

When building large-scale language model (LLM)-based knowledge base quiz applications, developers commonly employ retrieval-enhanced generation (RAG) techniques. However, the practical effectiveness of RAG is often limited by a central paradox: how to balance the retrieval of theprecisioncontextualcompletenessIf the text chunk is too small, it can accurately hit the user's query, but it does not provide enough context for the LLM, leading to a decrease in answer quality. If the text slice (Chunk) is too small, although it can accurately hit the user query, the context provided to the LLM is insufficient, leading to a decrease in the quality of the answer; if the slice is too large, although the context is complete, too much noise may be introduced, which in turn reduces the accuracy of the retrieval.
In order to meet this challenge. Dify Introduced in version 1.9.0 as a new feature named Parent-child-HQ A built-in knowledge processing pipeline template. The template adopts the "Parent-Child Chunking" (Parent-Child Chunking) strategy, through a clever hierarchical chunking method, trying to achieve both the fish and the bear's paw at the same time. In this paper, we will analyze this feature from the core concept, practice configuration and source code implementation of three levels.
Core concept: father-son chunking strategy
The core idea of the "parent-child chunking" strategy is to structure the text information into two levels for processing, so as to decouple the different requirements for text granularity in the two aspects of retrieval matching and content generation.
- Child Chunks for Exact Match: The original document is split into a series of fine-grained, highly centralized "sub-chunks". These sub-chunks are usually a sentence or a short paragraph, and are used exclusively for semantic similarity computation with the user's query vector. Due to their small granularity, very accurate matches can be achieved.
- Parent Chunks are used to provide full contextEach sub-chunk belongs to a larger "parent", which may be a complete paragraph, a section, or even an entire document. Once the system has targeted the most relevant matches through the child chunks, it is the complete "parent chunk" containing the child chunks that is actually fed into the LLM for content generation.
This mechanism ensures that the LLM "reads" the most complete original context in which the matching information is located when answering a question, thus generating a logically coherent and informative response.
This advanced strategy relies on vector retrieval to compute semantic similarity, and therefore only supports the Dify knowledge base for the HQ (High Quality) Indexing mode. The high-quality mode will vectorize the text by Embedding model, which supports vector retrieval and hybrid retrieval; while the economical mode only constructs inverted indexes based on keywords, which can not satisfy the operation requirements of parent-child chunking.

Practice Guide: Configuring the Parent-Child-HQ Knowledge Base
To use this feature in Dify, you first need to install the Parent-child-HQ This knowledge base handles process templates.
After installation, the most central node in the pipeline is the "parent-child text chunking".
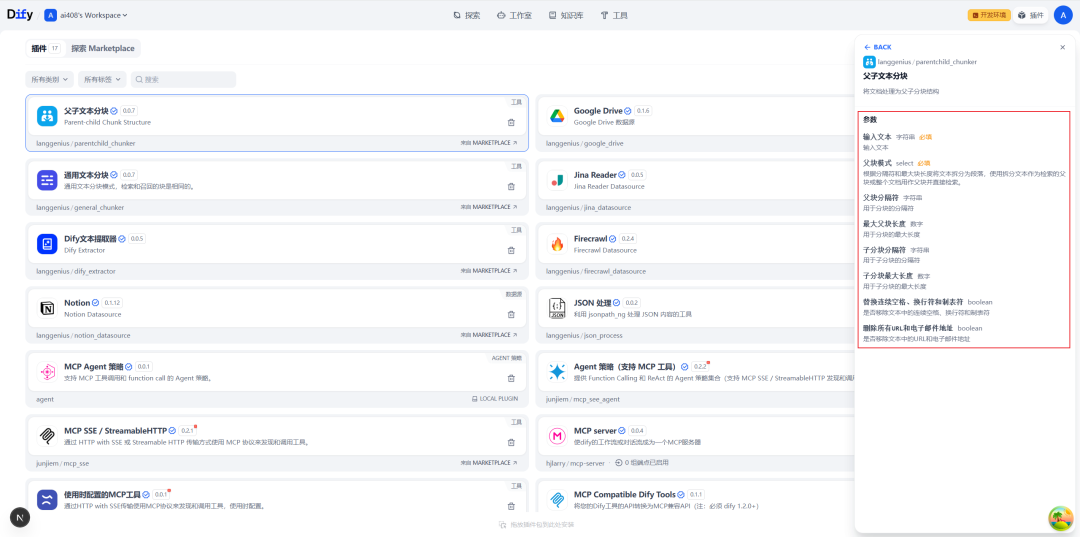
Chunking Node Configuration
In the settings screen of this node, you can define the splitting rules of parent and child blocks in detail.
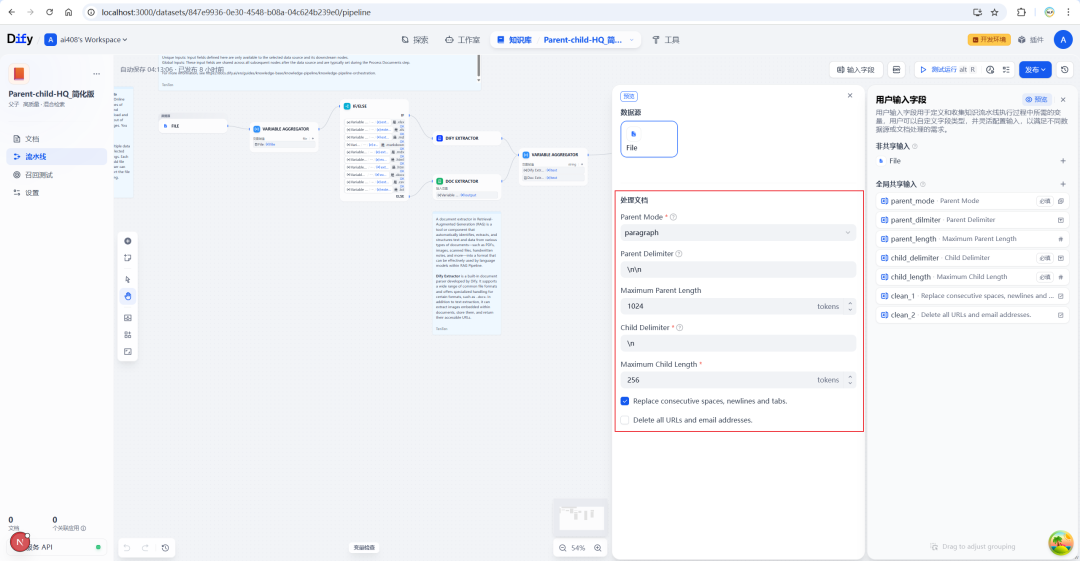
| configuration item | clarification |
|---|---|
| parent chunk separator | Defines how to slice out the parent block. This is usually done using the \n\n(two line breaks) to split by paragraph. |
| Maximum length of parent chunk | Maximum character limit for a single parent block. |
| sub-chunk separator | Defines how to further slice sub-blocks inside the parent block. This can be done using the \n(single newline character) Split by line. |
| Maximum sub-chunk length | Maximum character limit for a single sub-block. |
| parent block model | Define the scope of the parent block, provide paragraph(paragraph) and full_doc(full documentation) two modes. |
In this case, the "parent block pattern" determines the macro boundary of the context:
- Paragraph patterns (
paragraph mode): Split text into multiple parent blocks by separator (e.g. paragraph). This is the most commonly used mode and strikes a good balance between precision and contextual scope. - Whole-text mode (
full_doc mode): treat the entire document as one huge parent block (over 10,000) tokens (the part that will be truncated). This mode is suitable for specific scenarios where a global context is required.
In addition, preprocessing options support the removal of extra spaces, URLs and e-mail addresses from text to improve data quality.
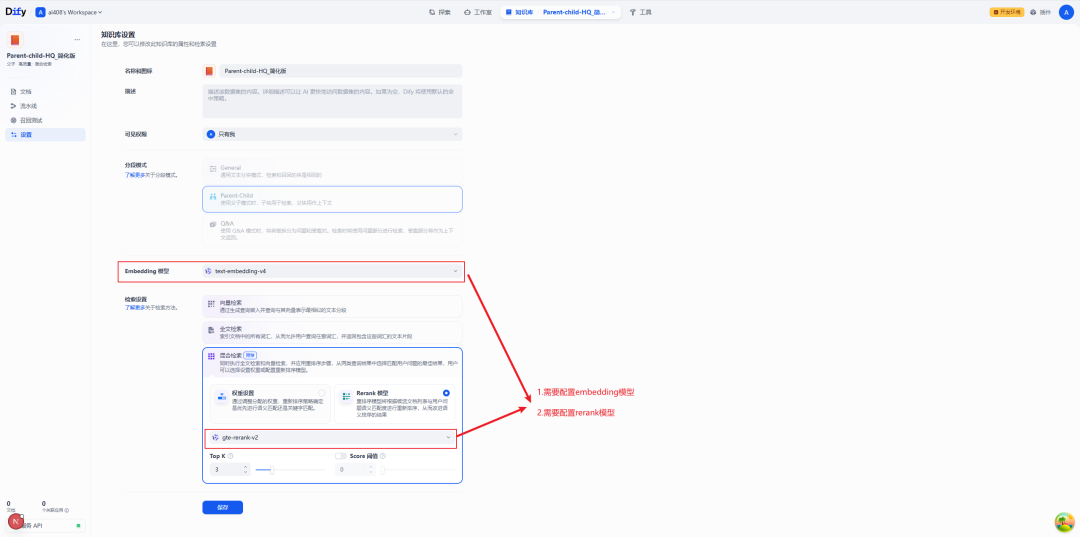
Setting up a high-quality index
As mentioned earlier.Parent-Child The model must be used in conjunction with the HQ index. Therefore, you need to configure the Embedding model and the Rerank model in the Knowledge Base settings.
Commissioning and Operation
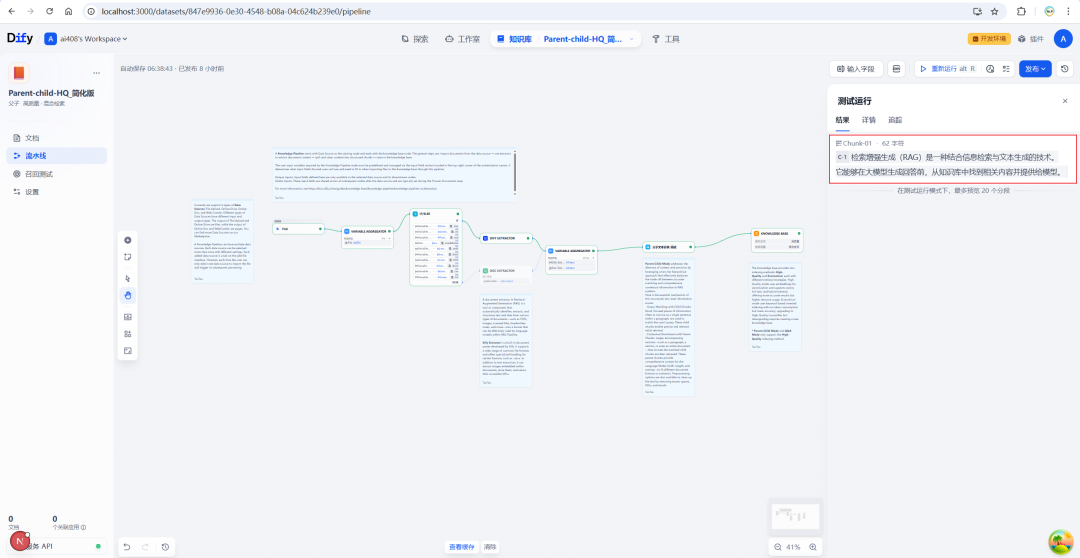
After completing all the configurations, you can test the chunking effect through the debugging function. Enter the sample text and run the pipeline to clearly see how the original text is organized into parent-child structures.
The final run results will show the parent block and the list of child blocks it contains in a structured form.
Architecture Deep Dive: Implementation Logic at the Code Level
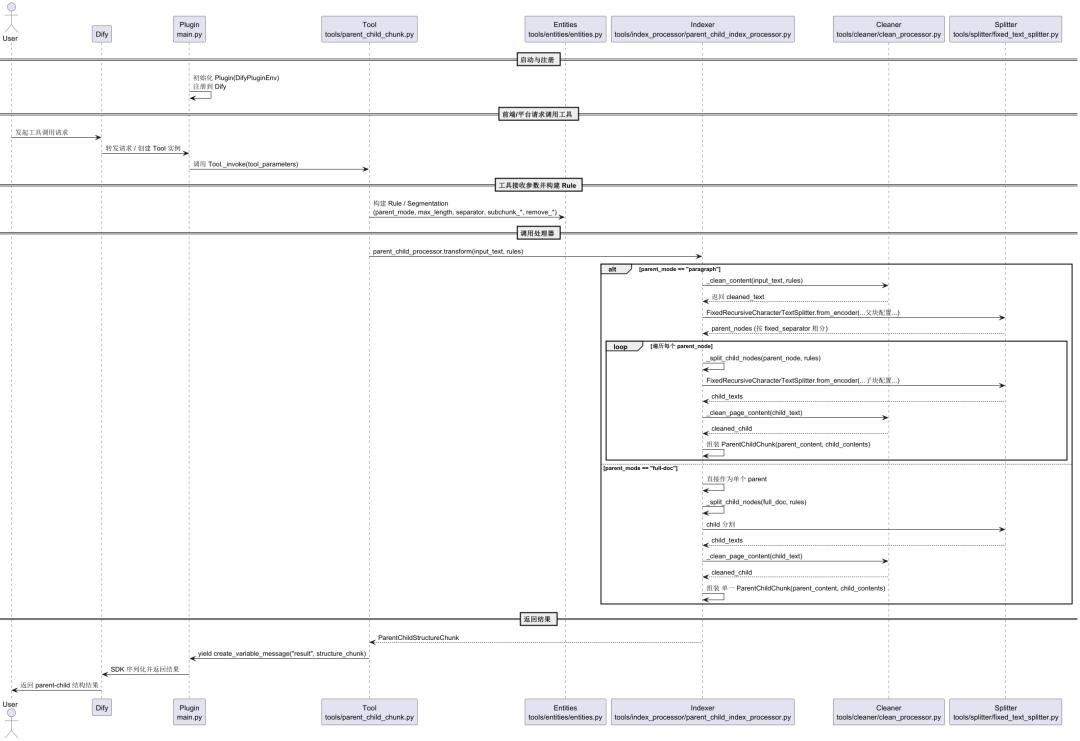
To better understand how it works, we dive into the parentchild_chunker The source code of the plug-in is analyzed. The UML timing diagram below summarizes the complete flow of the plug-in from startup, to receiving data, to processing and returning results.
The entire data processing process can be summarized in the following key steps:
1. Plug-in activation and tool invocation
When the Dify platform starts up, themain.py file serves as the plugin entry point and is responsible for initializing and registering it with Dify. ParentChildChunkTool The capabilities of the The tool's front-end forms, input parameters, and output formats are provided by the tools/parent_child_chunk.yaml File Definition.
When the user invokes the tool, the Dify SDK instantiates the tools/parent_child_chunk.py defined in ParentChildChunkTool class and call its _invoke method, which takes the parameters passed in by the front-end (such as the input_text、parent_mode etc.) passed in.
2. Core processing and text cleaning
_invoke The core responsibility of the method is to call the tools/index_processor/parent_child_index_processor.py defined in ParentChildIndexProcessorIt's the pivot of the whole business logic. This is the centerpiece of the entire business logic.
Before chunking, the text will first go through the tools/cleaner/clean_processor.py hit the nail on the head CleanProcessor Cleaning. This module is responsible for removing invalid characters and selectively merging redundant spaces or removing URLs and email addresses according to user configuration to ensure the quality of the text for subsequent processing.
3. Intelligent text segmentation
Text segmentation is the technical core of the parent-child chunking strategy, and is mainly performed by the tools/splitter/ Multiple splitter implementations in the directory. Among them, theFixedRecursiveCharacterTextSplitter It's the key.
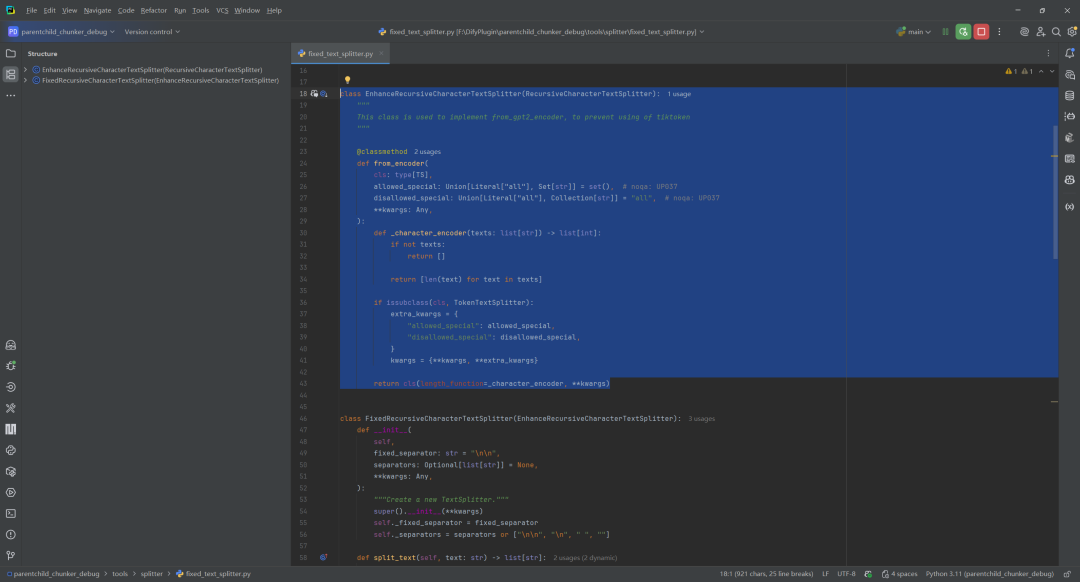
Two key classes need to be distinguished here:
EnhanceRecursiveCharacterTextSplitter: Its main improvement is that it provides a way to create a new system based on the number of characters (instead of thetiktoken) calculates the text length in a way that avoids dependence on a specific tokenizer. The segmentation logic is consistent with standard recursive character splitters.FixedRecursiveCharacterTextSplitter: This class adds a key step to recursive partitioning - theStart by using a fixed, high-priorityfixed_separator(e.g. for paragraphs\n\n) Perform the initial division. Then, the internal recursive logic is called again to subdivide only those blocks that exceed the length limit.
This strategy of "coarsening and refining" perfectly matches the needs of the parent-child chunking: first through the \n\n Divide the semantically complete parent block (paragraph), and then use finer delimiters within the parent block (e.g. \n) Cut out sub-blocks.
4. Data structure construction and return
After cleaning and splittingParentChildIndexProcessor will be based on paragraph 或 full-doc pattern that assembles a list of parent block contents and their corresponding child block contents into the ParentChildChunk objects. These objects are eventually encapsulated in the ParentChildStructureChunk in the structure.
The definitions of these data structures are located in the tools/entities/entities.pyThe use of the Pydantic model ensures that the data is normalized and consistent.
Finally.ParentChildChunkTool pass (a bill or inspection etc) yield self.create_variable_message(...) Return the processed structured data to the Dify SDK to complete the execution of the entire pipeline node.
With this well-designed processing flow and flexible text splitter, theParent-child-HQ Templates provide developers with a powerful and elegant tool that effectively solves the problem of RAG The persistent context-accuracy trade-off puzzle in applications.





























