



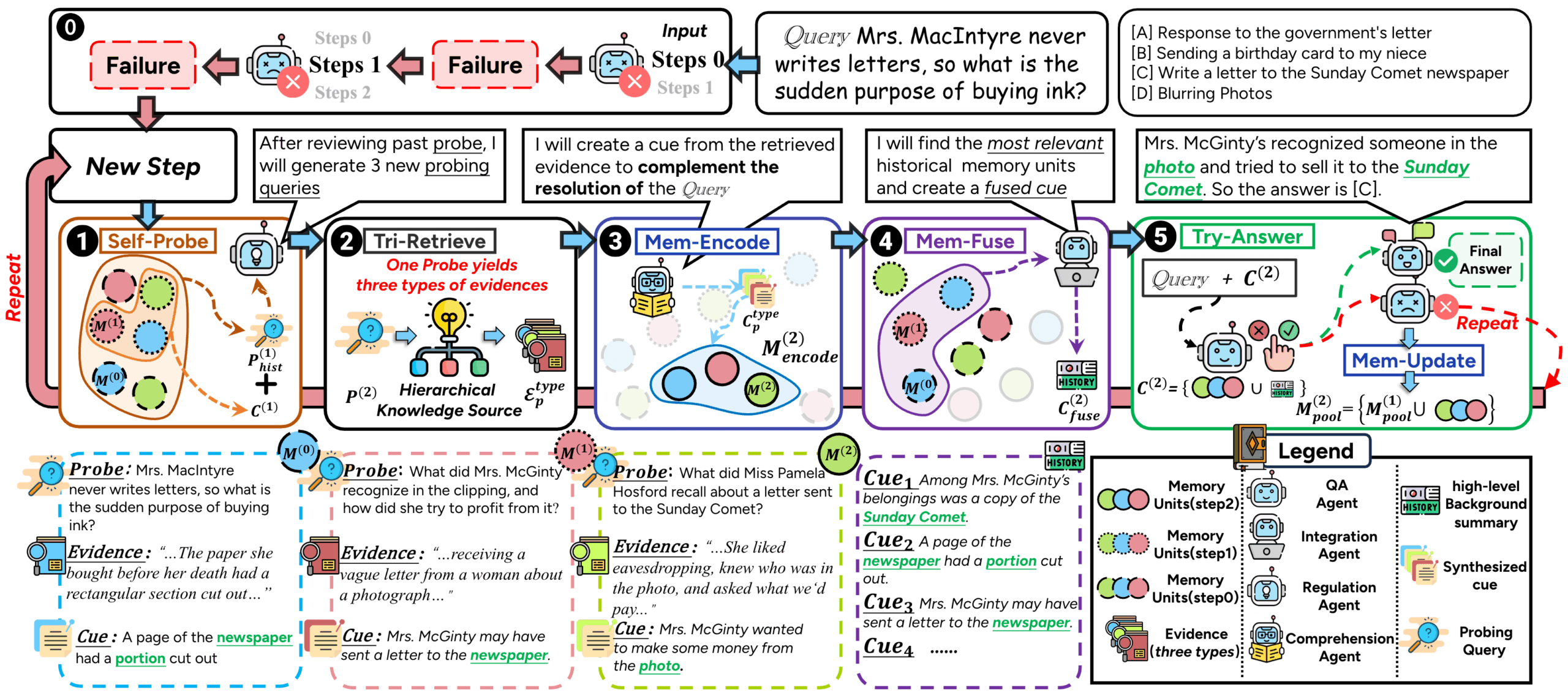
ComoRAG is a Retrieval Augmented Generation (RAG) system designed to address long documents and multi-document narrative comprehension. Traditional RAG methods often encounter difficulties when dealing with long stories or novels due to complex plots and evolving character relationships. This is due to the fact that most of them use a stateless, one-shot retrieval approach, which makes it difficult to capture long-distance contextual associations. ComoRAG is inspired by the human cognitive process, which recognizes that narrative reasoning is not a one-shot process, but a dynamic, evolving process that requires the integration of newly acquired evidence with existing knowledge. When encountering reasoning difficulties, ComoRAG initiates an iterative reasoning loop. It generates probing questions to explore new clues and integrates the newly retrieved information into a global memory pool, gradually building a coherent context for the initial question. This "reasoning→probing→retrieving→integrating→solving" cycle makes it particularly good at handling complex problems that require global understanding.
Function List
- cognitive memory framework: Mimicking the way the human brain processes information, it deals with complex problems through an iterative reasoning cycle, realizing a dynamic, stateful reasoning process.
- Multiple model support: Integration and support for a wide range of large-scale language models (LLMs) and embedded models, allowing users to connect to the OpenAI API or deploy local vLLM servers and embedded models.
- Graph Enhanced Search: Utilize graph structures for retrieval and reasoning to better capture and understand complex relationships between entities.
- Flexible data processing: Provide document chunking tools , support by token , word , sentence and other ways to slice .
- modular design: The system is designed to be modular and extensible, which facilitates users to carry out secondary development and functional expansion.
- Automated assessment: Comes with evaluation scripts that support a variety of metrics such as F1, EM (Exact Match), etc., making it easy to quantitatively evaluate the Q&A effect.
Using Help
ComoRAG is a powerful retrieval-enhanced generative framework that focuses on comprehension and reasoning for processing long narrative texts. It significantly improves the model's performance on tasks such as long text quizzing and information extraction through a unique cognitive iterative loop.
Environment Configuration and Installation
You need to configure the runtime environment before you can start using it.
- Python version: Recommended use
Python 3.10or higher. - Installation of dependencies: After cloning the project code, install all the necessary dependency packages in the project root directory with the following command. GPU environment is recommended for better performance.
pip install -r requirements.txt - environment variable: If you plan to use the OpenAI API, you need to set the appropriate environment variables
OPENAI_API_KEY. If you are using a local model, you need to configure the path to the model.
Data preparation
ComoRAG requires data files in a specific format to run. You will need to prepare corpus files and Q&A files.
- Corpus file (corpus.jsonl): This file contains all the documents that need to be retrieved. The file is
jsonlformat, each line is a JSON object representing a document.id: A unique identifier for the document.doc_id: An identifier for the group or book to which the document belongs.title: Document title.contents: The original content of the document.
Example:
{"id": 0, "doc_id": 1, "title": "第一章", "contents": "很久很久以前..."} - Q&A file (qas.jsonl): This file contains the questions that need to be answered by the model. Again, each line is a JSON object.
id: A unique identifier for the issue.question:: Specific questions.golden_answers:: List of standardized answers to questions.
Example:
{"id": "1", "question": "故事的主角是谁?", "golden_answers": ["灰姑娘"]}
Document chunking
Since long documents cannot be processed directly by the model, they need to be cut into smaller pieces first. The project provides the chunk_doc_corpus.py script to accomplish this.
You can chunk the corpus using the following command:
python script/chunk_doc_corpus.py \
--input_path dataset/cinderella/corpus.jsonl \
--output_path dataset/cinderella/corpus_chunked.jsonl \
--chunk_by token \
--chunk_size 512 \
--tokenizer_name_or_path /path/to/your/tokenizer
--input_path: The path to the original corpus file.--output_path: The path where the file will be saved after chunking.--chunk_by:: Chunking basis, which can betoken、word或sentence。--chunk_size: The size of each chunk.--tokenizer_name_or_path: Specifies the path to the splitter used to compute the token.
Two modes of operation
ComoRAG offers two mainstream ways to run: using the OpenAI API or using a locally deployed vLLM server.
Mode 1: Using the OpenAI API
This is the easiest and quickest way to start.
- Modify Configuration: Open
main_openai.pyfile, find theBaseConfigPartially modified.config = BaseConfig( llm_base_url='https://api.openai.com/v1', # 通常无需修改 llm_name='gpt-4o-mini', # 指定使用的OpenAI模型 dataset='cinderella', # 数据集名称 embedding_model_name='/path/to/your/embedding/model', # 指定嵌入模型的路径 embedding_batch_size=32, need_cluster=True, # 启用语义/情景增强 output_dir='result/cinderella', # 结果输出目录 ... ) - running program: Once the configuration is complete, run the script directly.
python main_openai.py
Mode 2: Using a local vLLM server
You can choose this mode if you have sufficient computational resources (e.g., GPUs) and want to run the model locally to ensure data privacy and reduce costs.
- Starting the vLLM server: First, you need to start a vLLM server that is compatible with the OpenAI API.
python -m vllm.entrypoints.openai.api_server \ --model /path/to/your/model \ --served-model-name your-model-name \ --tensor-parallel-size 1 \ --max-model-len 32768--model: The path to your local biglanguage model.--served-model-name: Assign a name to your model service.--tensor-parallel-size: Number of GPUs used.
- Checking server status: you can use
curl http://localhost:8000/v1/modelscommand to check if the server started successfully. - Modify Configuration: Open
main_vllm.pyfile, modify the configuration in it.# vLLM服务器配置 vllm_base_url = 'http://localhost:8000/v1' served_model_name = '/path/to/your/model' # 与vLLM启动时指定的模型路径一致 config = BaseConfig( llm_base_url=vllm_base_url, llm_name=served_model_name, llm_api_key="EMPTY", # 本地服务器不需要真实的API Key dataset='cinderella', embedding_model_name='/path/to/your/embedding/model', # 本地嵌入模型路径 ... ) - running program: Once the configuration is complete, run the script.
python main_vllm.py
Assessment results
When the program has finished running, the generated results are saved in the result/ directory. You can use the eval_qa.py scripts to automatically evaluate the model's performance.
python script/eval_qa.py /path/to/result/<dataset>/<subset>
The script calculates metrics such as EM (Exact Match Rate) and F1 Score and generates the results.json etc.
application scenario
- Long story/screenplay analysis
For writers, screenwriters or literary researchers, ComoRAG can serve as a powerful analytical tool. Users can import an entire novel or screenplay and then ask complex questions about plot development, the evolution of character relationships, or specific themes, and the system is able to provide insights by integrating information from the entire text. - Enterprise-level Knowledge Base Q&A
Organizations often have a large number of technical documents, project reports, and rules and regulations within their organization, and ComoRAG can handle these long, complex, and interrelated documents by building an intelligent Q&A system. Employees can ask questions directly in natural language, such as "What are the key differences and risks between the technical implementation of scenario A and scenario B in the Q3 project?", and the system can integrate multiple reports to provide accurate answers. The system is able to integrate multiple reports to provide accurate answers. - Study of legal instruments and case files
Lawyers and legal staff need to read a large number of lengthy legal documents and historical files. ComoRAG can help them quickly sort through the case timeline, analyze the correlation between different pieces of evidence, and answer complex questions that require synthesizing multiple documents in order to reach a conclusion, which greatly improves the efficiency of case analysis. - Scientific Research and Literature Review
Researchers need to read and understand a large number of academic papers when conducting a literature review.ComoRAG can assist researchers in asking questions about multiple papers in a field, extracting key information, and constructing a knowledge graph to help them quickly grasp the global dynamics and core challenges of their research field.
QA
- What are the core differences between ComoRAG and traditional RAG methods?
The core difference is that ComoRAG introduces a dynamic iterative reasoning process inspired by cognitive science. While traditional RAGs are usually one-time, stateless searches, ComoRAG actively generates new exploratory questions when it encounters hard-to-answer questions, and conducts multiple rounds of searches and information consolidation to form an ever-expanding "pool of memories" to assist in the final reasoning. - What are the requirements for using a local vLLM server?
Using a vLLM local server usually requires a capable NVIDIA GPU and enough video memory, depending on the size of the model you are loading. Also, the CUDA toolkit needs to be installed. This approach, although complicated to set up initially, provides higher data security and faster inference. - Can I replace my own embedded model?
Yes. ComoRAG's architecture is modular, and you can conveniently add a new version of ComoRAG in theembedding_modelCatalog to add support for new embedded models. Just make sure your model can convert text to vectors and adapt the system's data loading and calling interfaces. - Does this framework support handling multimodal data such as images or audio/video?
From the basic description of the project, ComoRAG is currently focused on processing long text narratives, such as long documents and multi-document Q&A. While its modular design offers the possibility of extending multimodal capabilities in the future, the core functionality of the current version is built around textual data.
































