



LightRAG is an open source Python framework developed by a team from the School of Data Science at the University of Hong Kong to simplify and accelerate the process of building Retrieval Augmented Generation (RAG) applications. It enhances the quality of generated content by combining knowledge graphs with traditional vector retrieval techniques to provide more accurate and contextually relevant information for Large Language Models (LLMs). The core feature of the framework is its lightweight and modular design, which decomposes the complex RAG process into multiple independent components such as document parsing, index construction, information retrieval, content rearrangement and text generation. This design not only lowers the threshold for developers, but also provides a high degree of flexibility, allowing users to easily replace or customize different modules according to their specific needs, such as integrating different vector databases, graph databases, or large language models. Designed for scenarios where complex information and deep relationships need to be processed, LightRAG is dedicated to solving the problem of fragmented text information and lack of deep connections in traditional RAG systems.
Function List
- modular design: Break down the RAG process into clear modules for document parsing, indexing, retrieval, reformatting and generation that are easy to understand and customize.
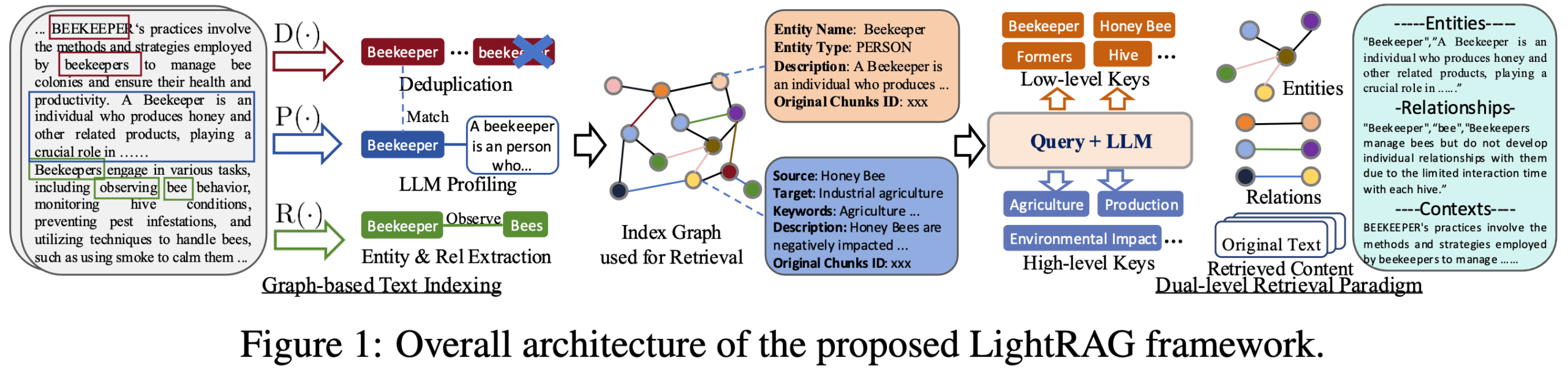
- knowledge graph integration: The ability to automatically extract entities and relationships from unstructured text and build knowledge graphs that enable deeper understanding and correlation of information.
- Two-tier search mechanism: Combines vector-based similarity search and knowledge graph-based association retrieval, and is able to handle queries targeting both specific details (local) and macro-concepts (global).
- Flexible storage options: Supports a variety of storage backends, including Json, PostgreSQL, and Redis for key-value pair storage; FAISS, Chroma, and Milvus for vector storage; and Neo4j and PostgreSQL AGE for graph storage.
- High model compatibility: Support access to a wide range of Large Language Models (LLMs) and Embedding Models, including those provided by platforms such as OpenAI, Hugging Face and Ollama.
- Multi-file format support: Ability to handle a wide range of document formats including PDF, DOCX, PPTX, CSV and plain text.
- Visualization tools: Provides a Web interface to support visual exploration of knowledge graphs, allowing users to visualize the connections between data.
- multimodal capability: Expanded ability to handle multimodal content such as images, tables, formulas, etc. through integration with RAG-Anything.
Using Help
LightRAG is a powerful and easy-to-use framework designed to help developers quickly build intelligent Q&A systems based on their own knowledge base. Its biggest feature is the combination of knowledge graphs, making the search results not only relevant, but also stronger logical relationships. The following is a detailed description of its installation and use of the process.
mounting
Getting started with LightRAG is very easy and can be installed directly via pip, Python's package manager. It is recommended to install the full version with API and web interface to experience the full functionality including knowledge graph visualization.
- Installation via PyPI:
Open a terminal and execute the following command:pip install "lightrag-hku[api]"This command installs LightRAG's core libraries and related dependencies required by its servers.
- Configuring Environment Variables:
Once the installation is complete, the runtime environment needs to be configured.LightRAG provides a template for the environment fileenv.example. You need to copy it as.envfile and modify the configuration to suit your situation, most critically setting the API keys for the Large Language Model (LLM) and Embedding Model.cp env.example .envThen open it in a text editor
.envfile, fill in yourOPENAI_API_KEYor other model access credentials. - Starting services:
Once the configuration is complete, run the following command directly from the terminal to start the LightRAG service:lightrag-serverOnce the service is started, you can access the web interface it provides through a browser or interact with it through an API.
Core Usage Process
LightRAG's core programming process follows a clear RAG Logic:Data Feeding -> Index Building -> Query GenerationThe Below is a simple Python code example that demonstrates how to implement a complete Q&A process using LightRAG Core.
- Initializing a LightRAG Instance
First, you need to import the necessary modules and create an instance of LightRAG. During initialization, you must specify the working directory (for data and cache), embedded functions and LLM functions.import os import asyncio from lightrag import LightRAG, QueryParam from lightrag.llm.openai import gpt_4o_mini_complete, openai_embed from lightrag.kg.shared_storage import initialize_pipeline_status # 设置工作目录 WORKING_DIR = "./rag_storage" if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR) # 设置你的OpenAI API密钥 os.environ["OPENAI_API_KEY"] = "sk-..." async def initialize_rag(): # 创建LightRAG实例,并注入模型函数 rag = LightRAG( working_dir=WORKING_DIR, embedding_func=openai_embed, llm_model_func=gpt_4o_mini_complete, ) # 重要:必须初始化存储和处理管道 await rag.initialize_storages() await initialize_pipeline_status() return ragtake note of:
initialize_storages()和initialize_pipeline_status()These two initialization steps are required, otherwise the program will report an error. - Feeding data (Insert)
Once initialization is complete, you can add your text data to LightRAG.ainsertmethod receives a string or list of strings.async def feed_data(rag_instance): text_to_insert = "史蒂芬·乔布斯是一位美国商业巨头和发明家。他是苹果公司的联合创始人、董事长和首席执行官。乔布斯被广泛认为是微型计算机革命的先驱。" await rag_instance.ainsert(text_to_insert) print("数据投喂成功!")In this step, LightRAG automatically chunks the text, extracts entities and relationships, generates vector embeddings, and builds the knowledge graph in the background.
- Query Data (Query)
Once the data is fed and indexed, it is ready to be queried.aquerymethod receives a question and passes it through theQueryParamobject to control the behavior of the query.async def ask_question(rag_instance): query_text = "谁是苹果公司的联合创始人?" # 使用QueryParam配置查询模式 # "hybrid" 模式结合了向量搜索和图检索,推荐使用 query_params = QueryParam(mode="hybrid") response = await rag_instance.aquery(query_text, param=query_params) print(f"问题: {query_text}") print(f"答案: {response}") - Combine and run
Finally, we combine the above steps into one main function and use theasyncioto run.async def main(): rag = None try: rag = await initialize_rag() await feed_data(rag) await ask_question(rag) except Exception as e: print(f"发生错误: {e}") finally: if rag: # 程序结束时释放存储资源 await rag.finalize_storages() if __name__ == "__main__": asyncio.run(main())
Query Patterns Explained
LightRAG offers several query modes to suit different application scenarios:
naive: Basic vector search pattern for simple quizzes.local: Focuses on entity information directly related to the query and is suitable for scenarios that require precise, concrete answers.global: Focuses on relationships between entities and global knowledge for scenarios that require macro, correlational answers.hybrid:: Combineslocal和globalThe advantages of the model are that it is the most versatile and usually the most effective.mix: Integration of Knowledge Graph and Vector Retrieval is the recommendation model in most cases.
Through the use of the QueryParam set up in mode parameter, you have the flexibility to switch between these modes to achieve the best query results.
application scenario
- Intelligent customer service and Q&A system
Enterprises can inject internal information such as product manuals, help files, and historical customer service records into LightRAG to build an intelligent customer service robot that can accurately and quickly answer customer questions. Thanks to the combination of knowledge graph, the system can not only find answers, but also understand the related information behind the questions and provide more comprehensive answers, for example, when answering a question about a product's function, it can provide related tips or links to frequently asked questions along with it. - Intra-enterprise knowledge base management
For companies with a huge amount of internal documents (e.g. technical documents, project reports, rules and regulations), LightRAG can transform them into a structured and intelligently queriable knowledge base. Employees can ask questions in natural language, quickly locate the information they need, and even discover hidden connections between different documents, greatly improving information retrieval efficiency and knowledge utilization. - Scientific Research and Literature Analysis
Researchers can utilize LightRAG to process a large number of academic papers and research reports. The system is able to automatically extract key entities (e.g., technologies, scholars, experiments), concepts and their relationships, and build them into a knowledge graph. This enables researchers to easily explore knowledge across documents, such as querying "the application of a certain technology in different studies" or "the collaboration between two scholars", thus accelerating the research process. - Financial and Legal Document Analysis
In specialized fields such as finance and law, where documents are often complex and voluminous, LightRAG can help analysts or lawyers to quickly extract key information from documents such as annual reports, prospectuses, and legal clauses, and to sort out the logical relationships among them. For example, it is possible to quickly identify all responsible parties in a contract and their corresponding rights and responsibilities clauses, or to analyze the description of the same business in the financial reports of multiple companies to assist in decision-making.
QA
- How is LightRAG different from generic frameworks like LangChain or LlamaIndex?
The core differentiator of LightRAG is its focus on deep integration of knowledge graphs into the RAG process, aiming to solve the problem of fragmentation of traditional RAG information. Whereas LangChain and LlamaIndex are more broadly-featured and generalized LLM application development frameworks that offer a wide range of tools and integration options, but also have relatively steep learning curves, LightRAG is more lightweight and aims to provide developers with a simple, fast, and efficient RAG solution featuring a built-in knowledge graph. - Are there any special requirements for the Large Language Model (LLM) to use LightRAG?
Yes, since LightRAG needs to utilize LLM to extract entities and relationships from documents to build a knowledge graph, this requires a high level of command following ability and contextual understanding of the model. It is officially recommended to use a model with a reference count of at least 32 billion and a context window length of at least 32KB, 64KB is recommended to ensure that longer documents can be processed and the entity extraction task can be done accurately. - What types of databases does LightRAG support?
LightRAG's storage layer is modular and supports multiple database implementations. For Key-Value Storage (KV Storage), it supports native JSON files, PostgreSQL, Redis, and MongoDB. for Vector Storage (Vector Storage), it supports NanoVectorDB (default), FAISS, Chroma, Milvus, and others. For Graph Storage, it supports NetworkX (default), Neo4j, and PostgreSQL with the AGE plugin. this design allows users to choose flexibly according to their technology stack and performance needs. - Can I use my own models in LightRAG? For example, models deployed on Hugging Face or Ollama?
LightRAG has designed a flexible model injection mechanism that allows users to integrate custom LLMs and embedded models. The sample code in the repository already provides access to the Hugging Face and the Ollama model example. All you need to do is write a call function that conforms to its interface specification and pass it in when initializing a LightRAG instance, which allows it to work seamlessly with all kinds of open source or privately deployed models.































