


LMCache is an open source key-value (KV) cache optimization tool designed to improve the efficiency of Large Language Model (LLM) reasoning. It significantly reduces inference time and GPU resource consumption by caching and reusing intermediate computation results (key-value caching) of the model, which is especially suitable for long context scenarios.LMCache is compatible with the vLLM It seamlessly integrates with other inference engines and supports GPU, CPU, and disk storage for scenarios such as multi-round Q&A and Retrieval Augmented Generation (RAG). The project is community-driven, uses the Apache 2.0 license, and is widely used for enterprise-level AI inference optimization.
Function List
- Key-Value Cache Reuse: Cache LLM key-value pairs, support non-prefixed text reuse, reduce double-counting.
- Multi-storage back-end support: Supports storage such as GPU, CPU DRAM, disk, and Redis for flexibility in dealing with memory constraints.
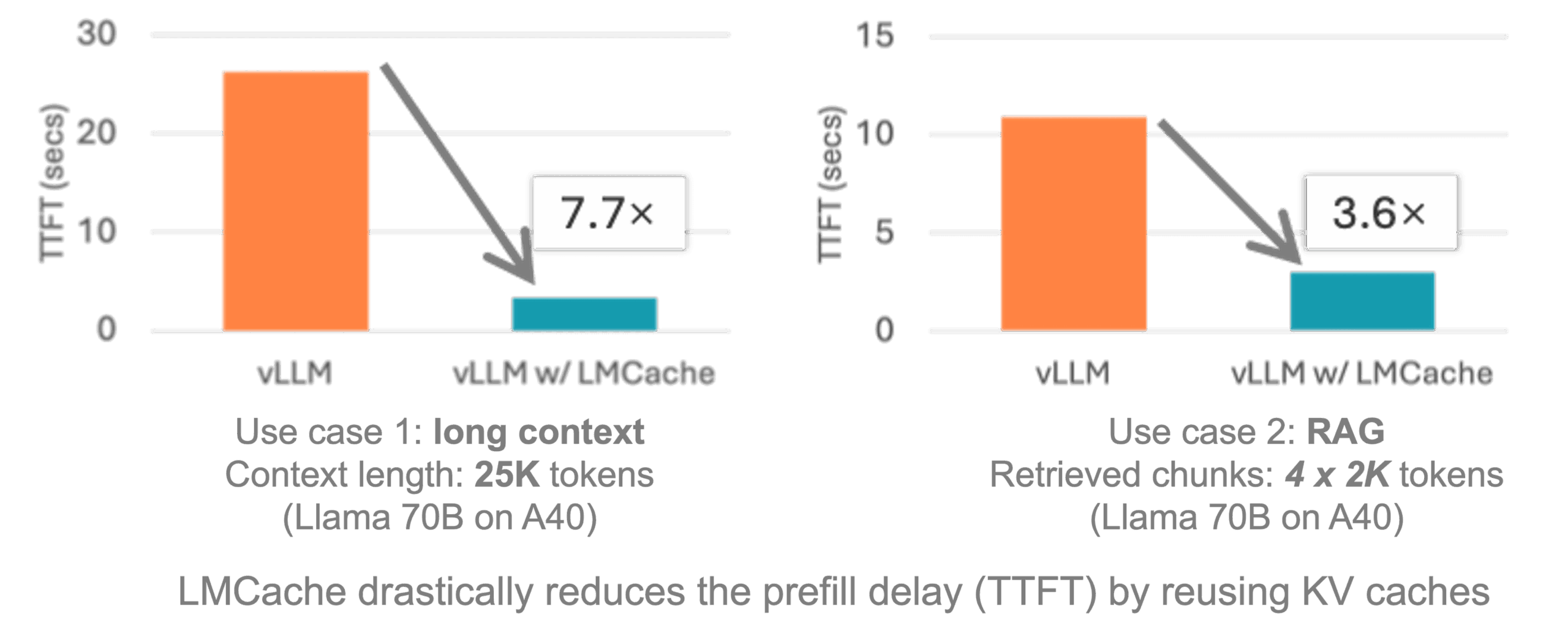
- Integration with vLLM: Seamless access to vLLM, providing 3-10x optimization of inference latency.
- distributed cache: Supports shared caching across multiple GPUs or containerized environments for large-scale deployments.
- multimodal support: Caching key-value pairs of images and text to optimize multimodal model inference.
- Workload Generation: Provide testing tools to generate workloads such as multi-round quizzes, RAGs, etc. to validate performance.
- Open Source Community Support: Provide documentation, examples and community meetings to facilitate user contributions and exchanges.
Using Help
Installation process
LMCache is easy to install and supports Linux platforms and NVIDIA GPU environments. Below are the detailed installation steps, based on the official documentation and community recommendations.
- Preparing the environment:
- Make sure your system is Linux, Python version 3.10 or higher, and CUDA version 12.1 or higher.
- Install Conda (Miniconda is recommended) to create a virtual environment:
conda create -n lmcache python=3.10 conda activate lmcache
- clone warehouse:
- Use Git to clone your LMCache repository locally:
git clone https://github.com/LMCache/LMCache.git cd LMCache
- Use Git to clone your LMCache repository locally:
- Installing LMCache:
- Install the latest stable version via PyPI:
pip install lmcache - Or install the latest pre-release version (which may contain experimental features):
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.2.2.dev57 - If you need to install from source:
pip install -e .
- Install the latest stable version via PyPI:
- Installing vLLM:
- LMCache needs to be used with vLLM, install the latest version of vLLM:
pip install vllm
- LMCache needs to be used with vLLM, install the latest version of vLLM:
- Verify Installation:
- Check that LMCache is installed correctly:
python import lmcache from importlib.metadata import version print(version("lmcache"))The output should be the version number of the installation, e.g.
0.2.2.dev57。
- Check that LMCache is installed correctly:
- Optional: Docker Deployment:
- LMCache provides pre-built Docker images with vLLM integration:
docker pull lmcache/lmcache:latest - Run the Docker container and configure vLLM and LMCache according to the documentation.
- LMCache provides pre-built Docker images with vLLM integration:
Using the main functions
The core function of LMCache is to optimize the key-value cache to accelerate LLM inference. The following is a detailed how-to guide for the main features.
1. Key-value cache reuse
LMCache avoids double-counting of the same text or context by storing the model's Key-Value Cache (KV Cache). Users can enable LMCache in vLLM:
- Configuring Environment Variables:
export LMCACHE_USE_EXPERIMENTAL=True export LMCACHE_CHUNK_SIZE=256 export LMCACHE_LOCAL_CPU=True export LMCACHE_MAX_LOCAL_CPU_SIZE=5.0These variables set LMCache to use the experimental feature, 256 tokens per block, enable the CPU backend, and limit CPU memory to 5GB.
- Running a vLLM instance:
LMCache automatically loads and caches key-value pairs when you start vLLM. Sample code:from vllm import LLM from lmcache.integration.vllm.utils import ENGINE_NAME from vllm.config import KVTransferConfig ktc = KVTransferConfig(kv_connector="LMCacheConnector", kv_role="kv_both") llm = LLM(model="meta-llama/Meta-Llama-3.1-8B-Instruct", kv_transfer_config=ktc)
2. Multi-storage back-end
LMCache supports storing key-value cache on GPU, CPU, disk or Redis. Users can choose the storage method according to the hardware resources:
- Local Disk Storage:
python3 -m lmcache_server.server localhost 9000 /path/to/diskThis starts the LMCache server, which stores the cache to the specified disk path.
- Redis Storage:
To configure the Redis backend, you need to set up a username and password, refer to the documentation:export LMCACHE_REDIS_USERNAME=user export LMCACHE_REDIS_PASSWORD=pass
3. Distributed caching
In multi-GPU or containerized environments, LMCache supports shared caching across nodes:
- Start the LMCache server:
python3 -m lmcache_server.server localhost 9000 cpu - Configure the vLLM instance to connect to the server, refer to
disagg_vllm_launcher.shExample.
4. Multimodal support
LMCache supports a multimodal model to optimize visual LLM inference by caching key-value pairs via hashed image tokens (mm_hashes):
- To enable multimodal support in vLLM, refer to the official example
LMCache-ExamplesWarehouse.
5. Testing tools
LMCache provides testing tools to generate workloads to verify performance:
- Clone Test Warehouse:
git clone https://github.com/LMCache/lmcache-tests.git cd lmcache-tests bash prepare_environment.sh - Run the test cases:
python3 main.py tests/tests.py -f test_lmcache_local_cpu -o outputs/The output is saved in the
outputs/test_lmcache_local_cpu.csv。
Handling Precautions
- Environmental inspections: To ensure that CUDA and Python versions are compatible, it is recommended that you use the Conda management environment.
- Log Monitoring: Inspection
prefiller.log、decoder.log和proxy.logto debug the problem. - Community Support: Get help by joining the LMCache Slack or attending a bi-weekly community meeting on Tuesdays at 9 a.m. PT.
application scenario
- interactive question and answer system
LMCache caches key-value pairs in context to accelerate multi-round dialog scenarios. When a user asks successive questions in the chatbot, LMCache reuses the previous computation results to reduce latency. - Retrieval Augmentation Generation (RAG)
在 RAG In the application, LMCache caches key-value pairs of documents and responds quickly to similar queries, making it suitable for intelligent document search or enterprise knowledge bases. - Multimodal model inference
For visual-linguistic models, LMCache caches key-value pairs of images and text, reducing GPU memory footprint and improving response time. - Massively Distributed Deployment
In multi-GPU or containerized environments, LMCache's distributed caching capabilities support cross-node sharing to optimize enterprise-class AI inference.
QA
- What platforms does LMCache support?
Linux and NVIDIA GPU environments are currently supported, and Windows can be used via WSL. - How does it integrate with vLLM?
pass (a bill or inspection etc)pip install lmcache vllmand enable LMCacheConnector in the vLLM configuration, refer to the official sample code. - Is non-prefix caching supported?
support, LMCache uses partial recomputation techniques to cache non-prefixed text in RAG workloads. - How to debug performance issues?
Examine log files and run test cases, output CSV files to analyze latency and throughput.




























