ophthalmology images, and histopathology slides. Developers can use these models to accelerate the development of medical AI applications such as radiology report generation, medical Q&A, and image classification, etc. MedGemma's open source nature makes it easy to access and suitable for researchers and developers to run on a single GPU, lowering the development barrier.
Function List
- Medical Text Processing: Analyze and generate medical-related text content such as medical reports, Q&A pairs, and electronic health records.
- Medical Image Understanding: Supports analysis of a wide range of medical images, including chest X-rays, dermatology images, ophthalmology images, and histopathology slides.
- Multimodal Reasoning: Combines text and image data to provide integrated medical reasoning capabilities, such as generating radiology reports or interpreting image content.
- Choice of model variants: 4B-parameter multimodal models (pre-trained and command-tuned versions) and 27B-parameter text and multimodal models (command-tuned versions only) are available.
- Efficient inference optimization: Models are optimized to run on a single GPU, reducing compute resource requirements.
- Open source and fine-tunable: the model is completely open source and developers can fine-tune it to improve performance according to specific needs.
Using Help
Installation and Deployment
MedGemma models are hosted on the Hugging Face platform and can be used by developers without complicated installation. Here's how it works:
- Accessing the model page
show (a ticket)https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4This page contains links to downloads and documentation for 4B and 27B parametric models. The page contains download links and documentation for the 4B and 27B parametric models. - environmental preparation
- Make sure Python 3.8 or later is installed.
- Install the Transformers library for Hugging Face and run the following command:
pip install transformers - Install PyTorch or TensorFlow (choose based on model requirements). For example, install PyTorch:
pip install torch - If you process image data, you need to install additional libraries such as
Pillow:pip install Pillow
- Download model
On the Hugging Face model page, select the desired MedGemma variant (e.g.google/medgemma-4b-it或google/medgemma-27b-multimodal). Use the following code to download and load the model:from transformers import AutoModel, AutoTokenizer model_name = "google/medgemma-4b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name)The 27B model requires more memory and a GPU with at least 16GB of video memory is recommended.
- operating environment
MedGemma models are supported on a single GPU for local development or cloud deployment. We recommend using Google Cloud or Hugging Face Inference Endpoints for deployment.https://gke-ai-labs.dev/deployment guide.
Main Functions
1. Medical text processing
MedGemma can process medical texts, such as generating reports or answering medical questions. The procedure is described below:
- Input Preparation: Prepare medically relevant text, such as a piece of electronic health record or a medical question.
- code example:
input_text = "患者胸部 X 光显示肺部阴影,可能是什么原因?" inputs = tokenizer(input_text, return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - in the end: The model generates possible diagnostic explanations or recommendations, based on its training on medical texts.
2. Medical image understanding
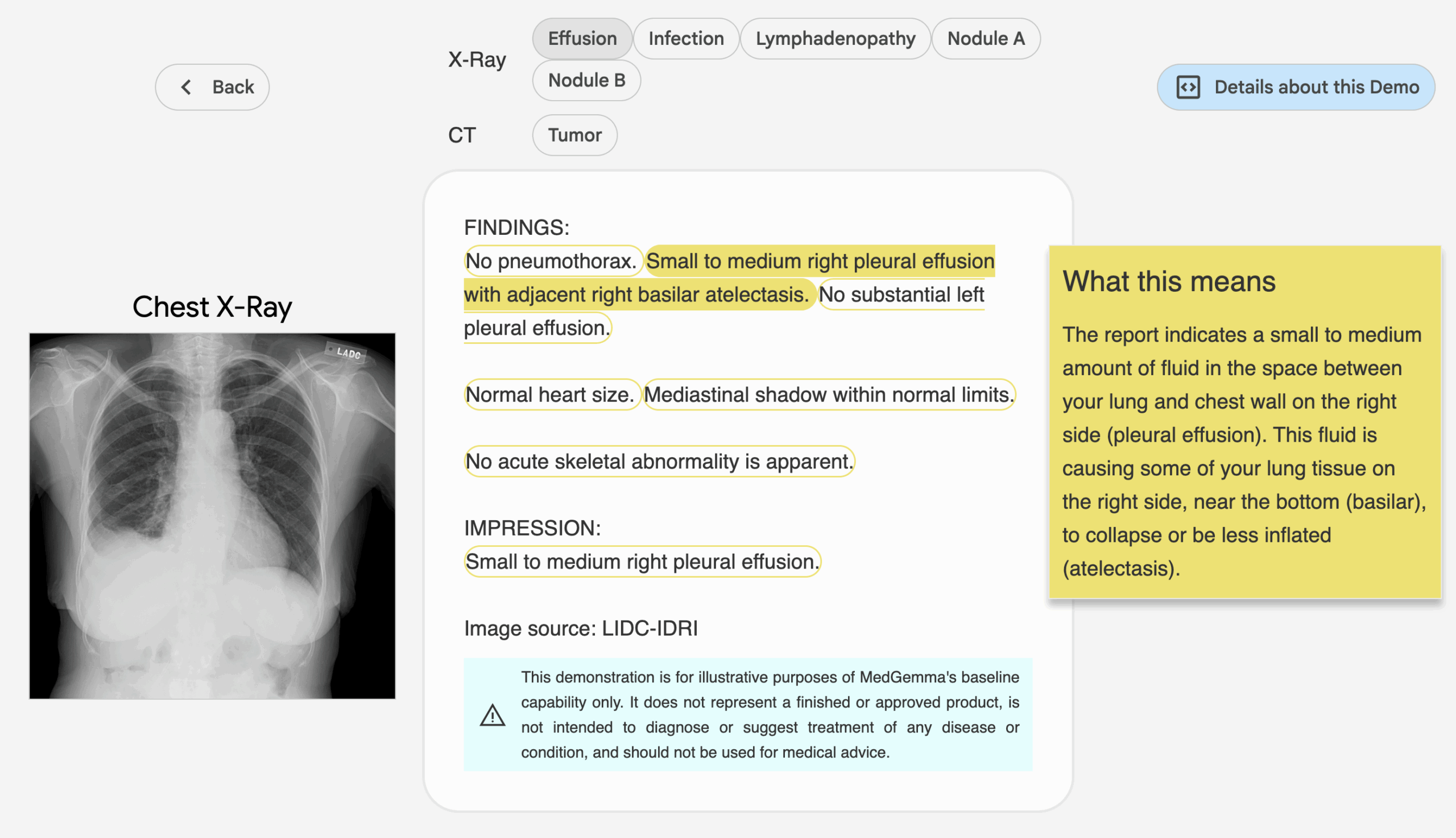
MedGemma's multimodal models support the analysis of medical images (e.g., X-rays, skin images). Procedure:
- Image Preprocessing: Converts the image to a format acceptable to the model (such as PNG or JPEG).
- code example(4B multimodal model as an example):
from PIL import Image import torch image = Image.open("chest_xray.png").convert("RGB") inputs = tokenizer(text="描述这张胸部 X 光图像", images=[image], return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - in the end: The model generates image descriptions or diagnostic suggestions, such as "The image shows a shadow in the lower lobe of the right lung, possibly suggesting pneumonia".
3. Multimodal reasoning
Multimodal models can process both text and images. For example, enter an X-ray image and the question, "Does this image show signs of pneumonia?" The model will combine the image and text to generate an answer. The operation is similar to the one described above, except that the tokenizer Pass both text and images in the
4. Model fine-tuning
The developer can fine-tune the model for specific tasks. The steps are as follows:
- Collect specific medical datasets (e.g., customized radiology images or text).
- Using Hugging Face's
TrainerAPI for fine-tuning:from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./medgemma_finetuned", per_device_train_batch_size=4, num_train_epochs=3, ) trainer = Trainer(model=model, args=training_args, train_dataset=your_dataset) trainer.train() - Save the fine-tuned model for subsequent use.
caveat
- Risk of data contamination: MedGemma may have been exposed to publicly available medical data during pre-training, and developers are required to validate the model performance using unpublished datasets to ensure its ability to generalize.
- Non-clinical useMedGemma is intended for research and development only and should not be used for actual clinical diagnosis without validation.
- hardware requirementThe 4B model is suitable for low-resource environments, while the 27B model requires a higher-performance GPU.
application scenario
- Radiology report generation
Radiologists can use MedGemma to analyze X-ray or CT images and generate a preliminary report to assist them in quickly interpreting the images. - Medical Question and Answer System
Developers can build medical Q&A bots that utilize MedGemma's text processing capabilities to answer common questions from patients or medical students. - Electronic Health Record Analysis
Providers can use the 27B multimodal model to parse complex EHR data, extract key information, and optimize treatment processes. - Medical Research Support
Researchers can use MedGemma to analyze medical literature or image datasets to accelerate the research process, such as dermatological image classification or histopathological analysis.
QA
- Can MedGemma be used for actual clinical diagnosis?
Currently, MedGemma is used for research and development only and cannot be used directly for diagnostic purposes without clinical validation. Developers need to further validate the reliability of the model on specific tasks. - What is the difference between the 27B model and the 4B model?
The 4B model is suitable for low-resource environments and supports multimodal and textual tasks; the 27B model is divided into textual and multimodal versions, which are more performant and suitable for complex tasks, but require higher computational resources. - How do you deal with data contamination?
Validate models using non-public or internal institutional datasets to avoid pre-training data affecting generalization capabilities. - What medical images are supported by MedGemma?
Supports a wide range of medical images such as chest X-rays, dermatology images, ophthalmology images and histopathology slides.
































