


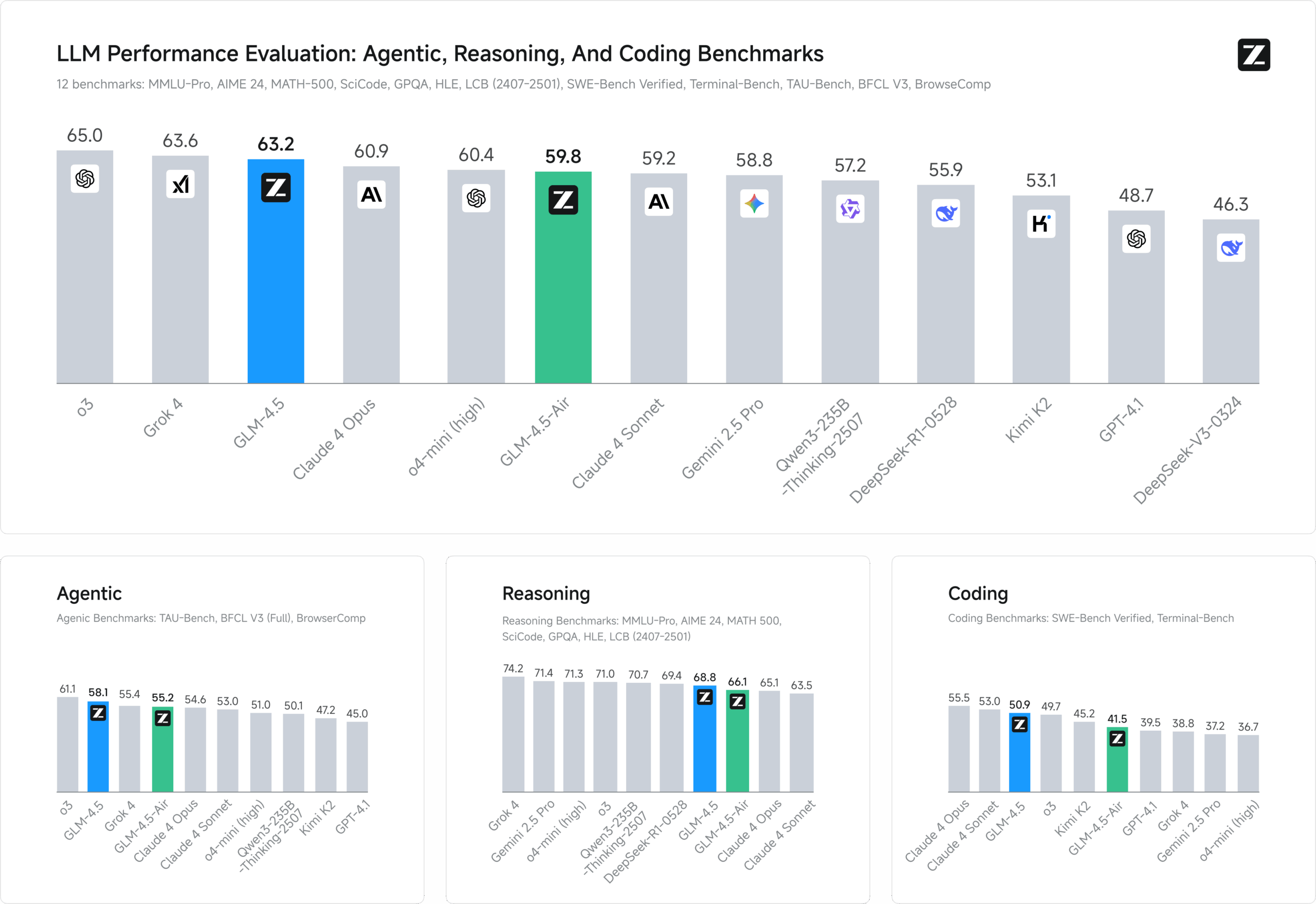
GLM-4.5 is an open source multimodal large language model developed by zai-org, designed for intelligent reasoning, code generation, and intelligent body tasks. It contains several variants including GLM-4.5 (355 billion parameters, 32 billion active parameters), GLM-4.5-Air (106 billion parameters, 12 billion active parameters), etc. It adopts the Mixed Expertise (MoE) architecture and supports 128K context lengths and 96K output tokens. The models are pre-trained on 15 trillion tokens, fine-tuned in the code, inference, and intelligentsia domains, and perform at the top of several benchmarks, specifically approaching or even outperforming some of the closed-source models in programming and tool-calling tasks.Released under the MIT License, GLM-4.5 is supported for both academic and commercial use, and is suitable for developers, researchers, and enterprises to deploy locally or in the cloud.
Function List
- Mixed Reasoning Mode: Supports Thinking Mode to handle complex reasoning and tool invocations, and Non-Thinking Mode to provide fast responses.
- Multimodal support: Handles text and image input for multimodal Q&A and content generation.
- Intelligent Programming: Generate high-quality code in Python, JavaScript and other languages, with support for code completion and bug fixes.
- Intelligent Body Functions: Supports function calls, web browsing and automated task processing for complex workflows.
- Context caching: Optimize long conversation performance and reduce duplicate computations.
- Structured Output: Supports JSON and other formats for easy system integration.
- Long Context Processing: Native support for 128K context length, suitable for long document analysis.
- Streaming Output: Provide real-time response to enhance the interactive experience.
Using Help
GLM-4.5 provides model weights and tools via a GitHub repository (https://github.com/zai-org/GLM-4.5), suitable for users with technical background to deploy locally or in the cloud. Below is a detailed installation and usage guide to help users get started quickly.
Installation process
- environmental preparation
Ensure that Python 3.8 or above and Git are installed. a virtual environment is recommended:python -m venv glm_env source glm_env/bin/activate # Linux/Mac glm_env\Scripts\activate # Windows - clone warehouse
Get the GLM-4.5 code from GitHub:git clone https://github.com/zai-org/GLM-4.5.git cd GLM-4.5 - Installation of dependencies
Installs the specified version of the dependency to ensure compatibility:pip install setuptools>=80.9.0 setuptools_scm>=8.3.1 pip install git+https://github.com/huggingface/transformers.git@91221da2f1f68df9eb97c980a7206b14c4d3a9b0 pip install git+https://github.com/vllm-project/vllm.git@220aee902a291209f2975d4cd02dadcc6749ffe6 pip install torchvision>=0.22.0 gradio>=5.35.0 pre-commit>=4.2.0 PyMuPDF>=1.26.1 av>=14.4.0 accelerate>=1.6.0 spaces>=0.37.1Note: vLLM may take a long time to compile, use the pre-compiled version if you don't need it.
- Model Download
The model weights are hosted in Hugging Face and ModelScope. below is an example of loading GLM-4.5-Air:from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True) model = AutoModel.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True).half().cuda() model.eval() - hardware requirement
- GLM-4.5-Air: 16GB of GPU memory required (INT4 quantized at ~12GB).
- GLM-4.5: Recommended for multi-GPU environments, requires approximately 32GB of RAM.
- CPU Reasoning: The GLM-4.5-Air will run on a CPU with 32GB of RAM, but is slow.
Usage
GLM-4.5 supports command line, web interface and API calls, providing a variety of interaction methods.
command-line reasoning
utilization trans_infer_cli.py Scripts for interactive dialog:
python inference/trans_infer_cli.py --model_name zai-org/GLM-4.5-Air
- Input text or an image and the model returns a response.
- Supports multiple rounds of conversations with automatic history saving.
- Example: Generating Python functions:
response, history = model.chat(tokenizer, "写一个 Python 函数计算三角形面积", history=[]) print(response)Output:
def triangle_area(base, height): return 0.5 * base * height
web interface
Launch web interfaces via Gradio with multimodal input support:
python inference/trans_infer_gradio.py --model_name zai-org/GLM-4.5-Air
- Access to the local address (usually
http://127.0.0.1:7860)。 - Enter text or upload an image or PDF and click submit to get a response.
- Feature: Upload PDFs that the model can parse and answer questions.
API Services
GLM-4.5 supports an OpenAI-compatible API using the vLLM Deployment:
vllm serve zai-org/GLM-4.5-Air --limit-mm-per-prompt '{"image":32}'
- Example Request:
import requests payload = { "model": "GLM-4.5-Air", "messages": [{"role": "user", "content": "分析这张图片"}], "image": "path/to/image.jpg" } response = requests.post("http://localhost:8000/v1/chat/completions", json=payload) print(response.json())
Featured Function Operation
- mixed inference model
- cast : Suitable for complex tasks such as mathematical reasoning or tool invocation:
model.chat(tokenizer, "解决方程:2x^2 - 8x + 6 = 0", mode="thinking")The model will output detailed solution steps.
- modus vivendi : Good for quick quizzes:
model.chat(tokenizer, "翻译:Good morning", mode="non-thinking") - multimodal support
- Processes text and image input. For example, uploading images of math topics:
python inference/trans_infer_gradio.py --input math_problem.jpg - Note: Simultaneous processing of images and videos is not supported at this time.
- Processes text and image input. For example, uploading images of math topics:
- Intelligent Programming
- Generate Code: Enter the task description to generate the full code:
response, _ = model.chat(tokenizer, "写一个 Python 脚本实现贪吃蛇游戏", history=[]) - Supports code completion and bug fixes for rapid prototyping.
- Generate Code: Enter the task description to generate the full code:
- context cache (computing)
- Optimize long-dialog performance and reduce double-counting:
model.chat(tokenizer, "继续上一轮对话", cache_context=True)
- Optimize long-dialog performance and reduce double-counting:
- Structured Output
- Outputs JSON format for easy system integration:
response = model.chat(tokenizer, "列出 Python 的基本数据类型", format="json")
- Outputs JSON format for easy system integration:
caveat
- Using transformers 4.49.0 may have compatibility issues, 4.48.3 is recommended.
- The vLLM API supports up to 300 images in a single input.
- Make sure the GPU driver supports CUDA 11.8 or above.
application scenario
- web development
GLM-4.5 generates front-end and back-end code that supports rapid construction of modern web applications. For example, creating interactive web pages requires only a few sentences of description. - intelligent question and answer (Q&A)
The model parses complex queries and combines web search and knowledge bases to provide accurate answers, suitable for customer service and education scenarios. - Smart Office
Automatically generate logical and clear PPTs or posters with support for expanding content from headings, suitable for office automation. - code generation
Generates code in Python, JavaScript, etc., supports multiple rounds of iterative development, and is suitable for rapid prototyping and bug fixing. - complex translation
Translate lengthy academic or policy texts with semantic consistency and style suitable for publication and cross-border services.
QA
- What is the difference between GLM-4.5 and GLM-4.5-Air?
GLM-4.5 (355 billion parameters, 32 billion active) is suitable for high-performance reasoning; GLM-4.5-Air (106 billion parameters, 12 billion active) is lighter and suitable for resource-constrained environments. - How to optimize the speed of reasoning?
Use GPU acceleration, enable INT4 quantization, or select GLM-4.5-Air to reduce resource requirements. - Does it support commercial use?
Yes, the MIT license allows free commercial use. - How do you handle long contexts?
Native support for 128K contexts, enableyarnThe parameters can be further expanded.






























