



LangExtract is an open source Python library developed by Google that focuses on extracting structured data from unstructured text. It utilizes large-scale language models (LLMs) such as Google Gemini LangExtract is a series that combines precise source text localization and interactive visualization features to help users quickly transform complex text into a clear data format. With just a handful of examples, users can define extraction tasks applicable to any domain without having to fine-tune the model.LangExtract is particularly well suited for processing long documents, supports parallel processing and multiple rounds of extraction, and is widely used in fields such as healthcare and literary analysis. The tool is released under the Apache 2.0 license, and the code is hosted on GitHub with open community contributions.
Function List
- Support for multiple language models: compatible with Google Gemini and other cloud models and Ollama Local modeling with flexible adaptation to user needs.
- Structured Information Extraction: Extract entities, relationships and attributes from unstructured text and generate JSONL format output.
- Interactive Visualization: Generate HTML visualization files from the extraction results for users to easily view and analyze the extracted entities.
- Long Document Processing: Efficiently process ultra-long texts, such as entire novels or medical reports, through intelligent chunking and parallel processing.
- Customized Extraction Tasks: Quickly define extraction rules that apply to specific domains with prompt words and a handful of examples.
- Medical Text Processing: Supports extracting drug names, dosages and other information from clinical notes for the medical field.
- API Integration: Supports cloud-based model API calls and can also be extended to third-party local model inference endpoints.
Using Help
Installation process
LangExtract is developed in Python and supports modern Python package management methods. Here are the detailed installation steps:
- Clone Code Repository
Open a terminal and run the following command to clone the LangExtract repository:git clone https://github.com/google/langextract.git cd langextract - Installation of dependencies
Install LangExtract using pip. development mode is recommended for modifying the code:pip install -e .Install additional dependencies if a development or test environment is required:
pip install -e ".[dev]" # 包含 linting 工具 pip install -e ".[test]" # 包含 pytest 测试工具 - Configuring API Keys(e.g., using cloud-based models)
If using a cloud model such as Google Gemini, you need to configure the API key. Write the key to the.envDocumentation:cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOFTo protect the key, add
.env到.gitignore:echo '.env' >> .gitignoreLocal models (e.g. run through Ollama) do not require an API key.
- Verify Installation
Run the following command to check if the installation was successful:python -c "import langextract; print(langextract.__version__)"
Usage
The core function of LangExtract is to extract structured data from text through prompt words and examples. Below is the procedure:
1. Extraction of basic information
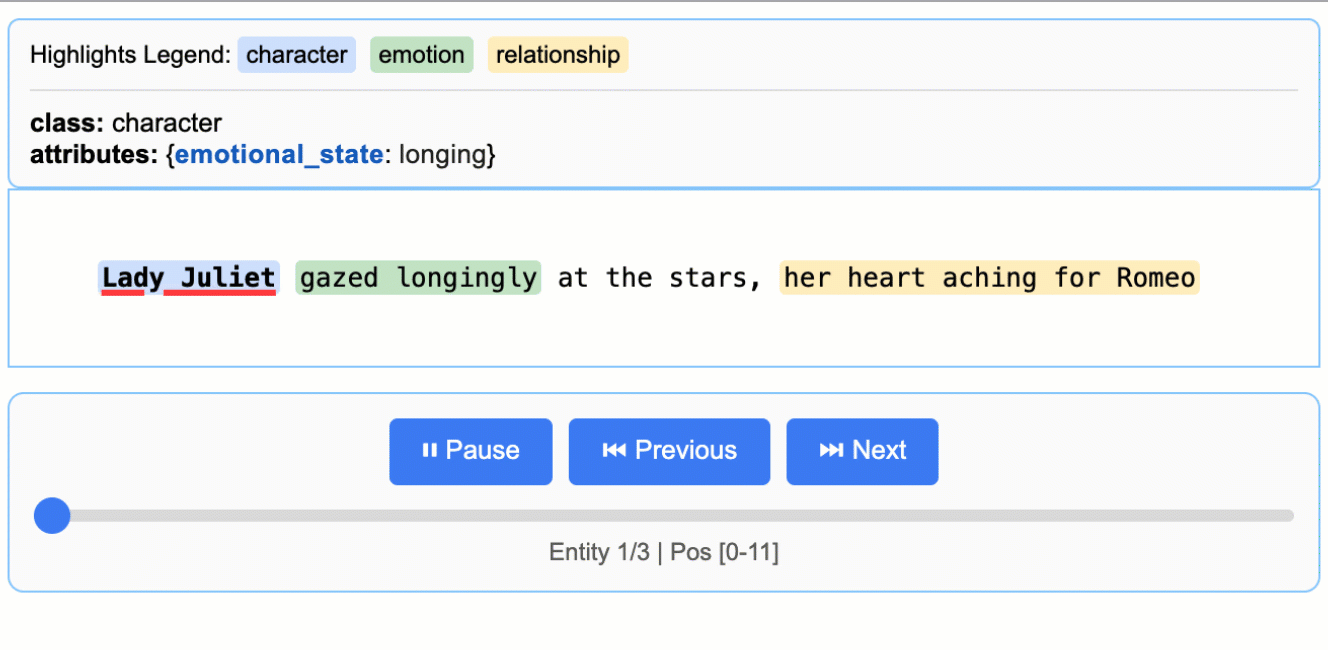
Suppose you want to extract characters, emotions, and relationships from a piece of text, the code example is as follows:
import langextract as lx
import textwrap
# 定义提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance. Use exact text for extractions. Do not paraphrase or overlap entities.
""")
# 提供示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
{"entity": "Romeo", "type": "character", "emotion": "hopeful"},
]
)
]
# 输入文本
text = "ROMEO. But soft! What light through yonder window breaks? It is Juliet."
# 执行提取
result = lx.extract(text, prompt=prompt, examples=examples, model="gemini-2.5-flash")
# 保存结果
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
After running, the extraction results will be saved as extraction_results.jsonl file containing the extracted entities and their attributes.
2. Generating interactive visualizations
LangExtract supports generating HTML visualizations of the extraction results for easy viewing:
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
generated visualization.html The file can be opened in a browser, showing the extracted entities and their context.
3. Handling of long documents
For long documents (such as the entire Romeo and Juliet book), LangExtract uses intelligent chunking and parallel processing:
url = "https://www.gutenberg.org/files/1513/1513.txt"
result = lx.extract_from_url(url, prompt=prompt, examples=examples, max_workers=4)
lx.io.save_annotated_documents([result], output_name="long_doc_results.jsonl")
max_workers parameter controls the number of threads for parallel processing, suitable for processing large files.
4. Medical text extraction
LangExtract excels in the medical field, extracting drug names, dosages, and other information. Example:
prompt = "Extract medication names, dosages, and administration routes from clinical notes."
text = "Patient prescribed Metformin 500 mg orally twice daily."
result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro")
The results will contain extracted drug information such as:
{"entity": "Metformin", "dosage": "500 mg", "route": "orally"}
Featured Function Operation
- Model Selection: The default is to use
gemini-2.5-flashmodel with balanced speed and quality. For complex tasks, switch togemini-2.5-pro:result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro") - multiround extraction: Improve accuracy with multiple extractions for complex documents:
result = lx.extract(text, prompt=prompt, num_passes=2) - RadExtract Demo: LangExtract offers an online demo of RadExtract, specializing in radiology reports. Visit HuggingFace Spaces (
https://google-radextract.hf.space) can be tried without installation.
caveat
- Cloud models require stable API keys and network connections.
- When processing very long documents, it is recommended to use the Tier 2 Gemini quota to avoid rate limiting.
- When saving the API key, make sure that the
.envDocument security.
application scenario
- Medical Data Processing
Hospitals and research organizations can use LangExtract to extract information such as medications, dosages, diagnoses, etc. from clinical notes or radiology reports. For example, radiology reports can be structured into a format that includes headings and key entities for easy data analysis and clinical decision making. - literary analysis
Researchers can extract characters, emotions, and relationships from long works of literature. For example, analyzing character interactions in Romeo and Juliet generates visualization results to study the network of character relationships. - Business Intelligence Extraction
Organizations can extract key entities (e.g., company names, products, events) from news, reports, or social media for market analysis or competitive intelligence gathering. - Legal Document Processing
Law firms can extract clauses, dates, parties and other information from a contract or legal document to quickly generate a structured summary.
QA
- Is LangExtract free?
LangExtract is an open source tool and the code is free to use (Apache 2.0 license). However, there is an API call fee for using a cloud-based model (e.g. Gemini). - Are local models supported?
Supports running local open source models through Ollama without API keys, suitable for network-less environments. - How do I handle very long documents?
Using smart chunking and parallel processing (setup)max_workers), and it is recommended that multiple extractions (settingnum_passes) to improve accuracy. - How are the visualization results viewed?
(of a computer) runlx.visualizeGenerate HTML files that can be opened in a browser to interactively view the extraction results. - Are medical apps compliant?
LangExtract is a demonstration tool only, not a medical diagnostic device. Health-related applications are subject to the Health AI Developer Foundations Terms of Use.






























