



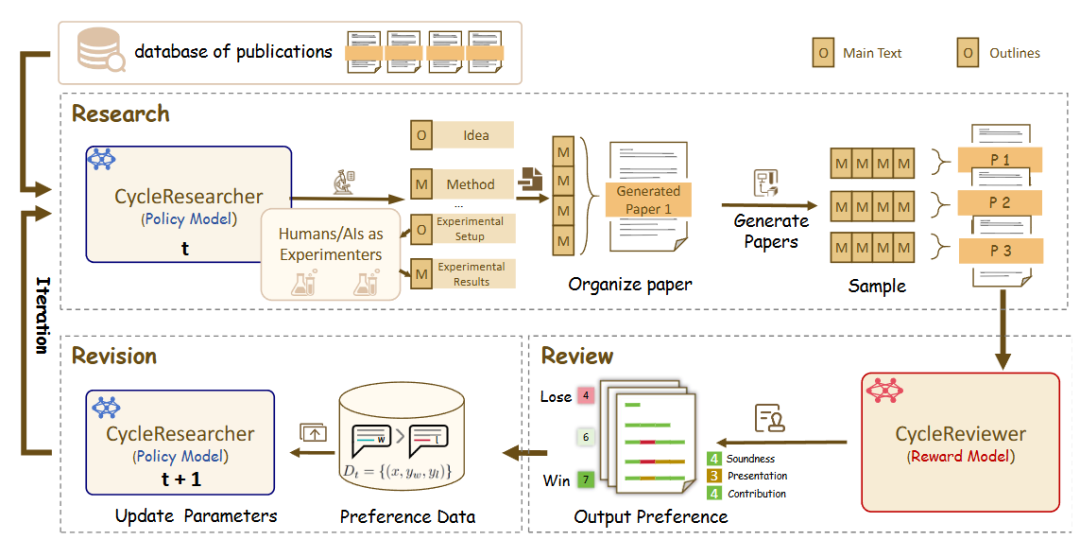
CycleResearcher is an open source AI-driven academic research and review ecosystem designed to improve the efficiency of academic research through automated tools. It consists of three core components: CycleResearcher for generating high-quality academic papers, CycleReviewer for providing detailed academic reviews, and DeepReviewer for simulating multiple reviewers and self-validation. This system accelerates scientific discovery and reduces labor costs through closed-loop feedback between research and review. It supports multiple models and datasets and is suitable for researchers, students and developers. Users can get started quickly through simple installation and API calls, and it is suitable for academic writing, paper review and other scenarios.
Function List
- Paper Generation: CycleResearcher generates academic papers based on user-supplied topics and references, and supports multiple models (e.g. 12B, 72B, 123B).
- Academic reviewer: CycleReviewer provides a detailed review of papers, outputting average ratings and acceptance/rejection decisions with an accuracy of 74.241 TP3T.
- Multi-perspective review of manuscripts: DeepReviewer simulates multiple reviewers and offers three modes, Fast, Standard and Best, with support for background knowledge search and self-validation.
- AI Detection: Built-in AIDetector tool that analyzes whether a paper was generated by AI and outputs probabilities and confidence levels.
- Literature Search: OpenScholar integrates scholarly Q&A functionality and supports literature retrieval through the Semantic Scholar API.
- Easy to integrate: Provides Python libraries and API interfaces for developers to embed into existing workflows.
- Multi-model support: Supports a variety of pre-trained models such as Mistral, Llama3.1 and Qwen2.5 to meet different performance requirements.
Using Help
Installation process
CycleResearcher is very easy to install, you just need to run the following command in your Python environment:
pip install ai_researcher
Make sure Python version is 3.8 or above. If you need to use OpenScholar, you will also need to request a Semantic Scholar API key and start the relevant services.
OpenScholar Installation and Startup
- Requesting an API Key: Access Semantic Scholar API Apply for a key.
- Starting the modeling service:
cd OpenScholar chmod +x start_models.sh ./start_models.sh - Starting the API Service:
python openscholar_api.py \ --s2_api_key YOUR_SEMANTIC_SCHOLAR_API_KEY \ --reranker_path OpenSciLM/OpenScholar_Reranker - Test API:
Send questions using the Python requests library:import requests response = requests.post("http://localhost:38015/batch_ask", json={ "questions": ["检索增强语言模型在知识密集任务中的表现如何?"] }) print("OpenScholar 回答:", response.json()["results"][0]["output"])
Using CycleResearcher to Generate Papers
CycleResearcher generates academic papers based on specific topics and references. Below are the steps:
- Initialization Model:
from ai_researcher import CycleResearcher from ai_researcher.utils import print_paper_summary researcher = CycleResearcher(model_size="12B")The 12B model is used by default and is suitable for most tasks.
- Loading references:
Prepare the reference file in BibTeX format (e.g.cycleresearcher_references.bib) and then read:with open('cycleresearcher_references.bib', 'r') as f: references_content = f.read() - Generating a Thesis:
Assign topics and references to generate a paper:generated_papers = researcher.generate_paper( topic="AI Researcher", references=references_content, n=1 ) print_paper_summary(generated_papers[0])The generated paper will contain a complete structure of abstract, introduction and references.
Review of manuscripts using CycleReviewer
CycleReviewer provides automated reviewing features suitable for quickly assessing the quality of a paper.
- Initialization Model:
from ai_researcher import CycleReviewer reviewer = CycleReviewer(model_size="8B") - reviewer:
suppose that...paper_textIt is the textual content of the paper to be reviewed that runs:review_results = reviewer.evaluate(paper_text) print(f"平均评分: {review_results[0]['avg_rating']}") print(f"审稿决定: {review_results[0]['paper_decision']}")The output consisted of a mean score and a decision of whether to accept or not, with an accuracy of 74.241 TP3T.
Multi-Perspective Reviewing with DeepReviewer
DeepReviewer offers more sophisticated reviewing capabilities, supporting multiple modes and multiple simulated reviewers.
- Initialization Model:
from ai_researcher import DeepReviewer deep_reviewer = DeepReviewer(model_size="14B") - Review of the standard model:
Simulation of 4 reviewers:review_results = deep_reviewer.evaluate( paper_text, mode="Standard Mode", reviewer_num=4 ) for i, review in enumerate(review_results[0]['reviews']): print(f"审稿人 {i+1} 评分: {review.get('rating', 'N/A')}") print(f"审稿人 {i+1} 摘要: {review.get('summary', 'N/A')[:100]}...") - Optimal model review:
Enabling background knowledge search and self-validation:review_results = deep_reviewer.evaluate( paper_text, mode="Best Mode", reviewer_num=6, enable_search=True, self_verification=True )The optimal model is suitable for scenarios that require in-depth analysis, providing more comprehensive feedback.
Detecting AI-generated content with AIDetector
Detect whether the paper is generated by AI:
from ai_researcher import AIDetector
detector = AIDetector(device='cpu')
detection_result = detector.analyze_paper(paper)
print(f"AI 生成概率: {detection_result['probability'] * 100:.2f}%")
print(f"置信度: {detection_result['confidence_level']}")
Querying Academic Questions with OpenScholar
OpenScholar supports search-based academic Q&A, which is ideal for quickly finding literature or answering questions. After running the API service, questions are sent via HTTP requests:
response = requests.post("http://localhost:38015/batch_ask", json={
"questions": ["如何提升语言模型在学术研究中的表现?"]
})
print(response.json()["results"][0]["output"])
caveat
- Model Selection: Select the appropriate model (e.g., 12B, 14B) based on the task requirements; larger models are suitable for complex tasks.
- API key: OpenScholar requires the Semantic Scholar API key, make sure it is requested and configured correctly.
- hardware requirement: DeepReviewer's optimal mode requires high computing power and GPU acceleration is recommended.
- Dataset Support: The system provides datasets such as Review-5K, Research-14K, etc., which can be used for model fine-tuning or testing.
application scenario
- Academic paper writing
Researchers can use CycleResearcher to quickly generate a first draft of a paper, incorporating references to generate structured content for first draft ideas or inspiration. - Review of papers
Academic conference organizers or journal editors can save time by automating the review process with CycleReviewer and DeepReviewer, which simulates multiple reviewers providing objective evaluations. - Answers to academic questions
Students and researchers can use OpenScholar to inquire about academic issues, quickly access literature support, or answer complex questions. - AI Content Detection
Journal editors can use AIDetector to check whether a submitted paper was generated by AI, ensuring academic integrity. - research and development (R&D)
Developers can leverage CycleResearcher's API integration into academic workflows to build customized research tools.
QA
- What models does CycleResearcher support?
CycleResearcher-ML-12B, 72B, 123B, CycleReviewer-ML-Llama3.1-8B, 70B, 123B, and DeepReviewer-7B, 14B are supported, all based on mainstream pre-trained models. - How to choose the review mode of DeepReviewer?
Fast Mode for quick feedback, Standard Mode for balancing accuracy and speed, and Best Mode for in-depth analysis. - Does OpenScholar require additional configuration?
The Semantic Scholar API key is required and starts the model and API services, as described in the installation process. - What is the quality of the papers generated?
CycleResearcher-12B achieved an average rating of 5.36, which is close to the 5.69 for conference accepted papers and better than other AI tools. - Does it support Chinese paper generation?
Currently, the papers are mainly in English, but can be fine-tuned to support Chinese, requiring the user to provide the relevant dataset.



























