

preamble
The knowledge of a Large Language Model (LLM) is limited by the cutoff date of its training data. For example, a model trained before January 2025 will not be able to answer events that have occurred since then, such as asking about the current date. Empowering models with networked search capabilities that allow them to answer based on real-time information can greatly expand their application scenarios and improve the accuracy of their answers. Cherry Studio A set of networked search functions are provided, designed to allow any model to connect to the Internet.

This article will detail the Cherry Studio The networking search function provides a detailed configuration and practice guide.
Function Configuration
Before using Networked Search, you need to configure it accordingly. Open the Cherry Studio settings screen, the right-hand area centralizes all web search-related options.
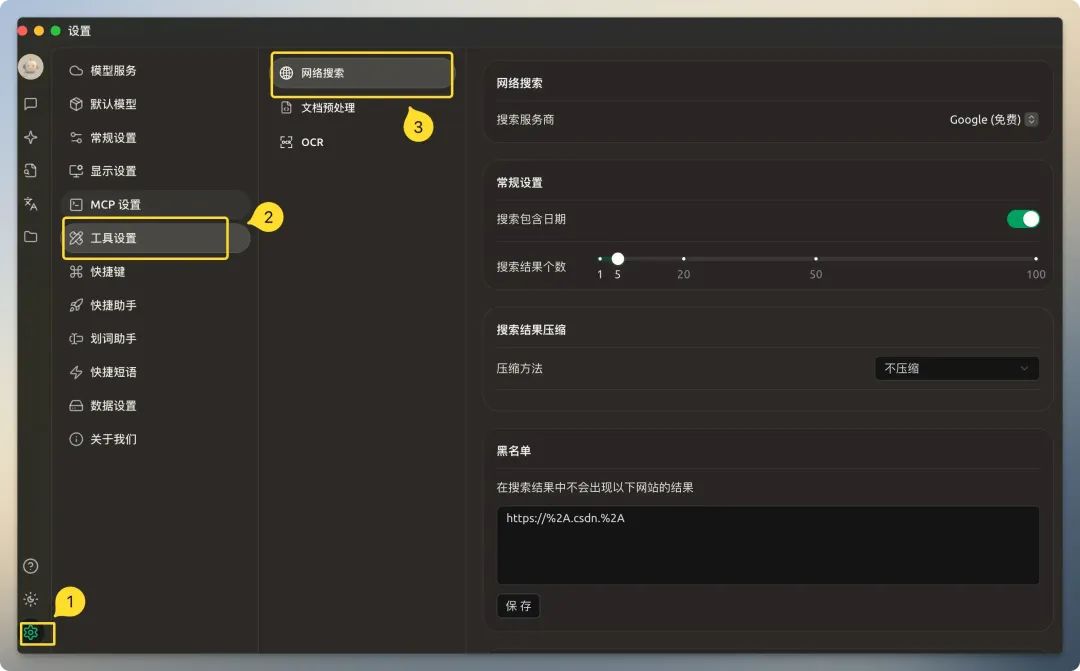
Search Service Provider
Cherry Studio There are a variety of search providers built in. They can be divided into two main categories:Traditional Search Engines(e.g. 百度、谷歌、必应(math.) andAI native search engine(e.g. Tavily、Exa)。
Traditional Search EnginesWhat is returned is a complete web page designed for human visual reading, which contains a lot of navigation bars, advertisements, scripts, and other "noise" unrelated to the core content. Feeding this information directly to the AI model not only dramatically increases the cost of the token, but also reduces the quality of the answer due to information pollution.
AI native search engineOn the other hand, they specialize in serving large language models. They have pre-processed and optimized search results on the backend, returning clean, refined, structured text data that is more suitable for direct machine consumption.

Tavily
Tavily is a service provider specializing in search APIs for large language models. Its core strength is its ability to return highly relevant, refined and structured data, filtering out irrelevant information from traditional web pages, thus reducing the size and cost of the context fed to the model.Tavily s free program offers 1,000 API calls per month with no credit card binding and direct access within China. After signing up, just get the API key in the backend and fill in the appropriate fields.


Searxng
Searxng is an open source meta-search engine (https://github.com/searxng/searxng), which aggregates results from multiple search services. Users can deploy the service themselves by referring to its official documentation for greater privacy and control.

Exa
Exa (formerly known as Metaphor) is another AI-oriented search provider, which is best characterized as offering neural search based on "semantics". Unlike traditional search, which relies on keyword matchingExa It better understands the true intent behind a query (e.g., when you search for "what will the future of AI phones look like", it understands that this is an open-ended, conceptual question) to find deeper and more relevant results. It also supports domain-specific searches, such as essays,Github Warehouse and Wikipedia. New users will get a free $10 credit.


Bocha
domestic 博查 It also offers a multimodal AI search API service, but its service is a purely paid model with no free credits.

Recently launched With the Bing Search API discontinuation looming, could the Secret Tower API be a new option?Also new options.
General Settings
Recommended to turn on "Search contains date" option for more current information. The number of search results is recommended to remain at the default of 5. Setting too many results will not only increase Token consumption, but may also result in processing failures due to exceeding the model's Context Window.

Search results compression
This feature is used to process and refine the content of searched web pages to fit the contextual constraints of the model. Understanding the differences between these three options is critical to optimizing the effectiveness and cost of connected search.

| Compression method | vantage | drawbacks | Applicable Scenarios |
|---|---|---|---|
| uncompressed | Simple to implement and fast to process. | Highly susceptible to exceeding model context limits, high Token cost, and contains a lot of irrelevant information. | Only occasionally available when the model context window is very large and the search results page is very clean. |
| truncate | The control is simple and direct and can effectively avoid overruns. | It may cut off content before critical information is available, resulting in loss of information. | Fast, low-cost search for models with limited context windows, but accept the risk of incomplete information. |
| RAG | The highest accuracy, pinpointing and providing the most relevant pieces of information, effectively reducing the "AI illusion". | Configuration and computation are relatively complex, with some requirements for Embedding models. | It is the most advanced and recommended way for serious queries where the quality of the answer is high. |
- uncompressed: Provide the original web content directly to the model.
- truncate: Hard truncation of extra-long content by setting the number of characters or Token count. This is a simple and brute-force control method, but the risk is that critical information may happen to be located in the truncated part.
- RAG: This option is not simply "compressed", but represents Search Enhanced Generation(Retrieval-Augmented Generation).
RAGis an advanced AI framework that first retrieves relevant information from an external knowledge base and then submits this information to the model along with the user's original question, guiding the model to generate a more accurate and reliable answer. Its working principle can be simplified as follows: it first utilizes Embedding model All the searched text chunks and user questions are converted into numeric vectors, and then the similarity is computed in the vector space to find out the most relevant text segments to the user question. Finally, only these highly relevant segments are provided as context to the larger model. This is akin to having the model take an "open-book" exam and turning directly to the pages with the correct answers, which makes efficient use of the most up-to-date data and significantly reduces the likelihood of the model "hallucinating" (i.e., making up facts). SelectionRAGAfter the compression method, you also need to configure theEmbeddingparameters such as model and embedding dimension.

Blacklists and Subscriptions
- blacklists: Supports the use of regular expressions to filter out search results for specific sites, e.g. blocking sites with low quality content.
- Blacklist Subscription: By subscribing to community-maintained blacklisted links (such as the
https://git.io/ublacklist), you can bulk block known low-quality or spammy websites without having to manually add them one by one.


on-the-spot training
Cherry Studio The connected searches fall into two categories: model built-in searches and third-party search services.
Model Built-in Search
Some model providers (e.g. OpenRouter) has integrated a built-in networking search capability for its models. This feature can be turned on directly in the model settings.

以 OpenRouter Free models offered Kimi K2 As an example, when the search is turned off, it fails to answer the current date; when it is turned on, it answers correctly and provides the source of the information. It is important to note that some models claim to support networking, but in practice are ineffective or do not work properly (e.g., certain GitHub Models)。
If you haven't found a suitable free big model API, you can choose one here:Free Big Model API List
Third-party search services
When the model does not have built-in search capabilities, a third-party search service becomes critical. But using it will face two main problems:
- Increased Token consumption
- Failure due to long search results exceeding model context limitations
Cherry Studio The third-party search process is divided into two stages:
Stage 1: Search Keyword Extraction and Content Acquisition
When a user sends a question, the system does not throw the original question directly to the search engine. Instead, it calls the big model once first, using an elaborate Prompt template that allows the model to analyze the user's intent and extract concise keywords that are best suited for use in machine searches. This approach is known asQuery Rewriting (Query Rewriting)that can greatly improve the accuracy of subsequent searches.

following Cherry Studio for keyword extraction Prompt Template. As you can see, it uses XML tags (such as<websearch>) to force the model to output structured content that can be parsed directly by the program, a common "structured Prompt" technique.
You are an AI question rephraser. Your role is to rephrase follow-up queries from a conversation into standalone queries that can be used by another LLM to retrieve information through web search.
**Use user's language to rephrase the question.**
Follow these guidelines:
1. If the question is a simple writing task, greeting (e.g., Hi, Hello, How are you), or does not require searching for information (unless the greeting contains a follow-up question), return 'not_needed' in the 'question' XML block. This indicates that no search is required.
2. If the user asks a question related to a specific URL, PDF, or webpage, include the links in the 'links' XML block and the question in the 'question' XML block. If the request is to summarize content from a URL or PDF, return 'summarize' in the 'question' XML block and include the relevant links in the 'links' XML block.
3. For websearch, You need extract keywords into 'question' XML block.
4. Always return the rephrased question inside the 'question' XML block. If there are no links in the follow-up question, do not insert a 'links' XML block in your response.
5. Always wrap the rephrased question in the appropriate XML blocks: use <websearch></websearch> for queries requiring real-time or external information. Ensure that the rephrased question is always contained within a <question></question> block inside the wrapper.
6. *use websearch to rephrase the question*
There are several examples attached for your reference inside the below 'examples' XML block.
<examples>
1. Follow up question: What is the capital of France
Rephrased question:`
<websearch>
<question>
Capital of France
</question>
</websearch>
`
2. Follow up question: Hi, how are you?
Rephrased question:`
<websearch>
<question>
not_needed
</question>
</websearch>
`
3. Follow up question: What is Docker?
Rephrased question: `
<websearch>
<question>
What is Docker
</question>
</websearch>
`
4. Follow up question: Can you tell me what is X from https://example.com
Rephrased question: `
<websearch>
<question>
What is X
</question>
<links>
https://example.com
</links>
</websearch>
`
5. Follow up question: Summarize the content from https://example1.com and https://example2.com
Rephrased question: `
<websearch>
<question>
summarize
</question>
<links>
https://example1.com
</links>
<links>
https://example2.com
</links>
</websearch>
`
6. Follow up question: Based on websearch, Which company had higher revenue in 2022, "Apple" or "Microsoft"?
Rephrased question: `
<websearch>
<question>
Apple's revenue in 2022
</question>
<question>
Microsoft's revenue in 2022
</question>
</websearch>
`
7. Follow up question: Based on knowledge, Fomula of Scaled Dot-Product Attention and Multi-Head Attention?
Rephrased question: `
<websearch>
<question>
not_needed
</question>
</websearch>
`
</examples>
Anything below is part of the actual conversation. Use the conversation history and the follow-up question to rephrase the follow-up question as a standalone question based on the guidelines shared above.
<conversation>
{chat_history}
</conversation>
**Use user's language to rephrase the question.**
Follow up question: {question}
Rephrased question:
Stage 2: Integrating information and generating responses
The system takes the web content obtained in the first stage and "compresses" it, integrates it with the user's original question, and sends it again to the model, which generates the final answer based on this real-time information.

This two-stage process explains the increase in Token consumption: one API call for keyword extraction and one API call for final answer generation. The total cost is approximately equal to the cost of two separate conversations, and the input of the second conversation also contains a large number of web search results.
That's why. "Compression method" Settings are critical. Select "Cut off." 或 "RAG" It is to address this issue.

Practice has found that the choice of search service provider significantly affects the failure rate. The use of Google、Baidu When traditional search engines such as these return full, unprocessed HTML pages, they are prone to overruns even when the model context window is large. Instead of using Tavily 或 Exa These types of service providers, which are designed for AI, have a much lower failure rate because they return pre-processed data that is cleaner, more concise, and naturally suited for model processing.
For example, when the search results are set to 20, the compression method is "no compression", and a model with a small context window (e.g., 8,000 tokens) is used, the probability of failure of a networked search increases significantly.

Recommendations for use
Tested.OpenRouter and Google's Gemini Provides a good experience with built-in networked search. If you need to use a third-party search service, follow these recommendations to ensure stability and efficiency:
- Prioritize the use of the model's built-in search function: If the model itself supports it, this is the simplest and most straightforward way to do it.
- Choose a search service designed for AI: Use
Tavily、Exaservice providers such asGoogle或Baidu. They provide cleaner, more relevant results, reducing Token consumption and the risk of processing failures. - Rationalization of search parameters: set carefully according to the size of the context window of the model used Number of results 和 Compression method(Highly recommended when quality is important)
RAG) to avoid search failures due to content overruns.

































