



DeepSeek-OCR is an optical character recognition (OCR) tool developed and open sourced by DeepSeek-AI. It proposes a new approach called "Contextual Optical Compression", which rethinks the role of the visual coder from the perspective of the Large Language Model (LLM). Instead of simply recognizing the text in an image, the tool renders long textual content such as a document page as an image, and then compresses the image into a smaller set of "vision tokens". The language model decoder then reconstructs the original text from these vision tokens. This approach can reduce the number of input tokens by a factor of 7 to 20, which allows large models to use fewer computational resources to deal with very long documents, improving processing efficiency and speed. The project follows the MIT Open Source License Agreement.
Function List
- Contextual Optical Compression: By compressing images into visual tokens, the amount of data processed by the model is dramatically reduced, lowering memory usage and increasing inference speed.
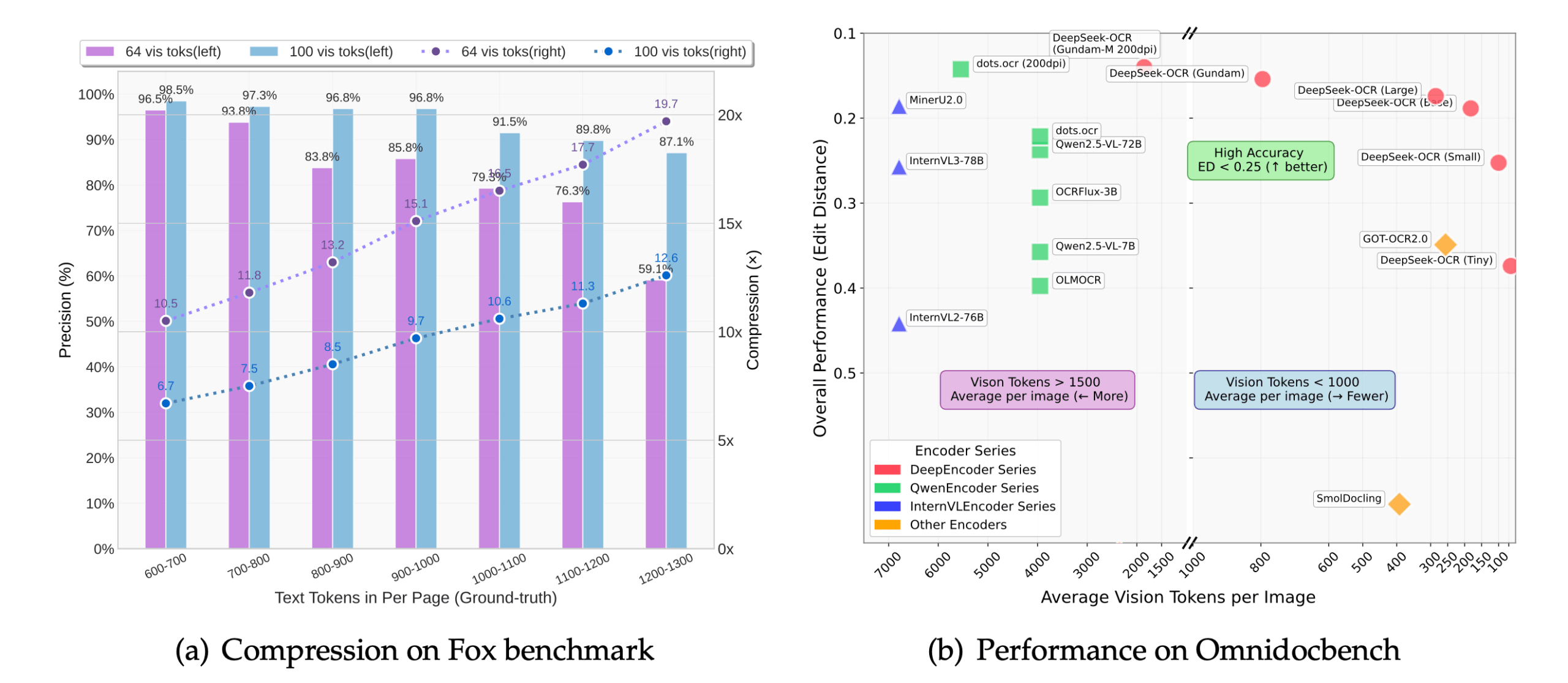
- High-precision recognition: Under 10x compression, it can still achieve a recognition accuracy of about 97%, which can preserve the layout, typography and spatial relationship of the document.
- Structured Output: The ability to convert documents, especially pages containing complex layouts (e.g. tables, lists, headings), directly into Markdown format, preserving the structure of the original text.
- Multi-task support: By modifying the input prompt word (Prompt), the model can perform different tasks, for example:
- Convert the entire document to Markdown.
- Generic OCR recognition of images.
- Parses the charts in the document.
- Describe the content of the image in detail.
- Multiple resolution modes: Supports a wide range of fixed resolutions from 512 x 512 to 1280 x 1280, as well as a dynamic resolution mode for processing ultra-high resolution documents.
- High Performance Reasoning: Integrated with vLLM and Transformers framework, it can reach a speed of about 2500 tokens/second when processing PDF files on A100-40G GPUs.
- handwriting recognition: Recognizes handwritten content better than many traditional OCR tools under good lighting and resolution.
Using Help
The installation and use of DeepSeek-OCR is mainly oriented to developers, and requires a certain programming foundation. The following is the detailed operation procedure, which is mainly divided into three parts: environment configuration, installation and code reasoning.
Step 1: Environmental preparation
The official recommended environments are CUDA 11.8 and PyTorch 2.6.0. Before you start, you need to install Git and Conda.
- Cloning Project Warehouse
First, clone the official DeepSeek-OCR codebase from GitHub to your local computer. Open a terminal (command line tool) and enter the following command:git clone https://github.com/deepseek-ai/DeepSeek-OCR.gitWhen executed, it creates a file in the current directory named
DeepSeek-OCRof the folder. - Create and activate the Conda environment
To avoid dependency conflicts with other Python projects on your computer, it is recommended to create a separate Conda virtual environment.# 创建一个名为deepseek-ocr的Python 3.12.9环境 conda create -n deepseek-ocr python=3.12.9 -y # 激活这个新创建的环境 conda activate deepseek-ocrAfter successful activation, your terminal prompt will be preceded by the
(deepseek-ocr)Words.
Step 2: Install dependencies
In an activated Conda environment, the Python libraries required for the model to run need to be installed.
- Installing PyTorch
Install the PyTorch version adapted to CUDA 11.8 according to the official requirements.pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 - Install other core dependencies
The project relies on the vLLM library for high performance inference and also requires the installation of therequirements.txtOther packages listed in the file.# 进入项目文件夹 cd DeepSeek-OCR # 安装vLLM(注意:官方提供了编译好的whl文件链接,也可以自行编译) # 示例是下载官方提供的whl文件进行安装 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl # 安装requirements.txt中的所有依赖 pip install -r requirements.txt - Install Flash Attention (optional but recommended)
It is recommended to install the Flash Attention library for optimal running speed.pip install flash-attn==2.7.3 --no-build-isolationAttention: You can also leave this library uninstalled if your GPU is not supported or the installation fails. Later in the code you will need to remove the
_attn_implementation='flash_attention_2'With this parameter, the model will run but will be slower.
Step 3: Run the inference code
DeepSeek-OCR provides two mainstream inference approaches: based on theTransformersThe library's one-shot inference and the one-shot inference based onvLLMof high-performance batch inference.
Approach 1: Fast reasoning using Transformers (good for single image testing)
This approach is simple to code and is ideal for quickly testing model effects.
- Create a Python file, for example
test_ocr.py。 - Copy the following code into a file. This code will load the model and perform OCR recognition on a specified image.
import torch from transformers import AutoModel, AutoTokenizer import os # 指定使用的GPU,'0'代表第一张卡 os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 模型名称 model_name = 'deepseek-ai/DeepSeek-OCR' # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) # 加载模型,使用flash_attention_2加速,并设置为半精度(bfloat16)以节省显存 model = AutoModel.from_pretrained( model_name, trust_remote_code=True, _attn_implementation='flash_attention_2', use_safetensors=True ).eval().cuda().to(torch.bfloat16) # 定义输入的图片路径和输出路径 image_file = 'your_image.jpg' # <-- 将这里替换成你的图片路径 output_path = 'your/output/dir' # <-- 将这里替换成你的输出文件夹路径 # 定义提示词,引导模型执行特定任务 # 这个提示词告诉模型将文档转换为Markdown格式 prompt = "<image>\n<|grounding|>Convert the document to markdown. " # 执行推理 res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, image_size=640, crop_mode=True, save_results=True, test_compress=True ) print(res) - running code
Place an image to be recognized (e.g.your_image.jpg) into the same directory as the script and then execute it:python test_ocr.pyAt the end of the program run, the recognized text will be printed in the terminal, while the result will be saved in the output path you specified.
Way two: use vLLM for batch reasoning (suitable for processing a large number of images or PDF)
The vLLM mode is more performant and suitable for production environments.
- Configuration file modification
go intoDeepSeek-OCR-master/DeepSeek-OCR-vllmdirectory, open theconfig.pyfile, modify the input path in it (INPUT_PATH) and the output path (OUTPUT_PATH) and other settings. - executable script
Scripts for different tasks are provided in this directory:- Handles streaming image data:
python run_dpsk_ocr_image.py - Process PDF files:
python run_dpsk_ocr_pdf.py - Run the benchmark test:
python run_dpsk_ocr_eval_batch.py
- Handles streaming image data:
application scenario
- Digitization of documents
After scanning paper books, contracts, reports, etc. into images, use DeepSeek-OCR to quickly convert them into editable, searchable electronic text with excellent retention of the original captions, lists, and table structures. - Extraction of information
Automatically extract key information, such as amount, date, project name, etc., from images of invoices, receipts, forms, etc., to automate data entry and reduce manual operations. - Education and research
Researchers can use this tool to quickly identify and convert textual content in papers, ancient books, archives, and other documentary materials for subsequent data analysis and content retrieval. - Accessibility applications
By recognizing text in images and generating detailed descriptions, it can help visually impaired users to understand the content of the images, for example to read menus, road signs or product instructions.
QA
- Is DeepSeek-OCR free?
Yes, DeepSeek-OCR is an open source project that follows the MIT license and is free for users to use, modify and distribute. - What languages does it support?
The model mainly demonstrates its strong capability in processing English and Chinese documents. Since it is based on a large language model, it theoretically has the potential for multi-language processing, but the exact effect needs to be evaluated based on actual testing. - What is the principle of processing PDF files?
DeepSeek-OCR itself deals with images. When a PDF file is input, the program first renders (converts) each page of the PDF into an image, then OCRs these images page by page, and finally merges the results of all the pages into a single output. - Can I use it without an NVIDIA GPU?
The official documentation and tutorials are based on NVIDIA GPU and CUDA environments. Although the model can theoretically run on a CPU, it will be very slow and not suitable for practical applications. Therefore, it is highly recommended to use it on a device equipped with an NVIDIA GPU. - What are the benefits of "contextual optical compression"?
The main benefit is efficiency. When traditional models process long text, the computational and memory footprint increases dramatically with the length of the text. By compressing text images into a small number of visual tokens, DeepSeek-OCR can process the same or even longer content with fewer resources, making it possible to process large-scale documents on limited hardware.































