



DeepSieve is an open source Retrieval Augmented Generation (RAG) framework hosted on GitHub that focuses on processing complex queries and multi-source data. It provides efficient information filtering capabilities by decomposing queries, routing sub-questions, reflecting on failed retrievals and fusing answers.Developed by MinghoKwok, DeepSieve supports processing structured data (e.g., SQL tables, JSON logs) and unstructured data (e.g., Wikipedia), and is suitable for scenarios requiring multi-step reasoning. It emphasizes on modular design, users can adjust the functions according to their needs, and it is suitable for researchers and developers to handle complex data analysis tasks. The project was released as a preprint on arXiv on July 29, 2025, and the full corpus has been uploaded to Arkiv.
Function List
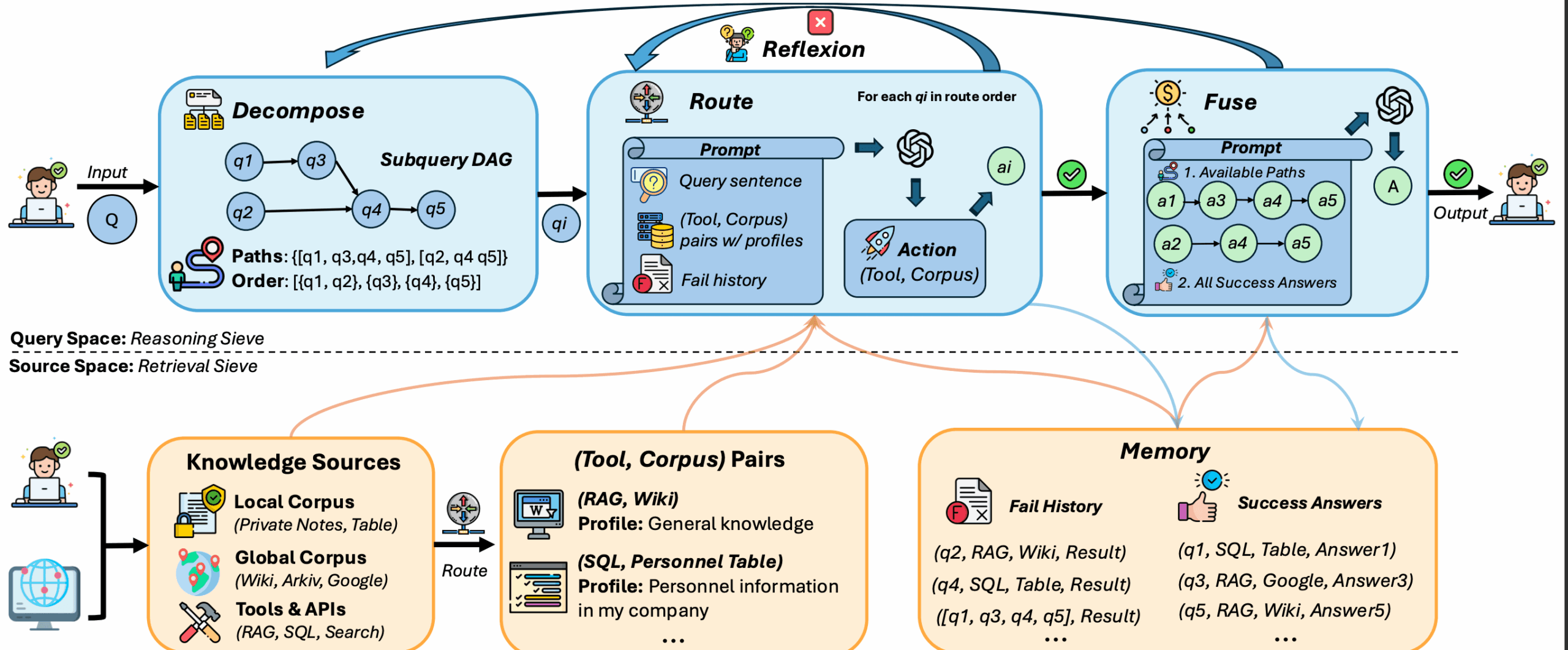
- Query decomposition : Split a complex query into multiple simple sub-problems to facilitate precise processing.
- Sub-issue routing : Intelligent assignment of sub-questions to appropriate tools or data sources (e.g., local databases or global knowledge bases).
- Reflection mechanisms : Automatically detects failed searches and retries them, supporting up to two reflections.
- Convergence of answers : Integrate sub-question answers to generate the final complete response.
- Supports multiple data sources : Handles heterogeneous data such as SQL tables, JSON logs, Wikipedia, etc.
- Two RAG modes : Provides two search modes, Naive and Graph, to suit different needs.
- Detailed logging : Save intermediate results, fusion hints and performance metrics for each query for debugging and optimization.
- modular design : Users can enable or disable function modules with command line switches for flexibility.
Using Help
Installation process
DeepSieve is a Python based open source project , you need to clone the repository through GitHub and configure the environment . Here are the detailed steps:
- clone warehouse
Run the following command in a terminal to clone the DeepSieve repository locally:git clone https://github.com/MinghoKwok/DeepSieve.gitGo to the project catalog:
cd DeepSieve - Installation of dependencies
The project relies on Python 3.7+ and related machine learning and data processing libraries. Install the dependencies:pip install -r requirements.txtin the event that
requirements.txtNot provided, manual installation of the core library is recommended:pip install numpy pandas scikit-learn openaiIt is recommended to use a virtual environment to avoid dependency conflicts:
python -m venv venv source venv/bin/activate # Linux/macOS venv\Scripts\activate # Windows - Configuring Environment Variables
DeepSieve uses the Large Language Model (LLM) to process queries that require configuration of API keys. For example, using the DeepSeek Model:export OPENAI_API_KEY=your_api_key export OPENAI_MODEL=deepseek-chat export OPENAI_API_BASE=https://api.deepseek.com/v1Depending on the usage mode (Naive or Graph), set the RAG Type:
export RAG_TYPE=naive # 或 graph - Verification Environment
Ensure that all dependencies are installed correctly and that the API key is valid. If using a custom data source, check that the data file path is configured correctly.
Run DeepSieve
DeepSieve runs from the command line and offers flexible parameter configuration. The following is the basic usage:
Naive RAG model
Naive mode is suitable for simple tasks. run the following command:
export RAG_TYPE=naive
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
--dataset: Specify the dataset (e.g.hotpot_qa)。--sample_size: Set the number of treatment samples.--decompose: Enable query decomposition.--use_routing: Enable sub-problem routing.--use_reflection: Enable reflective mechanisms.--max_reflexion_times: Set the maximum number of reflections.
Graph RAG mode
Graph mode is suitable for complex queries and requires graph structure support:
export RAG_TYPE=graph
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
Disable Modules
Users can disable features by removing command line parameters. Example:
- Not using query decomposition: remove
--decompose。 - Not using routes: remove
--use_routing。 - Reflections not used: remove
--use_reflection。
output result
The following files are generated for each run:
- Results for each query:
outputs/{rag_type}_{dataset}/query_{i}_results.jsonl - Fusion Tip:
outputs/{rag_type}_{dataset}/query_{i}_fusion_prompt.txt - Overall performance metrics:
overall_results.txt和overall_results.json
Main Functions
Query decomposition
DeepSieve splits complex queries into sub-problems. For example, the query "Revenue and number of employees of a company in 2023" is split into:
- Subquestion 1: Find the company's revenue in 2023.
- Sub-question 2: Find the number of employees in a company.
Operational Steps:
- Enter a query to a script or command line.
- Run the script and DeepSieve automatically breaks down the query and displays the sub-issues (viewable in the log).
Sub-issue routing
Each sub-question is assigned to the appropriate tool or data source. Example:
- Structured data(e.g., SQL tables) routed to database query tools.
- Unstructured data (e.g., Wikipedia) is routed to text retrieval tools.
There is no need for users to manually specify, DeepSieve does the routing automatically. Check Log Filesquery_{i}_results.jsonlRoute details can be viewed.
Reflection mechanisms
If a sub-issue retrieval fails, DeepSieve automatically retries up to two times. The reflection process is recorded in the log, and the user can view the reason for failure and the retry result.
Convergence of answers
DeepSieve consolidates the sub-question answers to generate the final response. For example, the answers to the company query above would be merged into:
- "In 2023 the company will have revenues of $X and Y employees."
Fusion tips are saved in thequery_{i}_fusion_prompt.txt, easy to check by the user.
Precautions for use
- Data preparation : Ensure that the input data is in the correct format (e.g. CSV, JSON) to avoid encoding errors.
- API key : Confirm that the LLM API key is valid and that the network connection is stable.
- Log checking : View after running
outputs/directory, analyzing performance metrics and error logs. - Community Support : If you encounter problems, visit the GitHub Issues page or the arXiv paper for more information.
application scenario
- academic research
Researchers process data from multiple sources (e.g., Wikipedia and experimental databases) to quickly answer complex questions with DeepSieve. For example, analyzing biological datasets and genetic associations in the literature. - Business Data Analytics
Enterprise analysts use DeepSieve to process sales data and customer logs to answer multidimensional questions such as, "Which products will have the highest sales and high customer satisfaction in 2023?" . - Privacy Sensitive Scenarios
DeepSieve supports private data sources (e.g., internal databases) to process queries without merging data, suitable for financial or healthcare industries. - open source development
Developers take advantage of DeepSieve's modular design to extend functionality or integrate into existing systems for customized data processing.
QA
- What data sources does DeepSieve support?
Support for SQL tables, JSON logs, Wikipedia, etc. For details, please refer to the project documentation or configuration file. - How do I debug a runtime error?
probeoutputs/log file in the directory to see the error details. Make sure the dependency library version is correct and the API key is valid. - Difference between Graph mode and Naive mode?
Naive mode is suitable for simple queries and is fast; Graph mode is suitable for complex multi-step reasoning with higher accuracy but increased computational cost. - How do I contribute code?
Fork the repository, modify the code and submit a Pull Request.CONTRIBUTING.mdDocumentation that follows the code specification.


























