



MCPMark is a benchmark test for evaluating the capabilities of large model intelligences (Agentic). It measures a model's level of autonomy to plan, reason, and perform complex tasks by stress-testing it in a series of real software environments that integrate the Model Context Protocol (MCP). The test environments cover a wide range of mainstream tools such as Notion, GitHub, file systems, Postgres databases, and Playwright. Designed for researchers and engineers, the project provides an objective and reliable evaluation platform through a secure sandbox mechanism, reproducible automated tasks, and unified evaluation metrics.
Function List
- Versatile test environments: Support for testing in six realistic and complex software environments, including
Notion、GitHub、Filesystem、Postgres、Playwright和Playwright-WebArena。 - Automated task validation:: Each test task is accompanied by a rigorous automated validation script that enables objective and reproducible assessment of task completion.
- Secure sandboxing mechanism:: All tasks are run in a separate sandbox environment, which is destroyed at the end of the task, without leaking or contaminating the user's personal data.
- Failure to auto-renew: When an experiment is interrupted by a Pipeline Error such as a network fluctuation, the completed task is automatically skipped and the previously failed task is retried when the experiment is re-run.
- Rich set of assessment indicators:: Support for generating multiple aggregated metrics, including
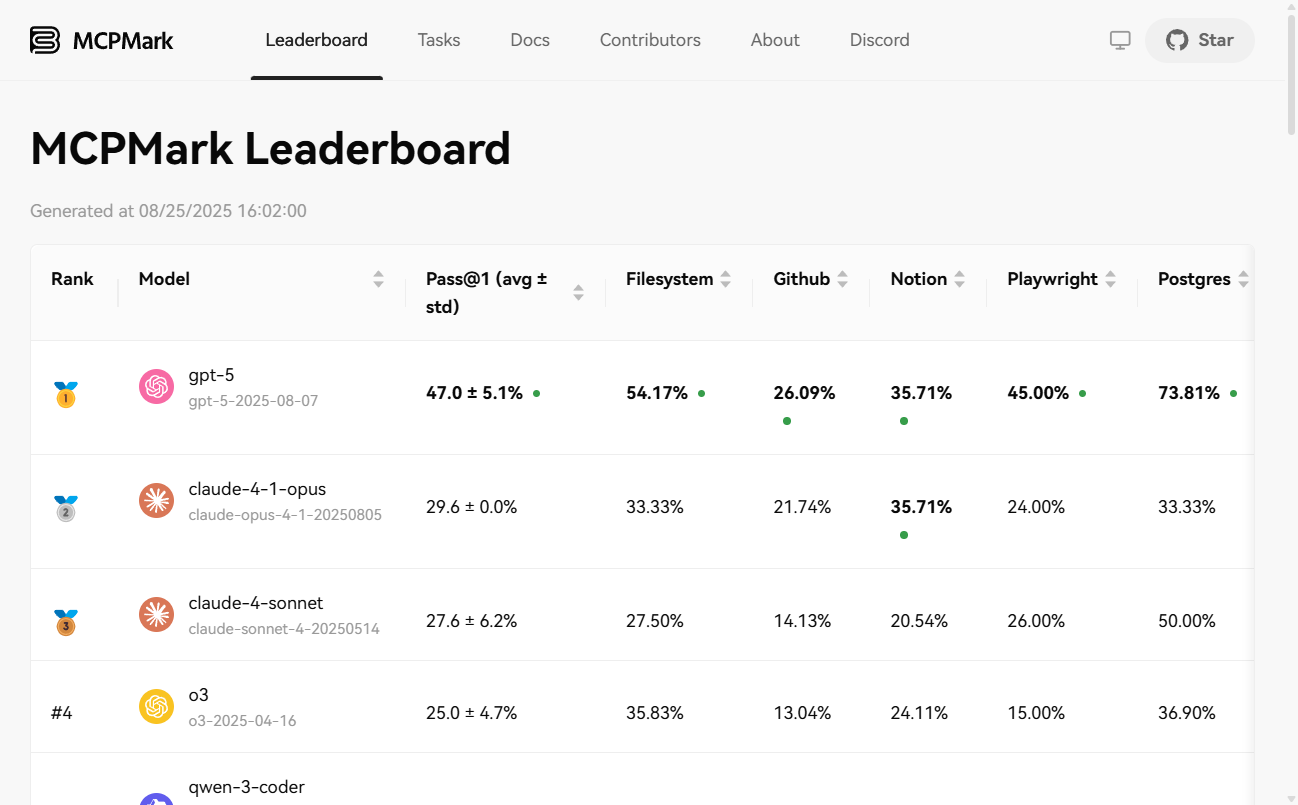
pass@1、pass@K、pass^K和avg@K, which is used as a comprehensive measure of the model's single success rate and stability over multiple attempts. - Flexible deployment options: Supports local (macOS, Linux) installation via Pip and also provides Docker images for quick deployment and operation.
Using Help
Using the MCPMark assessment model typically follows the following four steps:
1. Installation of MCPMark
You can choose to install locally or use Docker.
Local Installation (Pip).
# 从GitHub克隆仓库
git clone https://github.com/eval-sys/mcpmark.git
cd mcpmark
# 安装依赖
pip install -e .
Docker Installation.
# 克隆仓库后,直接构建Docker镜像
./build-docker.sh```
### **2. 授权服务**
如果你需要测试GitHub或Notion相关的任务,你需要先根据官方文档进行授权,让MCPMark能够以编程方式访问这些服务。
### **3. 配置环境变量**
在项目根目录创建一个名为<code>.mcp_env</code>的文件,并填入你需要的模型API密钥和相关服务的授权凭证。
```dotenv
# 示例:配置OpenAI模型
OPENAI_BASE_URL="https://api.openai.com/v1"
OPENAI_API_KEY="sk-..."
# 示例:配置GitHub
GITHUB_TOKENS="your_github_token"
GITHUB_EVAL_ORG="your_eval_org"
# 示例:配置Notion
SOURCE_NOTION_API_KEY="your_source_notion_api_key"
EVAL_NOTION_API_KEY="your_eval_notion_api_key"
4. Operational assessment experiment
You can run different ranges of tasks as required.
# 假设实验名为 new_exp,模型为 gpt-4.1,环境为 notion,运行K次
# 评估该环境下的所有任务
python -m pipeline --exp-name new_exp --mcp notion --tasks all --models gpt-4.1 --k K
# 评估一个任务组 (例如 online_resume)
python -m pipeline --exp-name new_exp --mcp notion --tasks online_resume --models gpt-4.1 --k K
5. Viewing and aggregating results
The results are saved in JSON and CSV formats in the./results/directory. If your run count K is greater than 1, you can run the following command to generate an aggregation report.
python -m src.aggregators.aggregate_results --exp-name new_exp
application scenario
- Evaluating the Intelligent Body Capabilities of Models
Research organizations and developers can use this benchmark to objectively measure the ability of different cutting-edge AI models to autonomously plan, reason, and use tools when dealing with complex workflows, not just simple API calls. - AI Intelligence Body Regression Testing
For teams developing AI smartbody applications, MCPMark can be used as a standard regression test set to ensure that iterative updates to a model or application do not result in degradation of its smartbody capabilities. - Scholarly Research on Intelligent Body AI
Scholars can use this standardized platform to publish reproducible research results on the capabilities of AI intelligences, advancing the field as a whole. - Validate the level of autonomy of business processes
Organizations can use MCPMark to test the level of autonomous automation that AI models can achieve in specific business scenarios (e.g., code repository management, database operations).
QA
- What exactly is MCPMark?
It is a standard benchmarking tool, not an AI application for general users. Its core purpose is to provide a set of reliable environments and tasks to scientifically evaluate and compare the ability of different AI models to autonomously perform complex tasks as "agents". - What is MCP (Model Context Protocol)?
MCP (Model Context Protocol) is a set of technical standards and protocols that standardize the way AI macromodels interact with external tools and software environments.MCPMark is built on this set of protocols to ensure that the model-environment interactions are controlled, measurable and reproducible. - Is it safe to run the MCPMark test?
Yes, it's very secure. It runs in a completely isolated sandbox environment created for each experiment. As soon as the mission is over, this environment is completely destroyed, so no personal files or account data on your local machine are touched or modified. - What is the pass@K indicator?
pass@Kis a key measure of model reliability. It indicates the probability that the model will successfully complete the task at least once out of K independent attempts. The higher this metric is, the more stable and reliable the model's ability to complete the task as an intelligent body.
































