



ARC-Hunyuan-Video-7B is an open source multimodal model developed by Tencent's ARC Lab that focuses on understanding user-generated short video content. It provides in-depth structured analysis by integrating visual, audio and textual information of videos. The model can handle complex visual elements, high-density audio information and fast-paced short videos, and is suitable for scenarios such as video search, content recommendation and video summarization. The model is scaled with 7B parameters and is trained through multiple phases, including pre-training, instruction fine-tuning, and reinforcement learning, to ensure efficient inference and high-quality output. Users can access the code and model weights via GitHub for easy deployment to production environments.
Function List
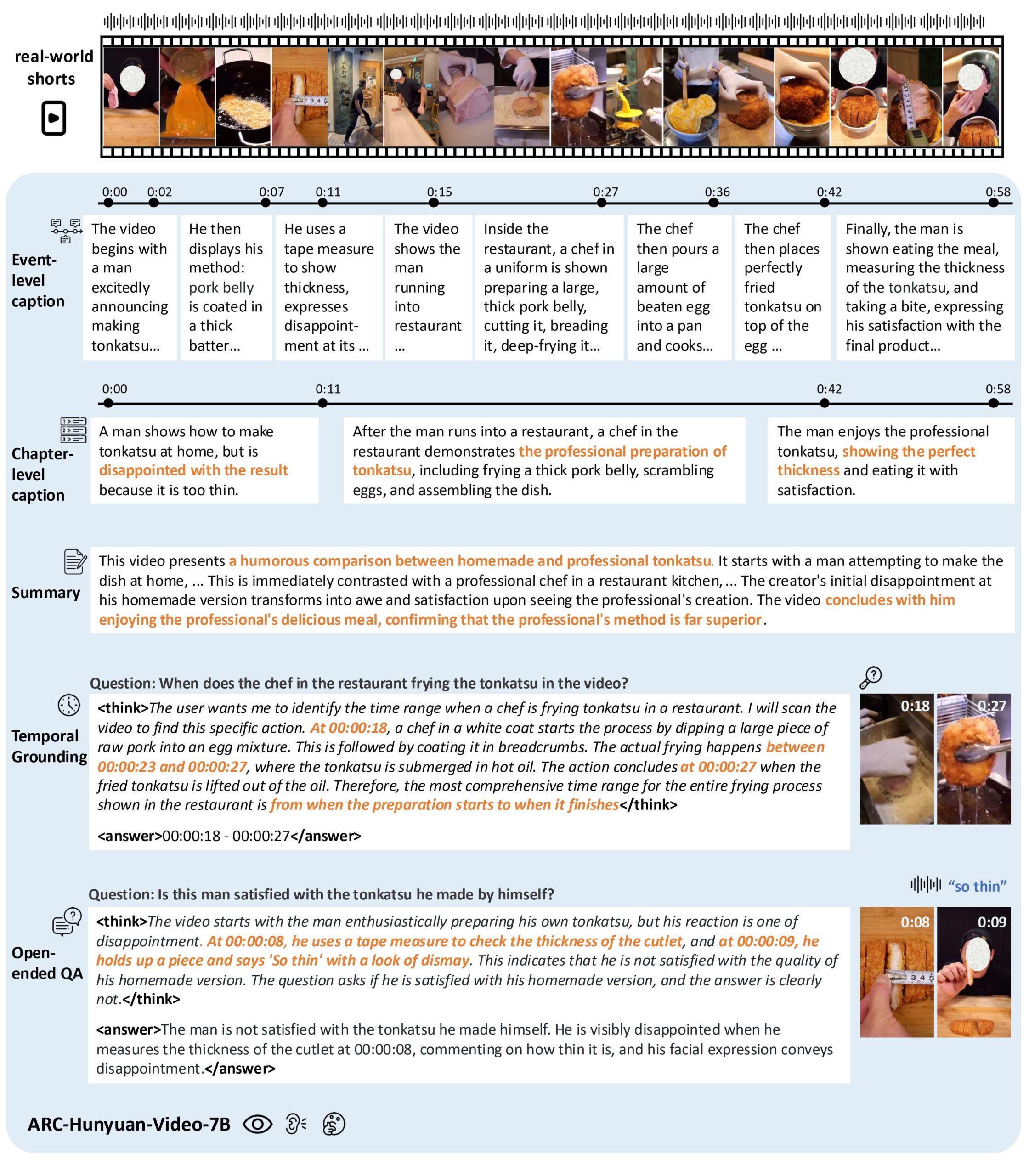
- Video content comprehension: analyze visual, audio and text of short videos to extract core information and emotional expressions.
- Timestamp annotation: support multi-granularity timestamp video description, accurately label the event time.
- Video quiz: answer open-ended questions about the content of the video and understand the complex scenarios in the video.
- Time Location: Locate specific events or clips in a video, support video search and editing.
- Video Summary: Generate a concise summary of the video content, highlighting key information.
- Multi-language support: support for Chinese and English video content analysis, specially optimized for Chinese video processing.
- Efficient reasoning: support vLLM Accelerated, 1-minute video reasoning in 10 seconds.
Using Help
Installation process
To use ARC-Hunyuan-Video-7B, users need to clone the GitHub repository and configure the environment. Below are the detailed steps:
- clone warehouse:
git lfs install git clone https://github.com/TencentARC/ARC-Hunyuan-Video-7B cd ARC-Hunyuan-Video-7B - Installation of dependencies:
Ensure that Python 3.8+ and PyTorch 2.1.0+ (with CUDA 12.1 support) are installed on your system. Run the following command to install the necessary libraries:pip install -r requirements.txt - Download model weights:
The model weights are hosted at Hugging Face. users can download them with the following command:from huggingface_hub import hf_hub_download hf_hub_download(repo_id="TencentARC/ARC-Hunyuan-Video-7B", filename="model_weights.bin", repo_type="model")Or manually download it directly from Hugging Face and place it in the
experiments/pretrained_models/Catalog. - Install vLLM (optional):
To accelerate reasoning, it is recommended to install vLLM:pip install vllm - Verification Environment:
Run the test script provided by the repository to check that the environment is configured correctly:python test_setup.py
Usage
ARC-Hunyuan-Video-7B supports local operation and online API call. The following is the main function operation flow:
1. Video content understanding
Users can input a short video file (e.g., in MP4 format), and the model will analyze the visual, audio, and textual content of the video and output a structured description. For example, inputting a TikTok funny video, the model can extract the actions, dialogues and background music in the video and generate a detailed description of the event.
procedure:
- Prepare the video file by placing
data/input/Catalog. - Run the reasoning script:
python inference.py --video_path data/input/sample.mp4 --task content_understanding - The output is saved in the
output/A catalog, in JSON format, containing a detailed description of the video content.
2. Time-stamp annotation
The model supports generating timestamped descriptions for videos, suitable for applications that require precise event localization, such as video clips or search.
procedure:
- Use the following command to run timestamp labeling:
python inference.py --video_path data/input/sample.mp4 --task timestamp_captioning - Example output:
[ {"start_time": "00:01", "end_time": "00:03", "description": "人物A进入画面,微笑挥手"}, {"start_time": "00:04", "end_time": "00:06", "description": "背景音乐响起,人物A开始跳舞"} ]
3. Video quiz
Users can ask open-ended questions about the video, and the model combines visual and audio information to answer them. For example, "What are the characters doing in the video?" or "What emotion does the video express?"
procedure:
- Creating an Issue File
questions.jsonThe format is as follows:[ {"video": "sample.mp4", "question": "视频中的主要活动是什么?"} ] - Run the quiz script:
python inference.py --question_file questions.json --task video_qa - The output is in JSON format and contains the answer to the question.
4. Time orientation
The time locator function allows you to locate clips of specific events in a video. For example, find a clip of "people dancing".
procedure:
- Run the positioning script:
python inference.py --video_path data/input/sample.mp4 --task temporal_grounding --query "人物跳舞" - The output results in a time period, such as
00:04-00:06。
5. Video summary
The model generates a concise summary of the video content, highlighting the core message.
procedure:
- Run the summary script:
python inference.py --video_path data/input/sample.mp4 --task summarization - Example output:
视频展示了一位人物在公园跳舞,背景音乐欢快,传递了轻松愉快的情绪。
6. Online API use
Tencent ARC provides an online API that can be accessed via Hugging Face or official demos. Visit the demo page, upload a video or enter a question, and the model will return results in real time.
procedure:
- Visit Hugging Face's ARC-Hunyuan-Video-7B demo page.
- Problems uploading video files or typing.
- View output results and support downloading analyzed data in JSON format.
caveat
- video resolution: The online demo uses compressed resolution, which may affect performance. It is recommended to run it locally for best results.
- hardware requirement: NVIDIA H20 GPUs or higher are recommended to ensure inference speed.
- Language Support: The model is better optimized for Chinese videos and performs slightly worse for English videos.
application scenario
- Video Search
Users can search for specific events or content in a video by keywords, such as "cooking tutorials" or "funny clips" on a video platform. - Content Recommendation
The model analyzes the core information and emotions of the video to help the platform recommend content that matches the user's interests, such as recommending short videos with upbeat music. - video clip
Creators can utilize the timestamp annotation and time positioning features to quickly extract key clips from videos to create highlight clips. - Education and training
In instructional videos, the model can generate summaries or answer students' questions to help quickly understand the course content. - Social Media Analytics
Brands can analyze user-generated content on TikTok or WeChat to understand their audience's emotional responses and preferences.
QA
- What video formats does the model support?
Common formats such as MP4, AVI, MOV are supported, and it is recommended that the video duration be limited to 1-5 minutes for optimal performance. - How to optimize the speed of reasoning?
Use vLLM to accelerate inference and make sure the GPU supports CUDA 12.1. Reducing the video resolution also reduces the amount of computation. - Does it support long videos?
The model is mainly optimized for short videos (less than 5 minutes). Longer videos need to be processed in segments, and it is recommended to use preprocessing scripts to split the video. - Does the model support real-time processing?
Yes, when deployed with vLLM, 1-minute video inference takes only 10 seconds, making it suitable for real-time applications.






























