Going Small: How to Make a 0.6B Model Look Like a 235B Model with Model Distillation
Although Large Language Models (LLMs) are excellent, their high computational cost and slow inference speed are major barriers to practical application. An effective solution is Model Distillation: first generate high-quality annotated data using a powerful Teacher Model (Large Parameter Model), and then use this data to "teach" a smaller, more economical Student Model (Small Parameter Model). The data is then used to "teach" a smaller, more economical "student model" (small parameter model). In this way, the small model can achieve performance close to that of the large model on a given task.
In this paper, we will take the example of extracting logistics information (recipient, address, phone number) from text, and demonstrate in detail how to make a 0.6B parameterized Qwen3-0.6B model, the accuracy on the information extraction task improves from 14% to 98%, which is comparable to the effect of the larger model.
The comparison of the results before and after optimization is very visual:

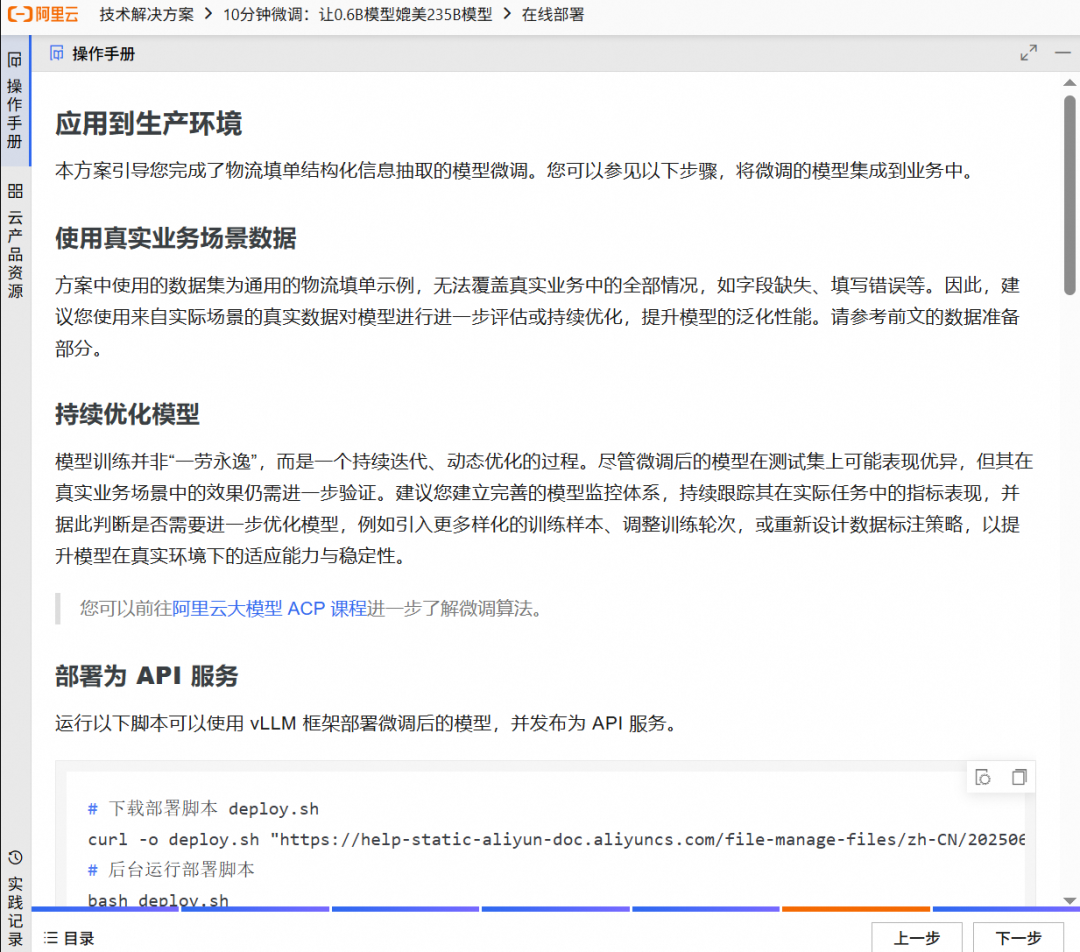
Program core processes
The whole process is divided into three key steps:
- Data preparation: A large model of 235B is used as a teacher model to process a batch of virtual address descriptions and generate structured JSON data as a high-quality training set. In actual business, real scene data should be used to achieve the best results.
- Model Tuning: Using the data generated in the previous step, the
Qwen3-0.6BThe model is fine-tuned. This process will use thems-swiftframework, which reduces complex fine-tuning operations to single-line commands. - Effectiveness Verification: Evaluate model performance before and after fine-tuning on an independent test set to quantify performance gains and ensure model stability and accuracy in production environments.
I. Preparing the computing environment
The large model fine-tuning needs to be equipped with GPU computing environment and properly install the GPU Drive,CUDA 和 cuDNN. Configuring these dependencies manually is not only tedious but also error prone. To simplify deployment, it is recommended to create the GPU When you select a cloud server instance with pre-installed GPU The driver is mirrored so that fine-tuning tasks can be started quickly.
This program can be experienced through free trial resources. Resources and data created during the trial period will be purged at the end of the trial. If you need to use it for a long time, you can refer to the manual creation guidelines in the official documentation.
- Create resources according to the page guide, the right side will show the creation progress in real time.
- Once created, log in via the Remote Connect feature to the
GPUCloud servers.
Click on the "Remote Connect" button and log in with the provided credentials.
II. Downloading and fine-tuning the model
Through the Magic Match community (ModelScope) provides the ms-swift framework that can dramatically simplify the complex process of model fine-tuning.
1. Installation of dependencies
This program relies on two core components:
ms-swift: A high-performance training framework provided by the Magic Hitch community that integrates model downloading, fine-tuning, and weight merging.vllm:: A framework for deployment and inference services that supports high-performance inference, facilitates validation of model effects and generatesAPIFor business calls.
Run the following command in the terminal to install the dependencies (takes about 5 minutes):
pip3 install vllm==0.9.0.1 ms-swift==3.5.0
2. Implementation model fine-tuning
Run the following script to automate the entire process of model download, data preparation, model fine-tuning and weight merging.
# 进入 /root 目录
cd /root && \
# 下载微调脚本 sft.sh
curl -f -o sft.sh "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250623/cggwpz/sft.sh" && \
# 执行微调脚本
bash sft.sh
The fine-tuning process takes about 10 minutes.sft.sh The core commands in the script are as follows:
swift sft \
--model Qwen/Qwen3-0.6B \
--train_type lora \
--dataset 'train.jsonl' \
--torch_dtype bfloat16 \
--num_train_epochs 10 \
--per_device_train_batch_size 20 \
--per_device_eval_batch_size 20 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--save_steps 1 \
--save_total_limit 2 \
--logging_steps 2 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Some of the key parameters are described here:
--train_type lora: Specify the use of LoRA (Low-Rank Adaptation) method for fine-tuning. This is a parameter-efficient fine-tuning method, which trains only a small number of added weights compared to full fine-tuning, greatly reducing the computational resource requirements.--lora_rank:: The rank of the LoRA matrix. The larger the rank, the better the model fits complex tasks, but too large may lead to overfitting.--lora_alpha: the scaling factor of LoRA, withlearning_rateSimilarly, for adjusting the magnitude of weight updates.--num_train_epochs: Training rounds. Determines how deep the model learns the data.
During the training process, the terminal prints the change in loss (loss) of the model on the training and validation sets in real time.

When the following output is seen, it indicates that model fine-tuning and weight merging have been successfully completed:
✓ swift export 命令执行成功
检查合并结果...
✓ 合并目录创建成功: output/v0-xxx-xxx/checkpoint-50-merged
✓ LoRA权重合并完成!
合并后的模型路径: output/v0-xxx-xxx/checkpoint-50-merged
Once the fine-tuning is complete, the output/v0-xxx-xxx/images directory to find the train_loss.png 和 eval_loss.png Two charts which visualize the training state of the model.
| train_loss (training set loss) | eval_loss (validation set loss) |
|---|---|
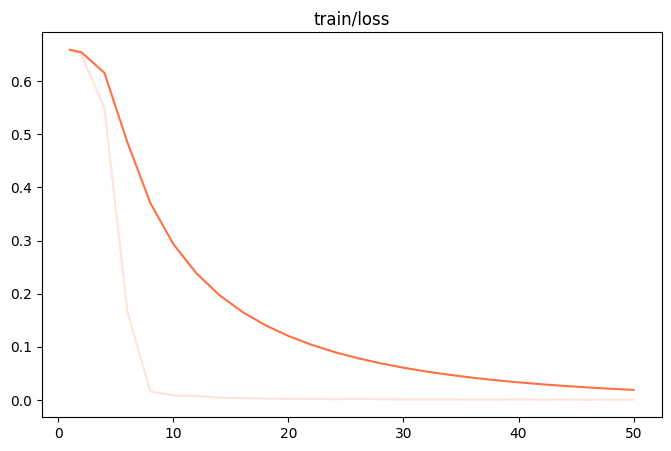 |
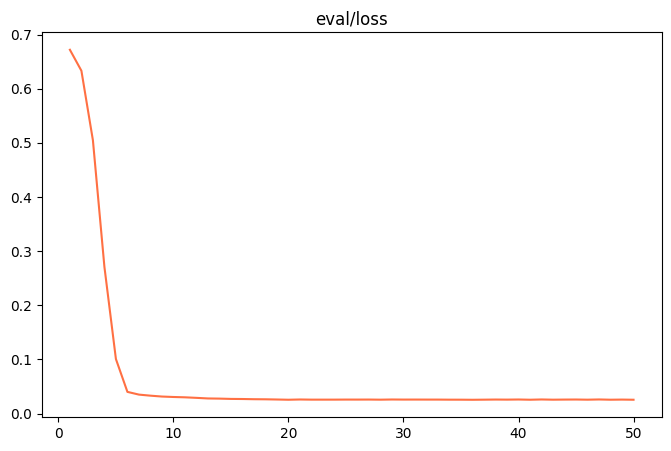 |
- poor fitIf
train_loss和eval_lossAt the end of the workout there is still a significant downward trend, try increasing thenum_train_epochs或lora_rank。 - overfittingIf
train_lossContinued decline, buteval_lossInstead, it starts to rise, indicating that the model has overlearned the training data and should be reducednum_train_epochs或lora_rank。 - good fit: When both curves level off, it indicates that the model training has reached an ideal state.
III. Validating model effects
A systematic review is an essential part of the process before deploying to a production environment.
1. Preparation of test data
The test data should be in the same format as the training data and must be completely new and unseen by the model to assess its generalization ability.
cd /root && \
# 下载测试数据 test.jsonl
curl -o test.jsonl "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250610/mhxmdw/test_with_system.jsonl"
A sample of test data is shown below:
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "电话:23204753945:大理市大理市人民路25号 大理古城国际酒店 3号楼:收件者:段丽娟"}, {"role": "assistant", "content": "{\"province\": \"云南省\", \"city\": \"大理市\", ...}"}]}
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "天津市河西区珠江道21号金泰大厦3层 , 接收人慕容修远 , MOBILE:22323185576"}, {"role": "assistant", "content": "{\"province\": \"天津市\", \"city\": \"天津市\", ...}"}]}
2. Design of evaluation indicators
The evaluation criteria need to be closely aligned with the business objectives. In this example, not only is it important to determine whether the output is a legitimate JSONWe'll have to compare them one by one. JSON Each Key-Value pair in the
3. Evaluation of initial model effects
First, in the unfine-tuned Qwen3-0.6B model was tested. Even with a well-designed and detailed prompt word (Prompt), its accuracy on the 400 test samples was only 14%。
所有预测完成! 结果已保存到 predicted_labels_without_sft.jsonl
样本数: 400 条
响应正确: 56 条
响应错误: 344 条
评估脚本运行完成
4. Validation of fine-tuned models
Next, the fine-tuned model was evaluated using the same test set. A significant change is that it is now possible to achieve excellent performance with a very concise cue word, as task-specific knowledge is "baked" into the model parameters, eliminating the need for complex instructions.
The short version of the cue word:
你是一个专业的信息抽取助手,专门负责从中文文本中提取收件人的JSON信息,包含的Key有province(省份)、city(城市名称)、district(区县名称)、specific_location(街道、门牌号、小区、楼栋等详细信息)、name(收件人姓名)、phone(联系电话)
After executing the evaluation script, the results show that the accuracy of the fine-tuned model reaches the 98%, a qualitative leap has been achieved.
所有预测完成! 结果已保存到 predicted_labels.jsonl
样本数: 400 条
响应正确: 392 条
响应错误: 8 条
评估脚本运行完成
This result proves that model distillation and LoRA Fine-tuning is a highly cost-effective solution that makes it possible to apply small models to specific domains, clearing the cost and efficiency hurdles for AI technology to scale.